前回の作業でM5StickV用のMicroPython(MaixPy)のセルフ開発環境が「整った」ので、早速例題をやってみたいと思います。micro:bit上のMicroPythonでは「やる気も起きなかった」計算量やらメモリ量やら必要なもの。当然ながら時間計測もしたいです。ドキュメント読んでいるうちにデコレータ使って時間計測している技を発見。早速使わせていただきます。
※「MicroPython的午睡」投稿順 Indexはこちら
(今回使用の全ソースは末尾に)
micro:bitとM5StickVを比べてしまうと同じMicroPython環境とはいえハードの違いに起因する差は歴然です。最大でも30Kバイトのストレージ上にスクリプトを格納し、RAM16Kバイトの上で動作させなければならないmicro:bitと、トータルでは8Mバイトに達するRAMを搭載し、SDカード(手元の装置には8Gバイト品使用中)にスクリプトを格納できるM5StickVではメモリ容量の点が大きく異なります。また、ハードウエアで浮動小数点を計算できないmicro:bit(16MHz)に対し、倍精度浮動小数点演算器を搭載するM5StickV(400MHz)は演算能力的にも大違い。そこで「計算できるようになった」ということで、今回は、行列積を計算してみたいと思います。サイズがでかくなるとメモリも計算回数も鰻登り。
ulabモジュール
さて今回はMicroPython用のnumpy類似モジュール、ulabを使わせていただきます。ご本家 numpy はパソコン上のPythonでは何時もお世話になりっぱなしです。Pythonで数値配列使うときの定番中の定番。そしてM5StickV用のMicroPythonであるMaixPyにはnumpyのサブセット的な実装であるulabが使えるようになっています。ただ、以下のMaixPyのAPIリファレンスの中には記述が無いです。
しかし、ulabには充実した以下の解説文書があるのでありがたいです。
ただし Genericなulabの実装とM5StickV用のulabの実装には微妙な差異があるように見えます。そのあたり注意は必要そうです。ま、私なんどが使いそうな範囲では numpy みたいに使える感じです。
“timeit” デコレータ
この手のライブラリモジュールを使う目的は、
- 計算時間を短くしたい
- 消費メモリ量を必要最小限に抑えたい
の2点でしょう。1の目的からはチューニングのための時間計測が必須、と思います。このulabの文書を読んでいて デコレータ使って時間計測しているところに出くわしました。良い感じです。早速真似させてもらいました。このデコレータのオリジナルは、MicroPythonの以下のドキュメントの中の” Identfying the slowest section of code”という部分だと思います。
任意の関数の計測をできる計測関数を定義しておき、計測対象関数に計測関数をデコレータとして被せるというスタイルです。対象関数の前に1行デコレータを記述するだけで速度の計測ができます。上のURLでは他と被らない名前でしたが、ulabの文書では計測関数に timeit と言う名をつけていてカッコ良かったのでそのままパクらせていただきました。すみません。なおパソコン上のPythonで使える 標準的なtimeitモジュールとは異なるものです。一応そのソースも最末尾に掲げました。それよりこのデコレータのコードを読んで、私はPythonのデコレータの仕組みをようやくホントに理解できた気がします。良い副作用かな。
行列積の計算
M5StickVのK210はニューラルネットワーク用にKPUという名の専用プロセッサを搭載しています。AI系アルゴリズムの裏で動いている行列演算的な処理はそちらが担当。しかしそちらでは倍精度浮動小数点演算のような「普通の計算」はできないので、CPU(RISC-V)側のFPUを使っている筈。行列積は掛け算と足し算が出てくるだけなのでシンプル。10x10行列同士の積で乗算1000回、加算900回が必要。
テストに使ったスクリプトを末尾に掲げました。やはりulabと「普通のPythonでの計算の仕方」で速度の比較をやらないとカッコがつきません。ただ、今となっては numpy とか ulab のようなライブラリにお任せするのが普通で、ベタなPythonで書いたりしない。。。そこで僭越ながら通常のListを使って2つの行列の積を計算する関数を自作いたしました。これと ulab(呼び出すときは numpy の伝統に則り np と言う名で呼ぶ)np.dot 関数を比べます。
- 最初にちゃんと計算していることを確認するために2×2行列の掛け算、[[1,2],[3,4]]に単位行列かけてみる。時間使うだけでお答えは元の行列のまま
- 次に計算速度を見るために10×10行列に乱数データを突っ込んだもので比較する。両方の関数が同じ結果を返せば、まあOKかな。
こんな段取りです。実行した様子は下のとおり。(昨日作成のシェルもどき使っております)
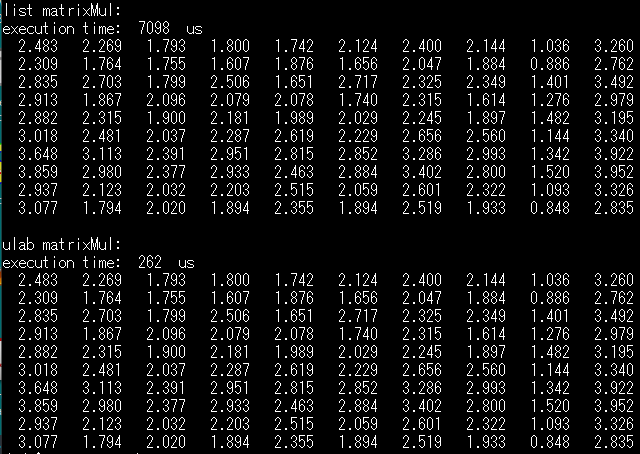
