前回の自前ノード data-checkは、次々と流れてくるpayloadに載っている数値データの最大、最小、上限、下限をチェックできるものでした。今回は、平均、分散、標準偏差などを計算できるように機能拡張してみます。次々と流れてくるデータの分散を求めるのはどうしたらよいの?そういえばアルゴリズムがあったよな。
※「ブロックを積みながら」投稿順 index はこちら
※動作確認にはRaspberry Pi 3 model B+のRaspberry Pi OS(32bit)上にインストールした以下を使用しています。
-
- Node-RED v2.0.5
- node-red-dashboard 3.2.0
Welfordアルゴリズム
時系列で流れてくる数値列の平均をその場その場で次々と求めるには数値列の総和と数値の数を記憶していれば定義通りに求めることができます。しかし、分散(および標準偏差)の場合、定義通りであると各データから平均を引いて二乗して行かねばならないので、全データを記憶しておかないとなりませぬ。成り行きで流れてくるデータ点数を全て記憶するのは大変。ましてや変化する平均値にあわせて毎回計算しなおすなどやってられません。
そういうときのためのアルゴリズムがあったよな、と思って調べました。「Welford アルゴリズム」というお名前みたいっす。オンラインでインクリメンタルに平均と分散(そして標準偏差)を求めるもの。統計アルゴリズムの素人がとやかく言うのも何なので、以下などご覧くだされ。検索すればいろいろなページがみつかります。
インクリメンタルに複数の時系列データに対する平均・標準偏差を計算する
なお上記ページにはWelfordアルゴリズムだけでなく、繰り返しによる丸め誤差の蓄積に対応するためのアルゴリズムまで実装されていて「実用的」です。しかし、当方のはWelfordのみ。シンプルで分かりやすい?けど「非実用的」?手抜きなことは確か。
自前ノード data-checkの更新
今回は JavaScript部分のみの変更となります。こんな感じ。
module.exports = function(RED) {
function DataCheckNode(config) {
RED.nodes.createNode(this, config);
var node = this;
this.name = config.name;
this.ulimit = config.ulimit;
this.dlimit = config.dlimit;
node.on('input', function(msg) {
var nodeContext = this.context();
var nData = nodeContext.get('nData')||0;
var minData = nodeContext.get('minData')||Number.MAX_VALUE;
var maxData = nodeContext.get('maxData')||-Number.MAX_VALUE;
var meanOld = nodeContext.get('meanOld')||0;
var m2Old = nodeContext.get('m2Old')||0;
var inputData = parseFloat(msg.payload);
var ulim = Number(this.ulimit);
var dlim = Number(this.dlimit);
if (!isNaN(inputData)) {
nData++;
var meanNew = meanOld + (inputData - meanOld)/nData
var m2New = m2Old + (inputData - meanOld)*(inputData - meanNew)
if (inputData > maxData) {
maxData = inputData;
nodeContext.set('maxData', maxData);
}
if (inputData < minData) {
minData = inputData;
