前回の「お花の特徴」ではお花の名前書いてないじゃん、と不平を述べてましたが、今回の「植物の特徴」では5文字の英字ですがお名前ついてます。しかし、サンプル・データ・セットがちょいと大き目です。136種類の植物種に対して31の因子についてのデータです。端から調べていくと何日かかかりそう。不平不満ばかりだな、自分。
※使用させていただいている Rのversionは 4.3.1。RStudioは 2024.04.2+764 “Chocolate Cosmos” です。
Plant Species Traits Data
今回のサンプルデータセットの解説ページが以下に。
https://stat.ethz.ch/R-manual/R-patched/library/cluster/html/plantTraits.html
136種の植物について生物学的属性を31変数に格納しているサンプル・データ・セットです。31の属性を眺めてみるとこんな感じ
-
- 数値 3
- 順序付ファクタ 8
- 2値ファクタ 20
属性の上から眺めてみることにいたしました。
第1は、pdiasという変数名。Diaspore mass (mg)だそうな。「散布体重量」と訳したらよいのかな?散布体重量とは、種子や果実「など」の質量。だそうです。軽くて風に乗って遠くまで運ばれるようなものもあれば、重い果実が落ちて動物さんに食ってもらって運ばれるものもあり、「植物種の散布戦略により大きく異なる」みたいです。『筑波大学』様の以下のページを拝見すると散布体のあれこれと散布戦略のいろいろについてまとまってました。
第2は、longindexという変数名。Seed bank longevityだそうな。植物の種子を保存したときの寿命(発芽可能な)の「インデックス」であるようです。「種子寿命」については、『農研機構(通称)』様の
(研究成果) 適切な環境で保存すると、種子の寿命はどのくらい?
というプレスリリースが素晴らしいです。なお、『農研機構(通称)』は正式名称が長すぎるみたいで(通称)をお使いのようです。「植物の種を保存している組織」でもあるみたいですが、ただ冷蔵倉庫に仕舞っておしまいではないみたい。種子には発芽できる種子寿命があるので、それを念頭に発芽試験を定期的に実施し、発芽率を計測し、発芽率が落ちてくると再度「種」を取得することを繰り返しているみたいです。米とか、麦とかになると数万ロットといった発芽試験回数を繰り返しているみたい。米は元産地によって大分種子寿命が異なるみたいです。なお、「推定種子寿命」についても定義があり、以下引用させていただきます。
-1°C、湿度30%の環境下で保存した場合に、初期発芽率の85%を維持できる年数。
だそうな。リリースに掲載されている中では、キュウリの127.1年(推定、検査ロット数835)というのが印象深かったです。キュウリはシブトイ?これをみると古代のなんちゃらから芽が出たというのはかなり稀な確率的事象であることが理解されます。
ううむ、調べていると植物素人のお惚け老人には知らん事ばかりで、面白いんだけれども、このペースであと29項目をあたっていくだけで数日はかかりそう。たった2つで止めて、サンプルデータの処理に移ります。
まずは生データ
まずはサンプルデータをロードするところから。今回も clusterパッケージの中のデータなので、パッケージをロードしておかなければなりませぬ。
上をみると、変数 pdiasとlongindexの後にまだまだ大量の変数が続いていることが分かります。
なお、今回のサンプルデータの各行(観測値、各植物に対応する)には英字5文字の略称が付加されてました。こんな感じ。
5文字の略称(頭文字ではない)を136個イチイチ「同定」していくのは英語力のない年寄には結構辛そう。ということでパス。数に負けたな、自分。
なお、サマリをとると以下の如し。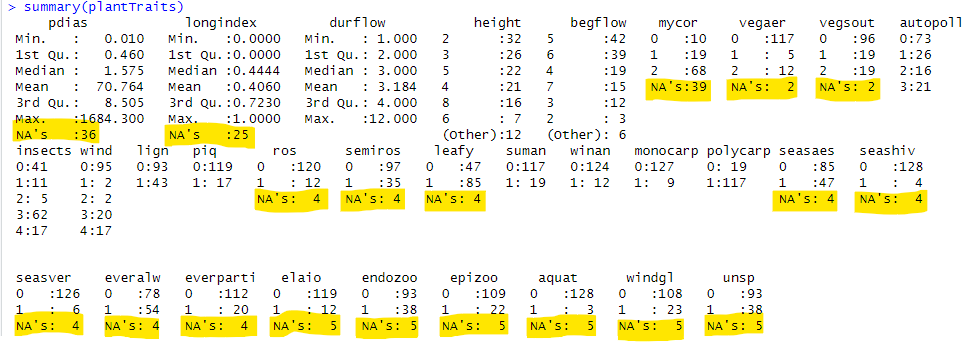
黄色のマーカつけましたが、結構、NA(欠損値)のある変数が多いです。欠損値をよきに計らってくれそうな関数使え、ってこってすか?
