前回は演習用の人工データでしたが、今回は自然現象の観測データです。米国カリフォルニア州内で発生した23個の地震のピーク加速度データです。古いデータのようですが比較的デカイ地震ばかり。震源までの距離とピーク加速度の間に関係性を見出すための練習データに見えます。しかし多くの日本人は知っています。地震は一筋縄ではいかねーと。
※「データのお砂場」投稿順Indexはこちら
R言語所蔵のサンプルデータセットをABC順(大文字先)で端から眺めております。今回のデータセットは「減衰」みたいなタイトルが付けられていますが、震源までの距離とピーク加速度のデータです。大きくみれば距離が遠くなれば地震動は「減衰」し、ピーク加速度は低下すると予想できます。そのような関係を確かめる意図のデータだと思います。データセットの解説ページが以下に。
The Joyner-Boore Attenuation Data
182の観測データ、各データは5変数、が含まれています。
-
- event 地震番号、23個の地震に番号が振られている
- mag 各地震のモーメント・マグニチュード
- station 地震観測点の番号
- dist 震源から観測点までの距離[km]
- accel ピーク加速度[g]
最近は、日本でも モーメント・マグニチュード(Mw) を使うのがお馴染みになってきました。ご本家、気象庁様の解説ページのリンクは以下に。
まずは生データから
以下のように、生データをロードして眺めてみました。データ形式は単純な data.frameでした。head()で先頭部分をみてみます。モーメントマグニチュードをみると7以上の強烈なやつが並んでました。つい、最大どこまでと興味本位でmax()みると7.7でした。カリフォルニアも地震は多いデス。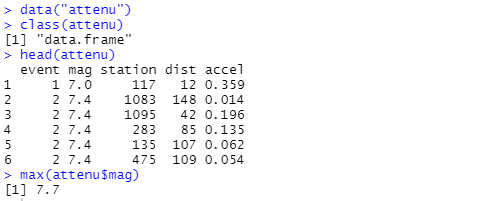
ともあれ、生データの雰囲気をみるため、丸ごとplot関数に渡してみました。Rの場合、継承した関数に適当に渡してくれるのでお楽。
