今回からA64のマニュアル呼ぶところの「Across Vector」命令群の練習に入ります。ベクタ横断、という言い方がしっくりこなければ、リダクション、あるいは縮約と言い換えても良いのでしょう。ベクトル内の各要素を「横断的」に処理して1個のスカラ値を得るための演算です。ベクトル演算の〆の一発ね。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
今回練習するリダクション命令
2回にわけて練習する予定のうち今回分は以下です。
-
- ADDV
- SADDLV
- UADDLV
- SMAXV
- SMINV
- UMAXV
- UMINV
1はSIMDソースレジスタ内の各要素を「横断的に」足し合わせた結果をデスティネーション(スカラ)に書き込むもの。2は符号付として足し合わせた結果を倍のビット幅でデスティネーションに書き込むもの。3は符号無として足し合わせた結果を倍のビット幅でデスティネーションに書き込むもの。
4はSIMDソースレジスタ内の各要素(符号付)の最大値をデスティネーション(スカラ)に書き込むもの。5は同じことの最小値。6と7は各要素を符号無と解釈するもの。
ベクトル演算を続けていった最後の最後で結果を縮約するときにあると便利なものどもです。
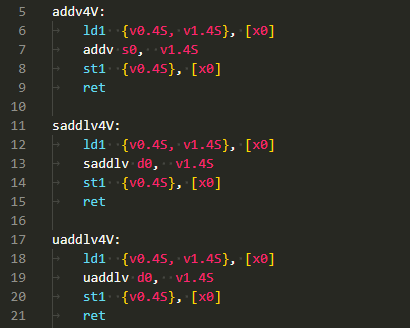
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。やはりSIMD要素幅はいろいろとれるのですが、いつもの手抜きでソース要素がワード(32bit)幅のときのみ練習してます。
.globl addv4V, saddlv4V, smaxv4V, sminv4V, uaddlv4V, umaxv4V, uminv4V
.text
.balign 4
addv4V:
ld1 {v0.4S, v1.4S}, [x0]
addv s0, v1.4S
st1 {v0.4S}, [x0]
ret
saddlv4V:
ld1 {v0.4S, v1.4S}, [x0]
saddlv d0, v1.4S
st1 {v0.4S}, [x0]
ret
uaddlv4V:
ld1 {v0.4S, v1.4S}, [x0]
uaddlv d0, v1.4S
st1 {v0.4S}, [x0]
ret
smaxv4V:
ld1 {v0.4S, v1.4S}, [x0]
smaxv s0, v1.4S
st1 {v0.4S}, [x0]
ret
sminv4V:
ld1 {v0.4S, v1.4S}, [x0]
sminv s0, v1.4S
st1 {v0.4S}, [x0]
ret
umaxv4V:
ld1 {v0.4S, v1.4S}, [x0]
umaxv s0, v1.4S
st1 {v0.4S}, [x0]
ret
uminv4V:
ld1 {v0.4S, v1.4S}, [x0]
uminv s0, v1.4S
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。今回も、扱うデータが符号付でも符号無でもCのデータ型などは踏みつぶしてしまって全てuint32_t型にしてあります。符号付きか符号無かは各自HEX表記を見て理解する、ということで。
#include <stdio.h>
#include <stdint.h>
#include <float.h>
#define MAXMEM (8)
uint32_t TargetMEM[MAXMEM];
extern void addv4V(uint32_t *);
extern void saddlv4V(uint32_t *);
extern void uaddlv4V(uint32_t *);
extern void smaxv4V(uint32_t *);
extern void sminv4V(uint32_t *);
extern void umaxv4V(uint32_t *);
extern void uminv4V(uint32_t *);
void initTGT() {
TargetMEM[0] = 7;
TargetMEM[1] = 7;
TargetMEM[2] = 7;
TargetMEM[3] = 7;
TargetMEM[4] = 0x7FFFFFFF;
TargetMEM[5] = 0x7FFFFFFF;
TargetMEM[6] = 3;
TargetMEM[7] = 2;
}
void initTGT2() {
TargetMEM[0] = 7;
TargetMEM[1] = 7;
TargetMEM[2] = 7;
TargetMEM[3] = 7;
TargetMEM[4] = 0x80000000;
TargetMEM[5] = 0x80000000;
TargetMEM[6] = -1;
TargetMEM[7] = -2;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i<4; i++) {
printf("%02d: %08x\n", i, TargetMEM[i]);
}
}
int main(void) {
initTGT();
addv4V(TargetMEM);
dumpTGT("addv");
initTGT();
uaddlv4V(TargetMEM);
dumpTGT("uaddlv");
initTGT();
umaxv4V(TargetMEM);
dumpTGT("umaxv");
initTGT();
uminv4V(TargetMEM);
dumpTGT("uminv");
initTGT2();
saddlv4V(TargetMEM);
dumpTGT("saddlv");
initTGT2();
smaxv4V(TargetMEM);
dumpTGT("smaxv");
initTGT2();
sminv4V(TargetMEM);
dumpTGT("sminv");
return 0;
}
実機実行結果の確認
以下のようにして ビルドして実行しています。
$ gcc -g -O0 simdADDV.c simdADDV.s $ ./a.out
標準出力に現れた結果が以下に。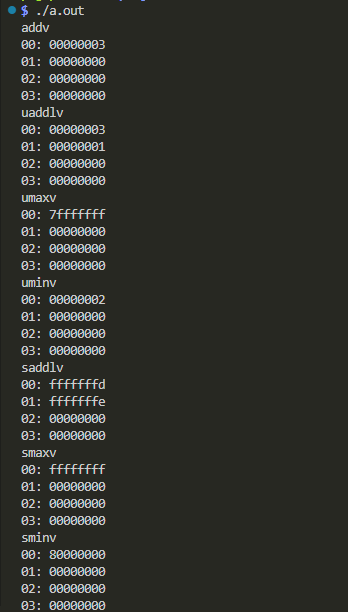
まあ予定どおりだわな。