AIをタイトルにしながら、低レベルな話ばかり書いていますが、それもこれも
Jetson Nano
は、AIネタと決めたからなんであります。先は長いですが、やっていく先にはAIにもつながりましょう。さて、月曜日に cuda-gdb でハマった話を投稿いたしましたが、デバッガが立ち上がったところでおしまいになってました。CUDA用のデバッガらしい話題皆無。というわけで今回は、実際にcuda-gdbを動かして、CUDAのサンプルプログラムの中身をのぞいてみます。
ターゲットプログラムは、もっとも簡単そうなCUDAのサンプルプログラム、vectorAdd です。デバッガ用にnvccでビルドして、立ち上げるところまでは こちら を御覧ください。さて、立ち上げたところで、
help cuda
などと、やってみれば分かります。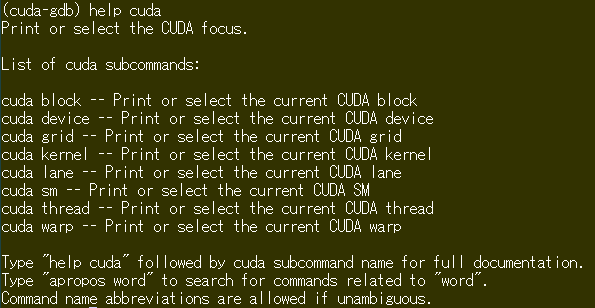
結局、cuda-gdb を使って、CUDAのプログラムをデバッグするのであれば、上記に現れる block, device, grid, kernel, lane, sm, thread, warp なんてものどもに向き合わざるを得ないのであります。まあ、CUDAでプログラム書いているなら、その辺は分かっている筈、ということなのか、cuda-gdbのマニュアルにはそっけないことしか書いてありません。しかし、それでも結構良いことも書いてあります。
-
- ソフトウエアの視点から見えるのは、kernel, block, thread
- ハードウエアの視点から見えるのは、device, SM, warp, lane
- もうひとつのソフトウエアの視点として、grid, block, thread
そして、kernel と (grid, device)タプルは1対1対応なのだ、と。このお言葉だけを胸にいだいて cuda-gdb を動かしてまいりましょう。しかし、Jetson Nanoの場合、deviceは1個だけ0番、SMも1個だけ0番、でありますので、随分と簡単になるじゃないか、と。でも、ま、やってみれば、vectorAddのようなシンプルなものでも十分目が回るんでありますが。
さて、ブレークポイントなどは普通のgdb と変わりません。
b 行番号
ってな感じでOK. プログラム名と同じ、kernel関数名 vectorAddの実際の浮動小数点 Addのところの直前にブレークポイントを置きました。処理の実態部分のみを引用させてもらえば、
35 int i = blockDim.x * blockIdx.x + threadIdx.x;
36
37 if (i < numElements)
38 {
39 C[i] = A[i] + B[i];
40 }
各スレッドにそれぞれ固有の値が渡される blockIdx.xとthreadIdx.xから、実際処理すべき要素番号を示す i を求めて、A+BはCと計算する、と。これ以上分かりやすいサンプルはありますまい。
実際に計算する要素数は 50000まで、これを1ブロックあたり256スレッドで196ブロックを用いて計算する、と。
196 * 256 = 50176
なので、50000要素でちとあまると。余った分はif文で計算しないようになっている。さて、走らせてみれば、早速ブレークポイントで止まりました。いろいろメッセージでてまいりますが、下を見れば、ブロック0のスレッド0、先頭要素でブレークしたもののようであります。
[Switching focus to CUDA kernel 0, grid 1, block (0,0,0), thread (0,0,0), device 0, sm 0, warp 0, lane 0]
さきほどのA+Bの直前で止めたので、step実行で計算させ、内容を見てみます。
(cuda-gdb) step 39 C[i] = A[i] + B[i]; (cuda-gdb) print A[i] $6 = 0.840187728 (cuda-gdb) print B[i] $7 = 0.394382924 (cuda-gdb) step 41 } (cuda-gdb) print C[i] $8 = 1.23457062
ちゃんと、A+BはC計算していました。よかった。さて、別なスレッドも見てみます。3番目のスレッド(番号は2)に切り替えてみます。
(cuda-gdb) cuda thread (2) [Switching focus to CUDA kernel 0, grid 1, block (0,0,0), thread (2,0,0), device 0, sm 0, warp 0, lane 2] 41 } (cuda-gdb) print A[i] $10 = 0.911647379 (cuda-gdb) print B[i] $11 = 0.19755137 (cuda-gdb) print C[i] $12 = 1.10919881
今度はハードの視点に切り替えて、指定してみます。とは言えこの指定では、5番目のスレッド(番号4)に切り替えるのと同じ。
(cuda-gdb) cuda device 0 sm 0 warp 0 lane 4 [Switching focus to CUDA kernel 0, grid 1, block (0,0,0), thread (4,0,0), device 0, sm 0, warp 0, lane 4] 41 } (cuda-gdb) print A[i] $14 = 0.277774721 (cuda-gdb) print B[i] $15 = 0.553969979 (cuda-gdb) print C[i] $16 = 0.831744671
ともかく、スレッドは沢山ありますが、中身を吟味できると。それだけ呼び出したのも自分であれば、自業自得?なのでスレッドの海に漕ぎ出すしかありますまい。しかし、何も手助けしてくれないわけでもなく、通常のgdb同様、条件付きのブレークなども使えるので、多少は所望の場所に手を伸ばしやすい、と。こんな感じ。
(cuda-gdb) break 37 if threadIdx.x == 100
勿論、cudaのハードウエアとソフトウエアの割り振りなどは一覧表がでます。Jetson Nanoの場合、deviceやSMを見ても1個しかないので、deviceの一覧は、役に立つ情報もあるものの、ちょっとさびしい。
(cuda-gdb) info cuda kernels Kernel Parent Dev Grid Status SMs Mask GridDim BlockDim Invocation * 0 - 0 1 Active 0x00000001 (196,1,1) (256,1,1) vectorAdd(A=0xf00690000, B=0xf006c0e00, C=0xf006f1c00, numElements=50000)
SMは、もっと見るものないですね。さびしい。
(cuda-gdb) info cuda sms SM Active Warps Mask Device 0 * 0 0xffffffffffffffff
しかし、warpともなると、現在64個存在することが分かります。だんだん数が多くなって目が回ります。
(cuda-gdb) info cuda warps Wp Active Lanes Mask Divergent Lanes Mask Active Physical PC Kernel BlockIdx First Active ThreadIdx Device 0 SM 0 0 0xffffffff 0x00000000 0x0000000000000190 0 (8,0,0) (0,0,0) 1 0xffffffff 0x00000000 0x0000000000000190 0 (8,0,0) (32,0,0) 2 0xffffffff 0x00000000 0x0000000000000190 0 (8,0,0) (64,0,0) * 3 0xffffffff 0x00000000 0x0000000000000190 0 (8,0,0) (96,0,0) 4 0xffffffff 0x00000000 0x0000000000000190 0 (8,0,0) (128,0,0) ~途中略~ 62 0xffffffff 0x00000000 0x0000000000000168 0 (12,0,0) (192,0,0) 63 0xffffffff 0x00000000 0x0000000000000008 0 (15,0,0) (128,0,0)
laneの一覧もでますが、みていけばキリがありません。兎にも角にも
focus
というやつを適切な場所に指定しなければならんと。メンドイですが、致し方ありません。