plot(attenu)
結局、coplot のグラフが結果に返ってきます。こんな感じ。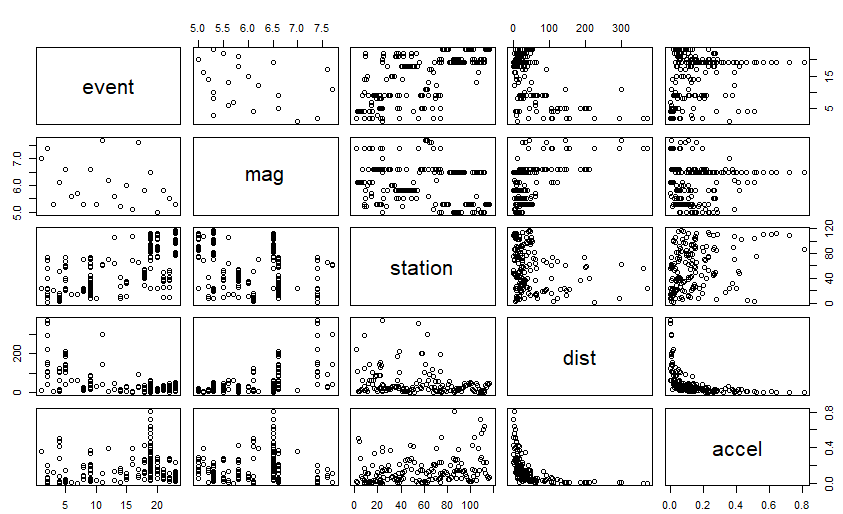
上記の組み合わせをみるに、なんらかの関係性を想定できそうなのは dist と accel の間だけじゃねえか、と思われます。遠くなれば減衰するのは常識的にもうなづけます。でも最近は「異常震域」とか地球内部の立体構造に基く地震波伝播の仕組みも「常識」になってきているように思われるので、そんな単純じゃないだろ~というツッコミもあるやと。
も少しカッコよくグラフ化
ggplot2パッケージを使って、少しグラフをカッコよくしてみました。オペレーションは以下です。
library(ggplot2) g20 <- ggplot(data=attenu, aes(x=dist, y=accel, color=event))+geom_point() g21 <- g20 + labs(title="attenu(evnet)", x="dist[km]", y="accel[g]") g21
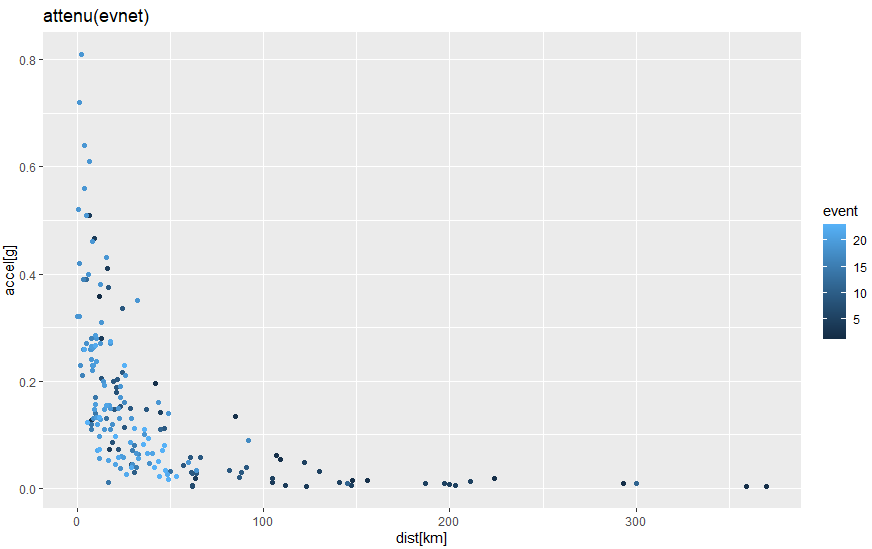
結果のグラフが以下に。遠くからみると「反比例」のグラフ的な感じがしないでもないです。しかしそう見るには問題があります。各地震毎に色が微妙に変わってますが、Mwの異なる強い地震も弱い地震も同じグラフにまとめてしまっているからです。Mwの大きいやつは遠くでも強く揺れるんでないかと。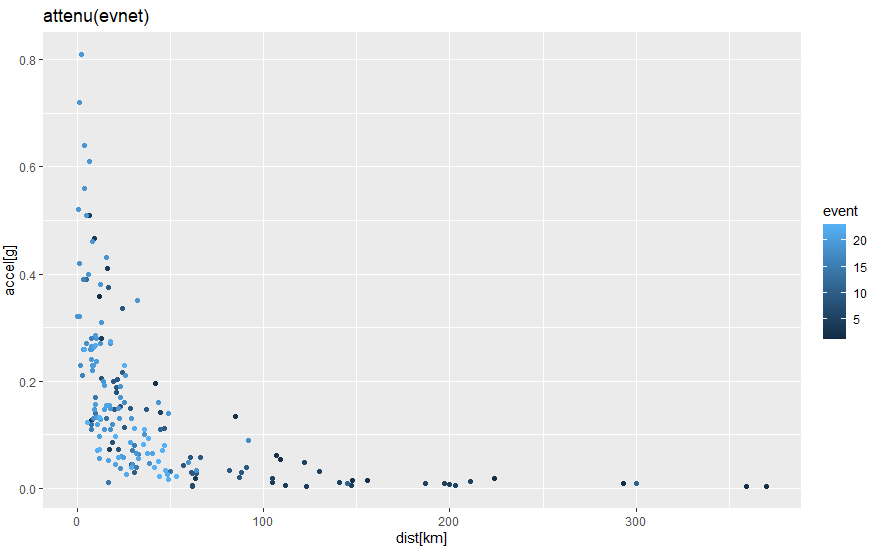
地震毎の集計グラフは後でやるので、ここではMw毎にファセットを切って、同じ強度の地震を同じグラフ面にまとめてみました。
g30 <- ggplot(data=attenu, aes(x=dist, y=accel, color=event))+geom_point()+facet_wrap(vars(mag)) g31 <- g30 + labs(x="dist[km]", y="accel[g]") g31
