ようやく浮動小数の「スカラー演算」命令をあらかた舐めたので次はSIMD命令と思いました。しかし「浮動小数およびSIMDの」ロード・ストア命令の練習を挟んでおきたいと思います。ロード、ストア無にはSIMDの威力も半減以下と。ロード、ストア命令自体は以前やった整数のロード、ストアの以下同文。それでもいろいろありすぎA64。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
スカラー?SIMDと浮動小数のロード、ストア
SIMDはスカラーで無いだろうよ、とツッコミを入れたくなりますが、今回から練習するのはSIMDでもスカラーな値を取り扱うための命令 兼 フツーの浮動小数点演算(これこそスカラー)のオペランドをロード、ストアするための命令です。後でやってみるつもりですがSIMDにはベクタのロード、ストア命令もあり、という文脈でのスカラーなSIMDロードみたいっす。知らんけど。
今回練習してみるロード命令の1回目はアドレシングにベースレジスタ+即値オフセットを取る一族です(以前整数型のときは確かロード/ストアで全7回もやったような。またあれの繰り返しか?命令多すぎA64。)
-
- ニーモニックは整数型のときと同じLDR
- アドレシングモードも整数型のときと同じ
- ロード先(デスティネーション)のみSIMD/浮動小数レジスタ
です。
「スカラーSIMD」などと一瞬分けわからないことを言っていることから想像つく通りで、ロード先は以下のようになります。あれれ、整数型のときより型が増えてるじゃん。
-
- バイト
- ハーフワード(16ビット)
- ワード(32ビット)
- ダブルワード(64ビット)
- クワッドワード(128ビット)
浮動小数点演算では、ARMv8.0は半精度のサポート無ね、などと言ってハーフワードなどは不要でしたが、ロード/ストア命令はSIMDと浮動小数の「兼用」なので上記の全てが必要です(SIMDには整数もあり~の。ロード/ストアは転送する内容が浮動小数なのか整数なのかなど気にしないし。。。)
上記の転送幅とアドレシングモードの組み合わせだけで目が回りそうです。例によって大幅手抜きをすることにいたしました。ワード(浮動小数点数としてはfloat型)の転送のみ練習に絞りましたです。手抜き。ただし、アドレシングモードは以下の3種を全て使ってみます。
-
- ベース+ポストインデックス・オフセット
- ベース+プリインデックス・オフセット
- ベース+アンサインド・オフセット
今回実験のアセンブリ言語関数
「いつものように手抜きな」関数プロローグもエピローグもない被テスト関数ですが、よく見ると変なところがあります。例えば以下のラベルのところ、
-
- fldrSImmPost
- fldrSImmPostP
まったく同じコードなのに、ラベルを変えて2回定義してます。後で出てくるC言語のテスト駆動部を見ると明らかですが、浮動小数の戻り値か、整数の戻り値を取るかで使い分けてます。ポスト、プリのアドレシングモードでは書き戻したアドレスも確認しておきたいので整数戻り値の確認もしておきたかったからです。こういうところがArm、メンドクセー奴。
.globl fldrSImmPost, fldrSImmPostP, fldrSImmPre, fldrSImmPreP, fldrSImmU
.text
.balign 4
fldrSImmPost:
ldr s0, [x0], #4
ret
fldrSImmPostP:
ldr s0, [x0], #4
ret
fldrSImmPre:
ldr s0, [x0, #4]!
ret
fldrSImmPreP:
ldr s0, [x0, #4]!
ret
fldrSImmU:
ldr s0, [x0, #8]
ret
なお、プリ、ポスト、アンサインドともアセンブラ上の即値オフセットの表現は全てバイト単位です。上記の#4, #8は同じ「尺度」なので混乱ありません。しかし、命令エンコーディング上は、プリ、ポストは9ビット幅のバイト単位アドレス指定(-256から+255範囲)ですが、アンサインドは12ビット幅(符合無)オフセットアドレスにさらにオペランドのバイト幅分のシフトを行います。よってクワッドワードオペランドの場合、#0から#65520までの指定が可能です。上記では#8は、アセンブラ上は#8と書いているけど機械語エンコード的には2であると。これまたメンドイ。
C言語記述のmain関数
いつも通りの「通り一遍さわるだけの手抜きな」C言語記述のテスト駆動部です。float型を構造体メモリからロードしてます。floatデータの何がロードできたかとは別に、アクセスにつかったレジスタ内のアドレスの変化にも注目であります。
#include <stdio.h>
#include <stdint.h>
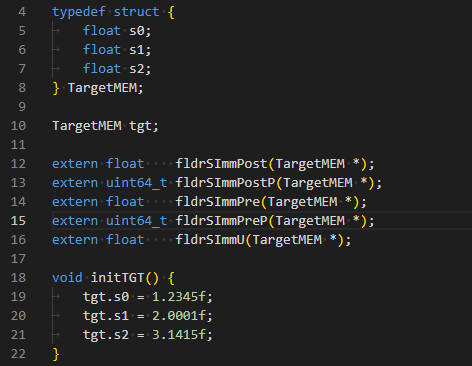
typedef struct {
float s0;
float s1;
float s2;
} TargetMEM;
TargetMEM tgt;
extern float fldrSImmPost(TargetMEM *);
extern uint64_t fldrSImmPostP(TargetMEM *);
extern float fldrSImmPre(TargetMEM *);
extern uint64_t fldrSImmPreP(TargetMEM *);
extern float fldrSImmU(TargetMEM *);
void initTGT() {
tgt.s0 = 1.2345f;
tgt.s1 = 2.0001f;
tgt.s2 = 3.1415f;
}
int main(void) {
float resultS;
uint64_t uresultX;
initTGT();
resultS =fldrSImmPost(&tgt);
printf ("fldrSImmPost: %f\n", resultS);
uresultX=fldrSImmPostP(&tgt);
printf ("fldrSImmPostP: 0x%016lx\n", uresultX);
resultS =fldrSImmPre(&tgt);
printf ("fldrSImmPre: %f\n", resultS);
uresultX=fldrSImmPreP(&tgt);
printf ("fldrSImmPreP: 0x%016lx\n", uresultX);
resultS =fldrSImmU(&tgt);
printf ("fldrSImmU: %f\n", resultS);
return 0;
}
ビルドして実行
ビルドして実行した結果が以下に。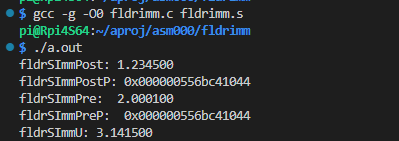
「ポスト」と「プリ」で、レジスタ内に残っているメモリアドレスは同じだけれど、ロードした値は違うっと。当たり前か。