分けも分からずR言語のサンプルデータセットに端から飛び込む、やっつけでご乱心な第4回はCO2です。CO2と言うからには二酸化炭素みたい。話題のトピックで嬉い。しかし知らないお言葉が多数登場、端から調べていても埒があかず。まあ、coplotが良いものだというのは何となくわかったので良しとするか。
※「データのお砂場」投稿順Indexはこちら
CO2
今回のデータセット CO2 についての情報は以下に。
CO2 Carbon Dioxide Uptake in Grass Plants
今まで見てきた4例の中では、一番情報量が充実しているような気がします。詳しくは上記のURL辿ってご覧ください。カナダ・ケベック州と米ミシシッピ州でのイネ科植物の二酸化炭素の取り込み量に関するデータです。両州のデータとも6種あり、それぞれのうち3種類はチルドとあるので、冷やしているみたいです。冷やせばきっと取り込まなくなるんだろうなあ。このデータ見ただけでもCO2の吸収量などというものは、一筋縄でいかなそうな雰囲気がありあり(個人の感想です。)
データをロードしてみる
まずは何時もの通りデータをロードしてその形式を調べてみます。こんな感じ。

しかし、data()の行で何時もとちょっと違う雰囲気なことが分かりましたよ。以下をご覧ください。
登場しました、Promise。お約束、遅延評価であります。R言語というのは遅延評価な言語らしいデス。以下の日本語ドキュメント
の「2.1.8 Promise オブジェクト」から1か所引用させていただきます。
予約オブジェクトは R の遅延評価機構の一部である。~中略~ その引数がアクセスされるまで、その予約に伴ういかなる値も存在しない。引数がアクセスされると、保管された表現式が保管された環境中で評価され、そして結果が返される。
環境と一緒に保管されとる、というのがミソなのでしょう。実際、data()の後、class()と打った瞬間に、実データが下のように現れました。
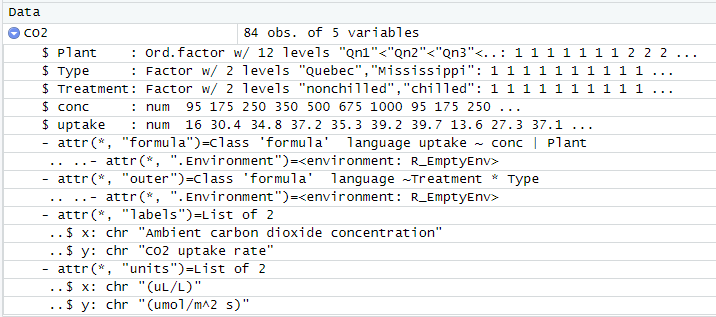 ほえほえ、遅延評価の威力すさまじ。
ほえほえ、遅延評価の威力すさまじ。
しかしclass()が返してくるうち、data.frameは分かるけれど他のヤツは何??
nfnGroupedDataって何?
まず最初の1個について調べてみたです。発見しました。以下のページで。
[R] newbie question on str output
まあ、newbieな私としては、ありがちな質問だったのかもです。ここの解答から核心部分のみ引用させていただきます。Dieter様ありがとう。
So better consider CO2 a simple data frame of example data, with historical decoration. I suggest you start with
CO2 <- as.data.frame(CO2)
Dieter
「歴史的装飾」とな。まあ、何も考えず素直に処理してしまいます。
nlme?
さらにこのデータセットで気になったのが nlme なるもの。ちらちら登場してきます。その名のパッケージあり、その資料は以下に。
nlme: Linear and Nonlinear Mixed Effects Models
Fit and compare Gaussian linear and nonlinear mixed-effects models.
何やら難しげなモデル。まあ Gaussian=正規分布 と解釈していいみたいなので、正規分布がベースにあるみたいですが、恐ろしいデス。上記のページから立派なマニュアルへのリンクもありました。
上記のマニュアル、338ページあります。とても読めません。。。
探したら以下に日本語の分かり易い(個人の感想です)ページがありました。ありがたい。
データ化学工学研究室(金子研究室)@明治大学 理工学部 応用化学科
混合ガウスモデル (Gaussian Mixture Model, GMM)
上記のページには、pdfとパワポのファイルありです。こちらなら読める分量です(ちゃんと読んでないけど。)GMMでCO2データを解析するときになったら読みます(何時のことやら。)
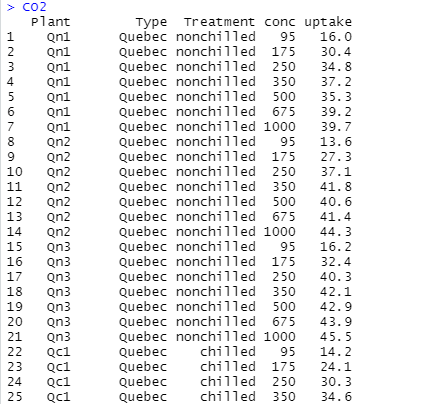
ようやく生データを眺める
ようやく生データを見てみます。ダンプすればこんな感じ。いままでいろいろブツブツ言ってきた割にはシンプル。条件は、ケベックか/ミネソタじゃないミシシッピか、冷やしてないか/冷やしたか、そして植物の種類?がそれぞれに3種毎。2x2x3=12通りのデータです。concが二酸化炭素濃度(単位 mL/L)、updakeが吸収量でumol/m^2 secとな。この数字みると極めて実験室的な雰囲気がします。1000mL/Lなんていうのはトンデモない高濃度?