処理例
幸いにもこのサンプルデータセットには、処理例が含まれてます。お惚け老人が理解できる範囲の処理の粗筋が以下に。
-
- daisy、Dissimilarity Matrix Calculationをつかってサンプルデータセットの「ファクタ」共を入力に各植物間の「距離」を求める
- agnes、Agglomerative Nesting (Hierarchical Clustering)を使ってクラスタリングを実施
- cutree、Cut a Tree into Groups of Dataを使って、上記でクラスタリングした結果をグループ(ここでは6個)にまとめる
- cmdscale、Classical (Metric) Multidimensional Scalingをつかって、上記のグループを2次元の座標上にプロット(主座標分析?)
という感じであります。知らんけど。
第1、第2のステップを実施したところが以下に。
anges様に描いてもらったデンドログラムが以下に。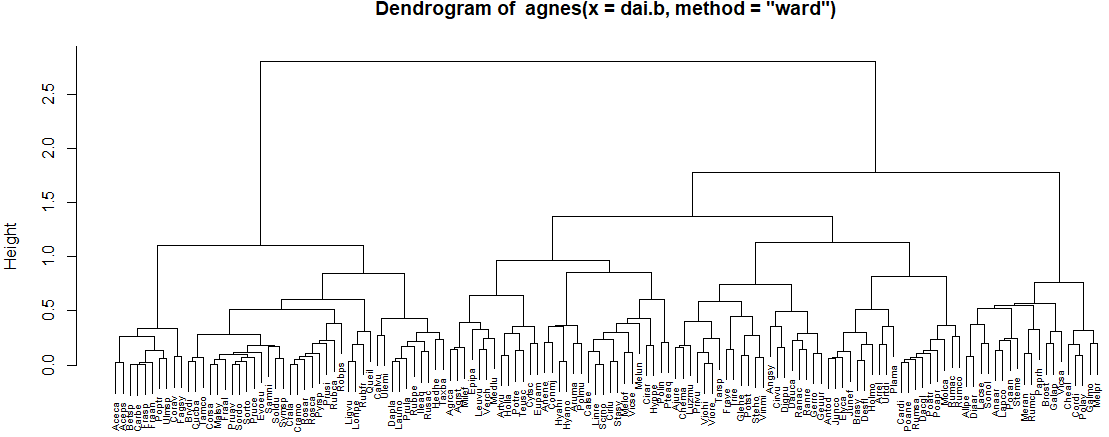
同じく bannerグラフが以下に(なんだか分からんけど、いくつか切れ目?が入っているのが分かる。)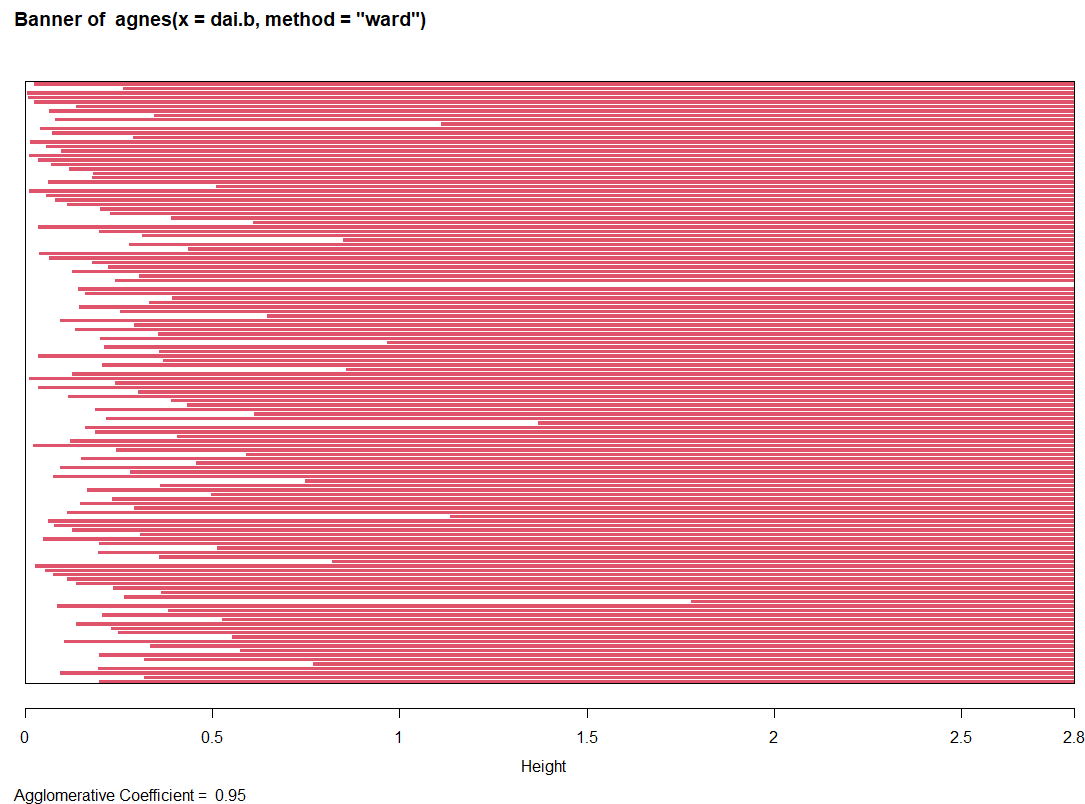
つづく第3、第4の処理ステップが以下に。
6個に分類したグループを、2次元座標にマップしたものが以下に。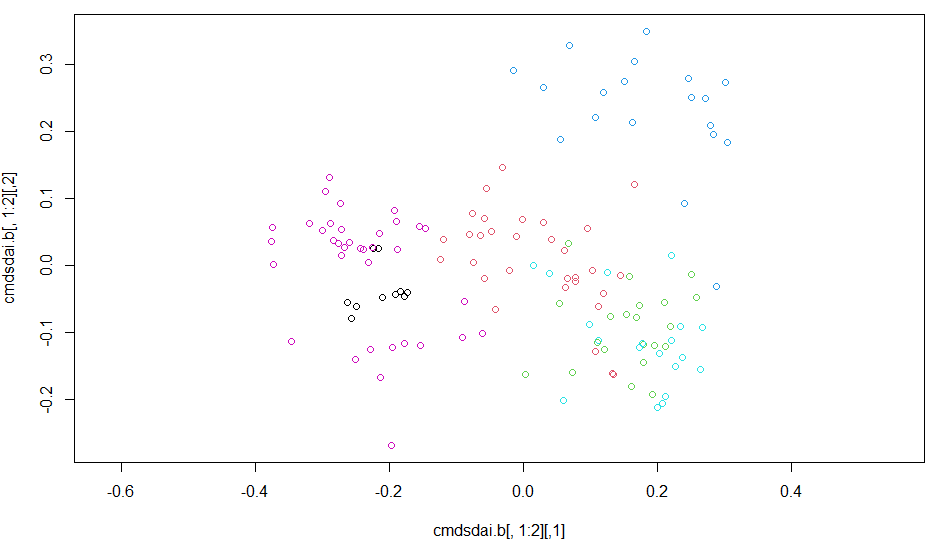
お惚け老人には、なんとなくそれっぽいとしか、言いようないが。。。