前回も「素朴なピーク検出」続けてしまいました。しかしネット上を漁っていて発見、「プロの人は1行でピーク検出しちゃうんだ」。信号処理も素人ならScilabも素人のお惚け老人は驚愕。さっそく「真似っこ」してみようと。しかし、元のコードはMATLAB、Scilabは「似ているけど、じゃない」方なのでそのままでは動きませぬ。
※「手習ひデジタル信号処理」投稿順 Indexはこちら
※Windows11上のScilab6.1.1およびScilab上のツールボックスを使用させていただいております。
今回参照させていただいたページ
今回参照させていただいたのは、『@akinori-ito』様の以下のページです。
上記のページ自体はR言語(当方も別シリーズでお世話になってます)を使ってピーク検出について実践されておられるページなのです。その末尾にX(「旧ツイッター」と書くのはそろそろやめか?)の投稿が引用されてました。MATLABのプロの方ではないかと思われる『@hidekikawahara』先生のご投稿です。「自分がMATLAB でよく使っている方法。」ということで紹介されてます。
テストデータの生成からピーク検出、確認プロットまでXの一投稿
に収まってます。だらだらと散かったコードを書く年寄には目の覚める逸品デス。
Scilab上で動かす
しかし、@hidekikawahara先生のお示しになっているそのコードはMATLABです。ScilabはMATLABに「似ている」けれども、「独自の道をゆく」ところが多いです。なまじっか「似ている」だけに「混乱する」とも。。。
まずね、テスト用のピークのある数例を生成されているのですが、@hidekikawahara先生のコードは以下です。1行よ。
y = conv(hanning(50), randn(1000,1)) .^ 2;
正規分布に従う乱数を生成しておいてハニング窓とコンボルーションとって、二乗して非負の数列にしておられます。一撃ぜよ。
これをScilabで書き直すべしということでお惚け老人がやってみたのが以下です。
y = conv(window('hn', 50), rand(1000,1,'normal')) .^ 2;
これで良いのかな~。y を プロットしたものが以下に。たしかにピークが林立している感じっす。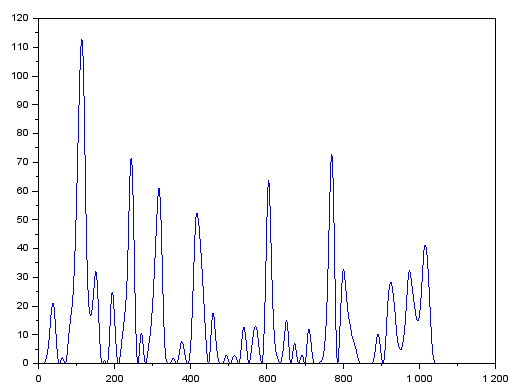
さて肝心のピークの場所を求める@hidekikawahara先生の御方法は以下です。インデックスの入れ物を用意した後、本体は1行!
base_id = 1:length(y); peak_loc = base_id(y > y([1 1:end-1]) & y > y([2:end end]));
上記の peak_locを求める部分、「痺れ」ましたぞ。お惚け老人がScilabで書いたものが以下に。
base_id = 1:length(y); peak_loc = base_id(y > y([1 1:length(y)-1]) & y > y([2:length(y) length(y)]));
ScilabではMATLABの end の代わりに $ という添え字で末尾を示せるのですが、上記のような場合(リストの中でさらに別なリストを操作しているから?)$使うとエラーになってしまいました。 こんな感じ。
こんな感じ。
仕方ないので、$でなく、length(y)を散りばめました。折角の簡潔明瞭なコードが汚くなってしまいましたが致し方ない?他に思いつかないし。とほほ。。。
ともあれ上記でピーク位置の検出が出来はず。プロットしてみると
ちゃんと検出してるじゃん。リストをチョイとズレた2本にしておいてそいつらと比べるってところが目から鱗。何かまたあったら使いたいテクですな。その前に忘却力か。。。