Start uSHELL(in boot.py): /sd $ run bench001.py list matrixMul 2x2 : execution time: 114 us 1.000 2.000 3.000 4.000 ulab matrixMul 2x2 : execution time: 26 us 1.000 2.000 3.000 4.000 x -------------- 0.575 0.119 0.964 0.623 0.737 0.448 0.092 0.314 0.858 0.142 0.657 0.093 0.748 0.285 0.449 0.400 0.482 0.291 0.331 0.443 0.019 0.891 0.725 0.723 0.947 0.554 0.225 0.243 0.627 0.435 0.800 0.187 0.150 0.105 0.603 0.162 0.799 0.647 0.605 0.286 0.197 0.474 0.566 0.549 0.275 0.465 0.505 0.481 0.843 0.609 0.881 0.650 0.868 0.621 0.345 0.498 0.634 0.194 0.031 0.770 0.803 0.855 0.747 0.931 0.680 0.756 0.457 0.564 0.137 0.678 0.580 0.762 0.857 0.946 0.663 0.879 0.365 0.955 0.532 0.162 0.631 0.351 0.897 0.454 0.316 0.289 0.787 0.600 0.035 0.726 0.925 0.367 0.773 0.107 0.172 0.831 0.186 0.858 0.194 0.388 y -------------- 0.732 0.444 0.528 0.291 0.958 0.235 0.800 0.428 0.016 0.522 0.918 0.538 0.099 0.792 0.346 0.792 0.356 0.230 0.489 0.480 0.370 0.196 0.177 0.102 0.332 0.548 0.431 0.627 0.059 0.836 0.080 0.823 0.027 0.403 0.273 0.237 0.667 0.649 0.112 0.348 0.380 0.611 0.525 0.635 0.083 0.847 0.476 0.654 0.087 0.976 0.496 0.246 0.497 0.155 0.004 0.125 0.164 0.385 0.194 0.126 0.740 0.227 0.580 0.508 0.332 0.127 0.361 0.372 0.679 0.624 0.981 0.262 0.515 0.703 0.659 0.491 0.882 0.228 0.142 0.710 0.706 0.570 0.451 0.360 0.265 0.361 0.328 0.035 0.663 0.816 0.449 0.666 0.553 0.532 0.928 0.445 0.357 0.504 0.112 0.867 list matrixMul: execution time: 7098 us 2.483 2.269 1.793 1.800 1.742 2.124 2.400 2.144 1.036 3.260 2.309 1.764 1.755 1.607 1.876 1.656 2.047 1.884 0.886 2.762 2.835 2.703 1.799 2.506 1.651 2.717 2.325 2.349 1.401 3.492 2.913 1.867 2.096 2.079 2.078 1.740 2.315 1.614 1.276 2.979 2.882 2.315 1.900 2.181 1.989 2.029 2.245 1.897 1.482 3.195 3.018 2.481 2.037 2.287 2.619 2.229 2.656 2.560 1.144 3.340 3.648 3.113 2.391 2.951 2.815 2.852 3.286 2.993 1.342 3.922 3.859 2.980 2.377 2.933 2.463 2.884 3.402 2.800 1.520 3.952 2.937 2.123 2.032 2.203 2.515 2.059 2.601 2.322 1.093 3.326 3.077 1.794 2.020 1.894 2.355 1.894 2.519 1.933 0.848 2.835 ulab matrixMul: execution time: 262 us 2.483 2.269 1.793 1.800 1.742 2.124 2.400 2.144 1.036 3.260 2.309 1.764 1.755 1.607 1.876 1.656 2.047 1.884 0.886 2.762 2.835 2.703 1.799 2.506 1.651 2.717 2.325 2.349 1.401 3.492 2.913 1.867 