前回はJetson nano上で nvprof を使い、GPU実行部分のプロファイリングをちょっとだけ触ってみました。しかし、本来はCPU部分のプロファイリングもできる筈の nvprofですが、このプラットフォームではCPUのプロファイリングは駄目だと警告がでます。そこで、CPU部分のプロファイリングについては nvcc生成のCUDA使用の実行ファイルを、定番のgprof と oprofile の2つでプロファイリングしてみました。
プロファイラは、プログラムのどの部分がどれだけの時間を使っているとか、この関数は何回呼び出されているとか、主に性能に関わる実行時の挙動を調べるためのお道具です。その仕組みから大きく2種類に分けられると思います。
-
- コンパイル時にインストルメンテーション必要なもの
- ハードウエアのカウンタと割り込みを必要とするもの
第1のインストルメンテーション方式は、オブジェクト各部にプロファイリング用の小さなルーチンをコンパイラが埋め込んでくれるものです。インストルメンテーションを施されたオブジェクトコードを実行すると、それらが集めた情報を外部に書き出してくれるので、後からプログラムの挙動が解析できるわけです。当然、インストルメンテーション分、若干の性能低下はあり得ます。こちらの型式のプロファイラの代表選手が
gprof
じゃないかと思います。名前の通り、gccで生成するオブジェクトをプロファイリングするためのツールです。Jetson Nano用のインストールイメージには含まれていたので、即使用できました。
これに対して第2のハードウエアのカウンタと割り込みによる方式は、プロファイリングのために特別なコードを埋め込むといったオブジェクトコードの改変は必要ありません。CPUやGPUがハードウエアとして備えている(機種毎に異なる)性能測定用のカウンタとそのカウンタが発生する割り込みを使って、どこがどれだけ動いているのか調べます。ハードウエアによるサンプリング方式なので、あまり短い実行では正確に測れない問題がある筈ですが、ある程度長い期間の実行であれば、アプリだけでなく、OS内部まで測定対象にできます。前回使用の nvprof がそうですし、oprofile もそのようなプロファイラです。
今回、測定のターゲットとするのは、CUDAのサンプルファイルの中からこれまた定番
matrixMul(CUDAを使った単精度の行列積計算のサンプル)
サンプルディレクトリを見れば、Makefileなども用意していただいているのですが、単一ソースをプロファイリングするだけなので、直接 nvccにコマンドラインオプションを与えてコンパイルしていきます。![]()
gprof用のオプションを付けずにコンパイルするとこのような感じ。できたオブジェクトに何も引数を与えずに実行すると 320×320の行列Aと640×320の行列Bの掛け算をして、性能をGFlop/sで表示します。私のJetson Nano上で上記のオプションだと、以下に示すとおり31~32GFlop/sくらいの値がでます(初回は値が小さく出たりするので注意)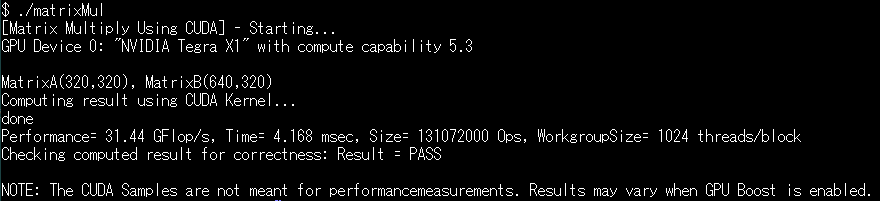
これを gprof 用にコンパイルする場合、nvcc に追加で -pg オプションを渡すだけです。nvccは、GPUで実行されるカーネルこそNVIDIAのツールでオブジェクトまで落としているようですが、CPUで実行されるコードは、gcc(Windows版ではvc)にお願いしているようなので、この-pgオプションも gcc にそのまま渡されているのだと思います。こちらのバージョンを実行するとこんな感じ。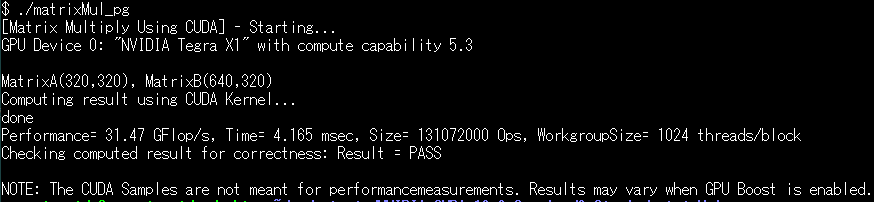
画面上では、ほとんど差は無いですが、後の方は、gmon.outなるプロファイリング結果を格納したファイルが出来ているのがミソです。それを gprof に食わせることで、プロファイリング結果を読むことができます。ベーシックなフラット・プロファイリングは
$ gprof matrixMul_pg gmon.out -p
Flat profile: Each sample counts as 0.01 seconds. % cumulative self self total time seconds seconds calls Ts/call Ts/call name 100.00 0.01 0.01 MatrixMultiply(int, char**, int, dim3 const&, dim3 const&) 0.00 0.01 0.00 301 0.00 0.00 __device_stub__Z13MatrixMulCUDAILi32EEvPfS0_S0_ii(float*, float*, float*, int, int) 0.00 0.01 0.00 1 0.00 0.00 _GLOBAL__sub_I__Z12ConstantInitPfif 0.00 0.01 0.00 1 0.00 0.00 __sti____cudaRegisterAll() ~以下略~