結果はこんな感じ。
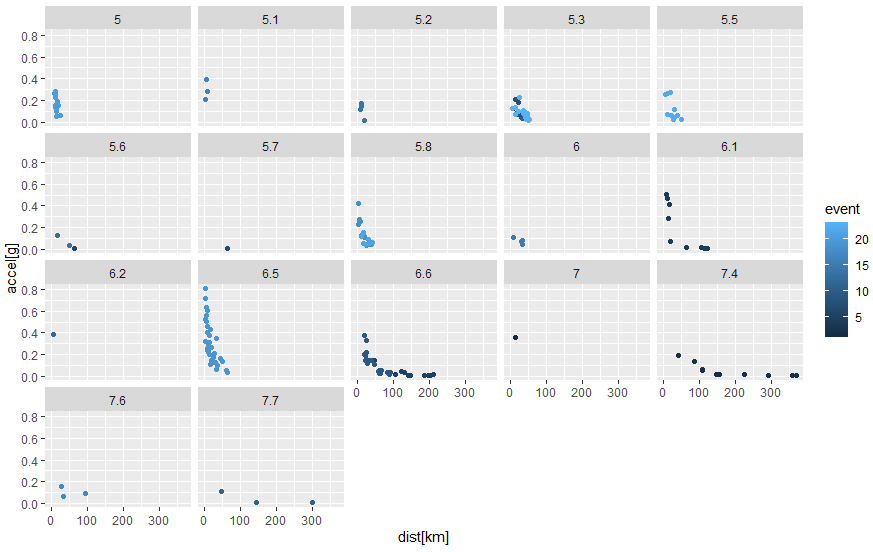
結果は反比例的なカーブに見えますが、イマイチ。Mwのデカい奴らの測定点数が少ないのが痛いデス。
処理例にそって
今回の説明ページには具体的処理例の記載があるので、それをなぞって練習してみました。まずは、データ構造を観察するところ。
処理例では、data.class関数をsapply関数でデータフレームの各列に適用しています。こんな感じ。
しかし、当方では RStudio を使用させていただいているので、わざわざ上記のようにコマンドを打たなくても画面上に以下が常時表示されています。
つづいてデータの観察です。さきほどは、興味本位でMwの最大値だけ見ていますが、summary()関数使って全貌を確認すると。
観測点の番号そのものに、積極的な意味を見出さないですが、これみると名無しの観測データもあることが分かります。また、Mwの最小は5なので、結構強めの奴らのみのデータセットであることも分かります。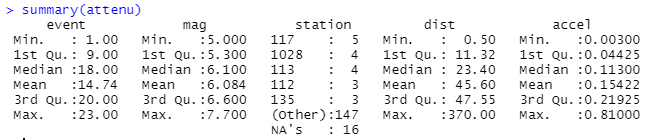
グラフ化の例が以下に。
pairsは先ほどのplotコマンドと同じ結果になるので、下のcoplotの結果のみ示します。やっぱり地震毎にデータを分割しないとダメだよね、ということで、as.factor(event)でevent番号で分離しています。ちょいと地味ですがこんなグラフ。
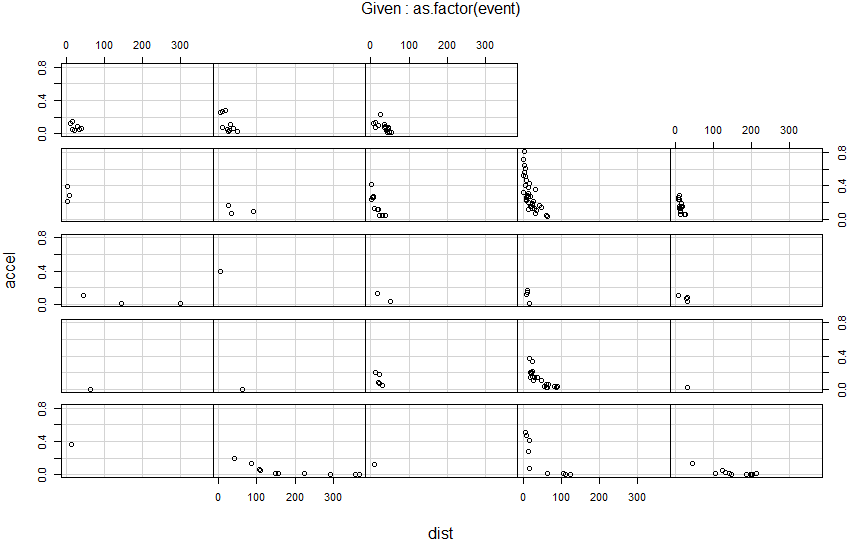
反比例であれば、両対数グラフにすれば右肩下がりの直線になるはず、ということで描いている coplot が以下に。logとったあとで回帰直線引いているのですが、直線にはなり切れませぬ。
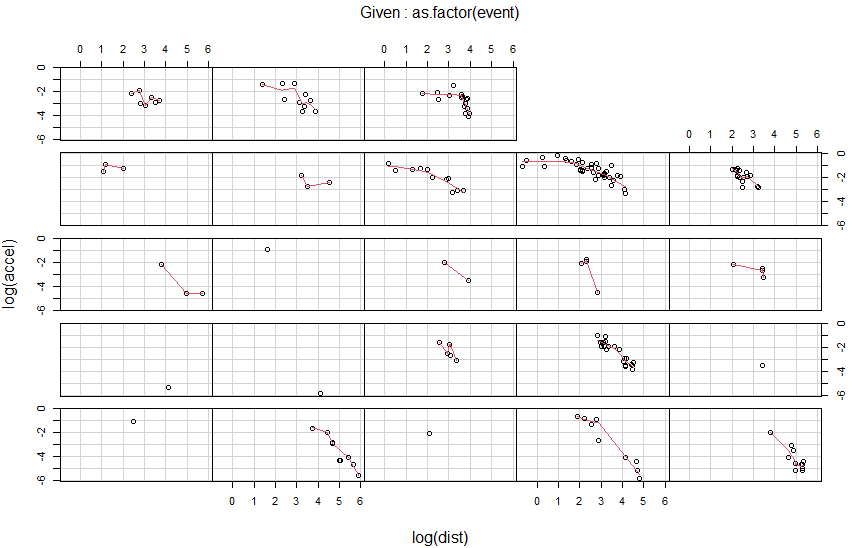
カリフォルニアであろうと日本であろうと、地震はそれほど単純じゃあない、と。