少し間が空いた期間に方針変更いたしました。最初はよそ様の書かれた立派なコードを読むに限ると。いくらTOYデータセットと言えども、いろいろな処理が可能なわけで知識の無い私があがくより、まずはお手本を読もうと。データセットはIrisのままですが、処理はClassificationではなくClusteringです。
今回のお手本
今回お手本にさせていただいたのが以下のページです。K-means法でIrisデータセットをクラスタリングしてみるもの。知識不足の私でも K-means法はホンワカ分かります。平均点から近いものをまとめていくのだよね。
まずは、サンプルプログラムをそのまま実行し、そのコード中で「キモ」な部分を読んで行く、という目論見であります。
方針変更のついでに実行環境も、素のJupyter-Labから、VScode上のJupyter-notebookに変更しました。こちらの方がサンプルの実行が楽。ついでに呼び出しているPythonモジュールなど、アチコチ飛び回って読むのも楽。
上記サイトからダウンロードしたサンプルプログラムを起動したところが以下に。
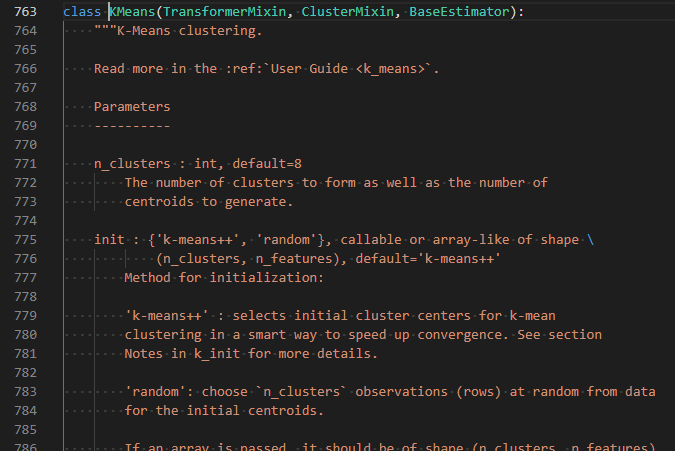
エディタ環境なので、コンテキストメニューから「定義に移動」など選択すれば、即座に該当のファイルへ飛べます。KMeansのクラスをインスタンス化しているコードにカーソルを合わせて「跳べば」(F12キー一発)、今回、肝心のKMeansクラスの定義へと飛び込むことも簡単。
サンプルプログラム
サンプルプログラムを動かすと、3次元プロットが4枚生成されるようになっていました。内訳は以下のとおり。
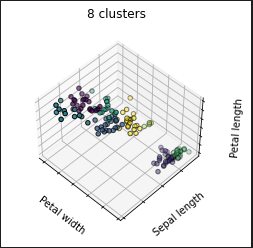
- 8クラスタ
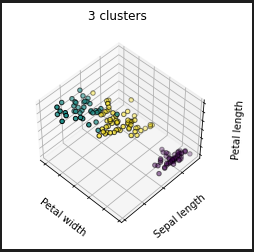
- 3クラスタ
- 3クラスタの初期値がBAD
- Ground Truth (実データと言ったら良いですかね?)
K-Means法は、何個のClusterに分けるのかは外から与えると。ここではデータセットは既知であります。3種類のIris(アヤメの花)についてのデータです。事前知識からするとIrisを8個のクラスタに分けるのは意味なしな感じですが、知らなければ何個にするのかで結果が異なって見える筈。最初の例はそこを確かめているのだと思われます。
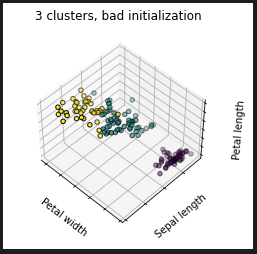
2番目の3クラスタがデータセット上、一番座りが良い筈の指定でしょう。それに対して、「3クラスタの初期値がBAD」は、初期値(クラスタの中心点)の決め方に大きく依存するK-Means法なので、初期値の決め方を変えたらどうなるか見ているみたい。
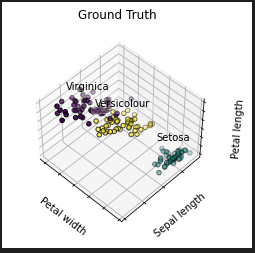
最後のGround Truthは、実データを同形式の3次元プロットに落としたもの。クラスタリングの結果と比べるためのものと思われます。
さて、キモと思われる部分が以下です。

上の3つの条件にあわせて、KMeansのインスタンスをセットしているところ。上二つについては初期化の方法が書いてないです。省略時のデフォルトはKMeans++法で決める、ということだそうで。それに対してBAD言われてしまっている最後のケースでは random だと。それでBADなのね。成り行きということは、やる度に変わるかも知れんということですな。
8クラスタ
最初の結果は、テキトーにともかく8グループに小分けにしてみましたという感じっすね。
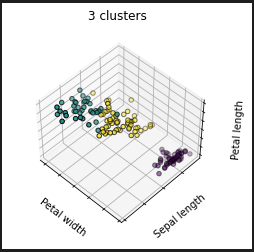
3クラスタと3クラスタBAD
3クラスタは、後に出てくる実データと見比べてもそれほど違いがない感じです。とくにBADとか言われている初期値ランダムに選んでいるものでもそれほど違いが無いのでないですか?素人目にはそう見えます。ただ、毎回結果が変わるかも知れんといわれるとね。
BADの時(の一例)が以下に。
実データ
Irisデータセットの中に花の種類データのフィールドが含まれているのでそれをそのままプロットしたものが以下ですな。前回見たとおりSetosaという種類は明らかに違うのだけれど、他の2種はどうやってみても被る部分があることはやってみて知っています。
さきほどの3クラスタの結果は完全一致でないですが、結構雰囲気でているんじゃ。評価の仕方など知らんけど。
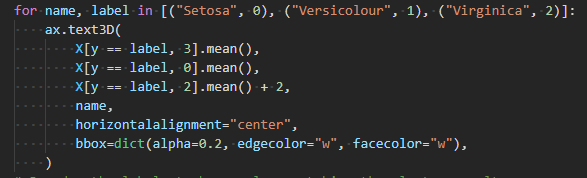
さて、実データのプロットのところを眺めていて、ちょっと真似したいテクを発見。花の御名前のテキストラベルをプロットしているところです。花名のラベルでデータを検索して、X,Y,Zの値の平均値(Zだけ+2して上にくるようにしている)からテキストの座標を決めているところ。スマートですな。KMeansでなくても平均値は使い道があるのね。
最後に疑問が
Irisデータセット、Sepal(がく片)とPetal(花弁)それぞれWidth,Lengthあるので合計4データで1組であることは前回見て来たとおりです。むむ、今回の処理ではSepal Width使ってないですな。3次元プロットで見せたかったので、1個除いただけのような気もしますが、何で Sepal Widthを除いたの?という疑問もあり。プログラムのソースに現れない「ヒューリスティックス」がある?