プログラム自体が小さいのであまり面白いこともありませんが、ソースに書かれている関数とCUDAの上に被さっている部分などがプロファイリングされているようです。コールグラフ生成の場合は、
$ gprof matrixMul_pg gmon.out -q
$ gprof matrixMul_pg gmon.out -q Call graph (explanation follows) granularity: each sample hit covers 4 byte(s) for 100.00% of 0.01 seconds index % time self children called name <spontaneous> [1] 100.0 0.01 0.00 MatrixMultiply(int, char**, int, dim3 const&, dim3 const&) [1] 0.00 0.00 301/301 __device_stub__Z13MatrixMulCUDAILi32EEvPfS0_S0_ii(float*, float*, float*, int, int) [288] ----------------------------------------------- 0.00 0.00 301/301 MatrixMultiply(int, char**, int, dim3 const&, dim3 const&) [1] [288] 0.0 0.00 0.00 301 __device_stub__Z13MatrixMulCUDAILi32EEvPfS0_S0_ii(float*, float*, float*, int, int) [288] ----------------------------------------------- 0.00 0.00 1/1 __libc_csu_init [1279] [289] 0.0 0.00 0.00 1 _GLOBAL__sub_I__Z12ConstantInitPfif [289] ----------------------------------------------- 0.00 0.00 1/1 __libc_csu_init [1279] [290] 0.0 0.00 0.00 1 __sti____cudaRegisterAll() [290] ----------------------------------------------- ~以下略~
続いて、oprofile に参りましょう。oprofileは、gprofのようにインストールイメージに含まれていないので、別途インストールする必要があります。また、ハードウエアのカウンタや割り込みを使用するためか sudo 必須です。ただし、nvprofとは異なり、/usr/binにインストールされるのでsudoは何もしなくても「在りかを知って」ます。実行する場合には operf (パッケージは oprofileだが、コマンド名は operf)の引数として測定対象を渡します。こんな感じ。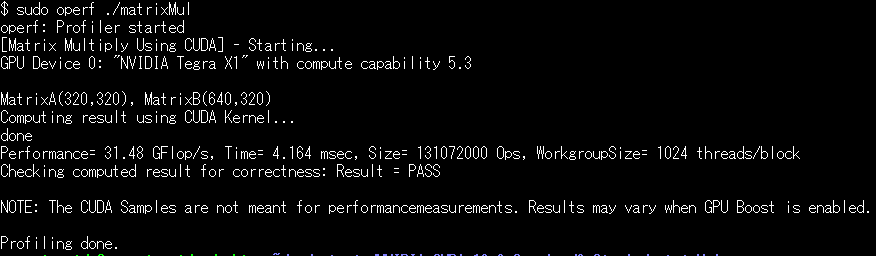
実行すると、サブディレクトリにデータが収拾されております。そのデータを取り出すとき、何も指定しなければ、バイナリファイル単位でのプロファイリング結果が出力されます。
$ opreport
CPU: ARM Cortex-A57, speed 1428 MHz (estimated) Counted CPU_CYCLES events (Cycle) with a unit mask of 0x00 (No unit mask) count 100000 CPU_CYCLES:100000| samples| %| ------------------ 18869 100.000 matrixMul CPU_CYCLES:100000| samples| %| ------------------ 9474 50.2093 kallsyms 6769 35.8737 libcuda.so.1.1 2307 12.2264 libc-2.27.so 144 0.7632 matrixMul 70 0.3710 nvgpu 55 0.2915 ld-2.27.so 26 0.1378 libpthread-2.27.so 11 0.0583 libnvrm_gpu.so 8 0.0424 libnvidia-fatbinaryloader.so.32.2.0 2 0.0106 libnvrm.so 1 0.0053 libdl-2.27.so 1 0.0053 libstdc++.so.6.0.25 1 0.0053 libnvos.so
それに対して、オプション –symbolsを与えると、シンボル単位での集計となり、こんな感じ。
$ opreport –symbols