nodeContext.set('minData', minData);
}
msg.NDATA = nData;
msg.DATAMAX = maxData;
msg.DATAMIN = minData;
msg.MEAN = meanNew;
msg.M2 = m2New;
msg.NAME = this.name;
nodeContext.set('nData', nData);
nodeContext.set('meanOld', meanNew);
nodeContext.set('m2Old', m2New);
if (!isNaN(ulim) && (inputData > ulim)) {
msg.topic = "Higher than the ulimit";
}
if (!isNaN(dlim) && (inputData < dlim)) {
msg.topic = "Lower then the dlimit";
}
} else {
nodeContext.set('maxData',-Number.MAX_VALUE);
nodeContext.set('minData', Number.MAX_VALUE);
nodeContext.set('nData', 0);
nodeContext.set('meanOld', 0);
nodeContext.set('m2Old', 0);
}
node.send(msg);
});
}
RED.nodes.registerType("data-check", DataCheckNode);
}
Welfordアルゴリズムの実装を隠れ蓑に、コッソリ修正した点があります。payloadに載ってくる数値文字列の数値への変換を Number() 関数から、parseFloat()関数に入れ替え、parseFloat()がNaNを返すようなpayloadの場合には、記憶を初期化するようにいたしました。連続して数値が到来している間は、その最大、最小、平均等を求めますが、数値以外のものを送り込むと初期化されるっと。
JavaScriptソースの更新後、例によって .node-redディレクトリで npm updateして、node-red-restart すれば自前ノードの変更が反映されます。
動作検証用のフロー
検証用のフローは前回よりも少し複雑になりました。こんな感じ

平均とか分散とかの計算が正しく行われていることを検証しないとならないので、前回までのように乱数をたれ流すのではなく、既に平均、標準偏差とか計算済のテストデータを流し込めるように変更しました。また、先ほどのべた「記憶の初期化」ができるようにNaNに変換されるpayloadを送出するRESETノードも追加してみました。
追加した以下のInjectノードで検証用データファイルを指定してます。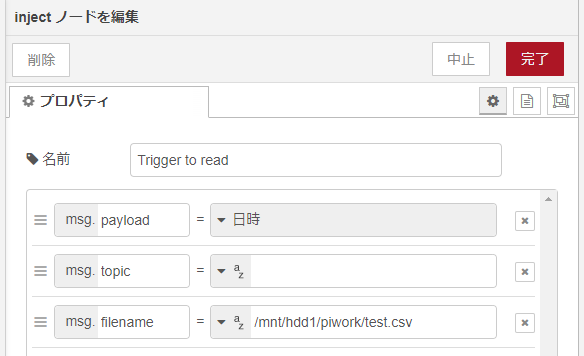
今回使用の検証用のデータファイルはCSVといいつつ、単なるテキストファイルです。こんな感じ。
これをFile INノードで読み出します。
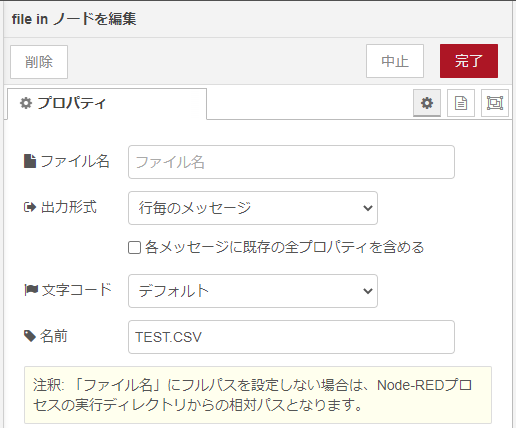
自前ノードdata-check以下の設定は前回とまったく同じです。
検証結果
合計25点のテストデータを全部通し終わった最後のデータをDebugウインドウで観察したものが以下に
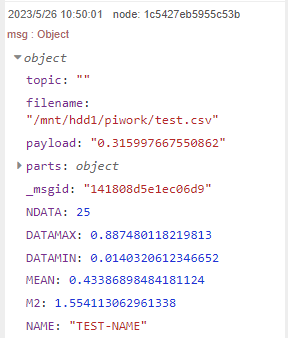
MEANは平均そのものですが、M2は分散計算するための二乗和です。M2をNDATAで割れば分散、NDATA-1で割れば不偏分散ということで。標準偏差は分散の平方根とればよいっと。
予め表計算ソフトでテストデータの平均、と標準偏差、標本標準偏差を求めてあったので、上記と比べてみます。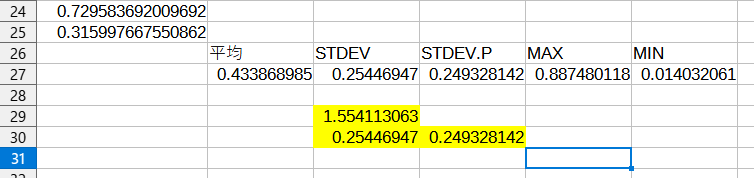
表示桁数は違うけれども、平均、MAX、MINは一致しているみたいです。M2の値とそれから求めた標準偏差、標本標準偏差の値は黄色の部分です。これまた一致しとりますな。計算できとるみたいデス。