2.096 2.079 2.078 1.740 2.315 1.614 1.276 2.979 2.882 2.315 1.900 2.181 1.989 2.029 2.245 1.897 1.482 3.195 3.018 2.481 2.037 2.287 2.619 2.229 2.656 2.560 1.144 3.340 3.648 3.113 2.391 2.951 2.815 2.852 3.286 2.993 1.342 3.922 3.859 2.980 2.377 2.933 2.463 2.884 3.402 2.800 1.520 3.952 2.937 2.123 2.032 2.203 2.515 2.059 2.601 2.322 1.093 3.326 3.077 1.794 2.020 1.894 2.355 1.894 2.519 1.933 0.848 2.835
ちゃんと正しく計算しているようです。比較対象が拙い私の関数実装なのを割り引いても、約27倍速い結果であります。MicroPython版の numpy を標榜することだけのことはありそう。
最後に先ほどの The ulab book から1箇所引用させていただきます。なぜ ulab のようなものが必要なのか、その意義。
On a microcontroller, the data volume is probably small, but it might lead to catastrophic system failure, if these data are not processed in time,
MicroPython的午睡(7) M5StickV、MicroPython再々復活 へ戻る
MicroPython的午睡(9) ulabで連立方程式を解く、機種固有実装の蹉跌 へ進む
行列積のサンプルプログラム(要 timeit.py)
from timeit import timeit
import ulab as np
import random
@timeit
def list_matrixMul(a, b, ra, ca, cb):
result = []
for _i in range(ra):
result.append([0.0] * cb)
for rIdx in range(ra):
for cIdx in range(cb):
for wIdx in range(ca):
result[rIdx][cIdx] += a[rIdx][wIdx] * b[wIdx][cIdx]
return result
@timeit
def ulab_matrixMul(a, b):
return np.dot(a, b)
def printMatrix(arg):
for raw in arg:
for col in raw:
print("{0:7.3f} ".format(col), end="")
print()
a = [[1.0, 2.0],[3.0, 4.0]]
b = [[1.0, 0.0],[0.0, 1.0]]
na = np.array(a)
nb = np.array(b)
print('list matrixMul 2x2 :')
printMatrix( list_matrixMul(a,b,2,2,2) )
print()
print('ulab matrixMul 2x2 :')
printMatrix( ulab_matrixMul(na,nb) )
print()
xMax = 10
yMax = 10
x = []
y = []
for i in range(xMax):
wx = []
wy = []
for j in range(yMax):
wx.append(random.random())
wy.append(random.random())
x.append(wx)
y.append(wy)
print("x --------------")
printMatrix( x )
print("y --------------")
printMatrix( y )
print()
nx = np.array(x)
ny = np.array(y)
print('list matrixMul:')
printMatrix( list_matrixMul(x,y,xMax,yMax,xMax) )
print()
print('ulab matrixMul:')
printMatrix( ulab_matrixMul(nx,ny) )
timeit.py
import utime
def timeit(f, *args, **kwargs):
func_name = str(f).split(' ')[1]
def new_func(*args, **kwargs):
t = utime.ticks_us()
result = f(*args, **kwargs)
print('execution time: ', utime.ticks_diff(utime.ticks_us(), t), ' us')
return result
return new_func