CPU: ARM Cortex-A57, speed 1428 MHz (estimated) Counted CPU_CYCLES events (Cycle) with a unit mask of 0x00 (No unit mask) count 100000 samples % image name symbol name 6769 72.0490 libcuda.so.1.1 /usr/lib/aarch64-linux-gnu/tegra/libcuda.so.1.1 2222 23.6509 libc-2.27.so sched_yield 136 1.4476 matrixMul MatrixMultiply(int, char**, int, dim3 const&, dim3 const&) 70 0.7451 nvgpu /nvgpu 31 0.3300 libc-2.27.so __GI_memcpy 17 0.1809 ld-2.27.so do_lookup_x 13 0.1384 ld-2.27.so _dl_relocate_object 11 0.1171 libnvrm_gpu.so /usr/lib/aarch64-linux-gnu/tegra/libnvrm_gpu.so 9 0.0958 ld-2.27.so _dl_lookup_symbol_x 9 0.0958 libc-2.27.so calloc 9 0.0958 libpthread-2.27.so __pthread_mutex_unlock_full 8 0.0852 libc-2.27.so __GI___memset_generic 8 0.0852 libnvidia-fatbinaryloader.so.32.2.0 /usr/lib/aarch64-linux-gnu/tegra/libnvidia-fatbinaryloader.so.32.2.0 7 0.0745 ld-2.27.so strcmp 7 0.0745 libc-2.27.so _int_malloc 7 0.0745 libpthread-2.27.so pthread_mutex_lock 5 0.0532 libc-2.27.so malloc ~以下略~
やはりなんと言っても、oprofileの最大の特徴が、ハードウエアの内蔵するイベントカウンタを使っているところ。上の計測は、デフォルトのCPU_CYCLESというCPUサイクルをカウントして、10万回サイクルごとに割り込みを発生させたもの。引数を変更すれば、別なイベントにすることもできます。例えば、
INST_RETIRED
リタイヤまでたどり着いた命令数(投機的に実行するスーパスカラー機では、実行始めたけれど、途中で止めになるような命令もあるので、「リタイア」した命令数を数えれば本当の意味で実行完了した命令数を数えたことになる)を数えるのには下のようにいたしました。コロンの後の数字100000は、10万カウント(10万リタイア命令)毎に割り込み起こせ、という指令であります。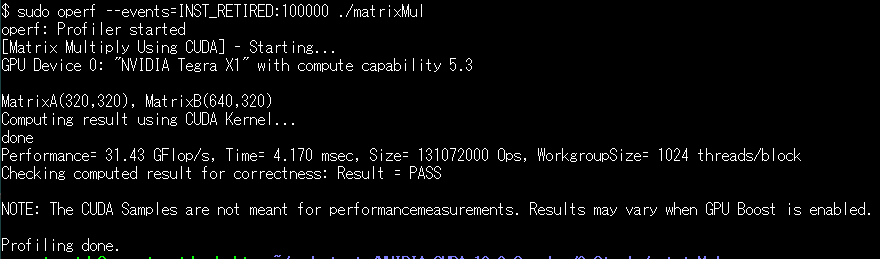
リポートみると、CPU_CYCLESとはちょっと違う数字が見えてきます。
CPU: ARM Cortex-A57, speed 1428 MHz (estimated) Counted INST_RETIRED events (Instruction architecturally executed) with a unit mask of 0x00 (No unit mask) count 100000 INST_RETIRED:1...| samples| %| ------------------ 10506 100.000 matrixMul INST_RETIRED:1...| samples| %| ------------------ 5255 50.0190 kallsyms 2753 26.2041 libc-2.27.so 2341 22.2825 libcuda.so.1.1 48 0.4569 nvgpu 47 0.4474 matrixMul 39 0.3712 ld-2.27.so 10 0.0952 libpthread-2.27.so 10 0.0952 libnvidia-fatbinaryloader.so.32.2.0 3 0.0286 libnvrm_gpu.so
なおeventに指定できる「メトリクス」はCPUの機種毎にいろいろあり、x86などでは数百も存在します。Jetson Nanoの場合は、以下のOprofileのホームページを見るか、
あるいは、oprofileパッケージをインストールすると付いてくる
$ ophelp
で見るのが良いかと思います。いろいろあるので目が回りますが。。。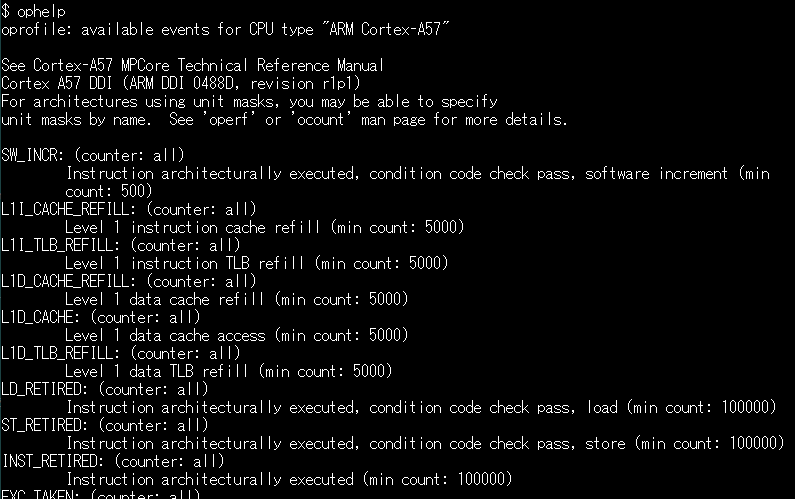
nprofでも当然各種のeventが測定可能なのですが、それはそれで奥深いので、またそのうち