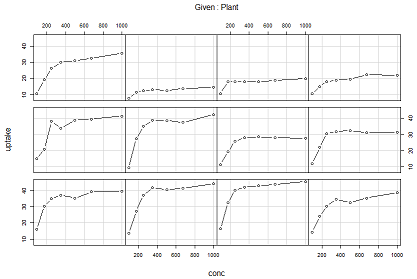
さて、生データのままでは、なんだかよく分からないのでプロットしたいです。このデータセットの処理例では、coplotというのを使っているのです。coplotのマニュアルは以下に。
処理例そのままコピペでやってみました。こんな感じ。
![]()
結果は以下です。なかなかカッコいいです。
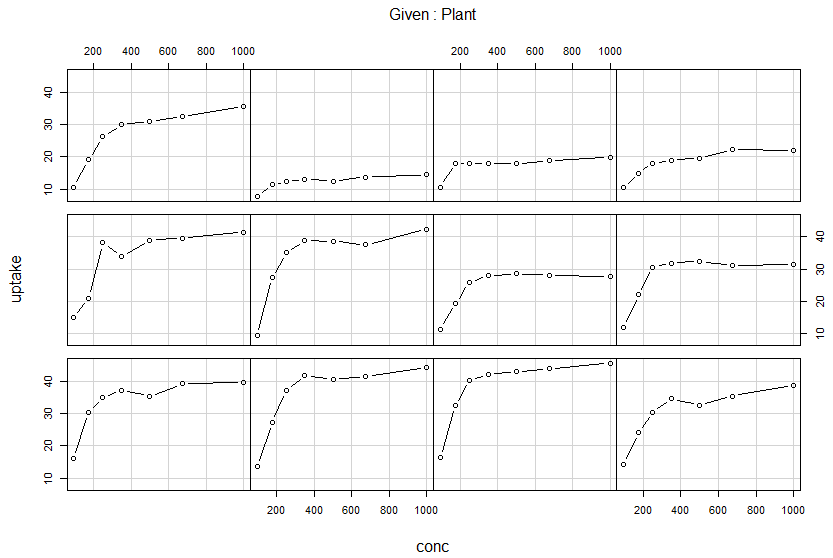
なお、12のサブプロットが上記の12のケースに対応することが予想されるのですが、上のグラフからはどういう順番だか分からないです。調べてみたところ、左下から右上への順番で、以下のようでした。
Qn1, Qn2, Qn3, Qc1, Qc3, Qc2, Mn3, Mn2, Mn1, Mc2, Mc3, Mc1
どういうロジックでこの順番になるんだろ?まだ理解できないでおります。
非線形回帰分析
さてプロットの後は、前回でも出てきた非線形回帰分析です。前回はビビリながらも、結局、RC回路への電荷チャージと同じ、イクスポーネンシャル・カーブじゃん、ということで何とかなった(ホントか?)です。今回は万歳三唱。
今回の非線形回帰分析につかうモデルは以下です。ご興味のある方はお読みくだされや。
SSasymp Self-Starting Nls Asymptotic Regression Model
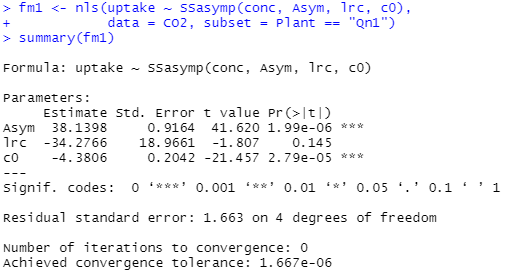
既に疲れたので、モデルの理解などはさっさと諦め、計算のみ例にそって実施してみます。まずは最初のケース一つに帰着させて、「バラツキ?」を見ているらしい計算例。
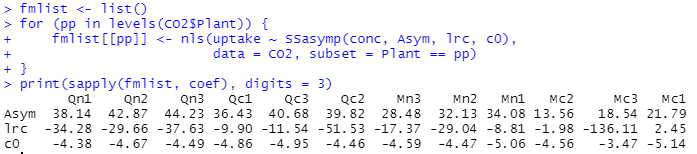
次は、12のケース毎にモデルにフィットさせた場合の各ケースのパラメータ。
ヤッツケでご乱心。