MASSパッケージのサンプルデータセットを経めぐってます。大文字優先のABC順なので、前回Animalsの後の今回はBostonです。そういえば古の時代にボストンというバンドいたな。しかしデータセットはボストン郊外の住宅価格です。時期はボストンがバンド活動していた時代に被るのでないかしらん。「プログレ」だけど太古?
※「データのお砂場」投稿順Indexはこちら
Bostonサンプルデータセット
MASSパッケージ内のBostonサンプルデータセットの説明ページは以下です。
Housing Values in Suburbs of Boston
1970年代付近のBoston郊外の住宅価格についてのサンプルデータセットです。14変数に対する506行のデータです。多分各行には具体的な住所が入るのだけれども、サンプルデータのROWをみても具体名はありません。多分、その時代としても「機微に触れる」データが含まれているという認識があったのかとも思われます。最近、別件シリーズで機械学習における「公平性(Fairness)」について学んだバカリなので、お惚け老人も気をつけないとイケないという認識。しかし、昭和の老人、ついやらかさないか?
データセット自体を拝見すると古典的には
重回帰分析の例題?
という雰囲気あり。しかし、最近であれば機械学習向けの例題(ちょっとデータサイズが小さいけど)にピッタシじゃないかと思いました。そう思って調べてみたら、実際にML分野でもBostonは良く使われているデータセットらしいです。「@IT atmarkIT」様の以下の記事(もち日本語)に Boston データセットを使っている機械学習の演習がありました。後でやってみるか?
Boston Housing:ボストンの住宅価格(部屋数や犯罪率などの13項目)の表形式データセット
上記の演習では、Bostonデータセット自体は、カーネギー・メロン大が配布しているデータセットを拾ってくるようになってます。しかし、眺めてみると、R言語のパッケージMASS内に所蔵のデータセットと同一ではないかと思われます(ちゃんと比較してないけど。)
14もある変数のうち、被説明変数は、mdevという御名前の「所有住宅価格の中央値[単位1000ドル]」であるようです。残り13が説明変数ね。後でMLの演習やるときに13変数全てを扱ってみることにして、今回は変数の数を絞って「やりました感」を醸したいと思います。
先ずは生データ
いつもの通りで生データをロードしたところが以下に。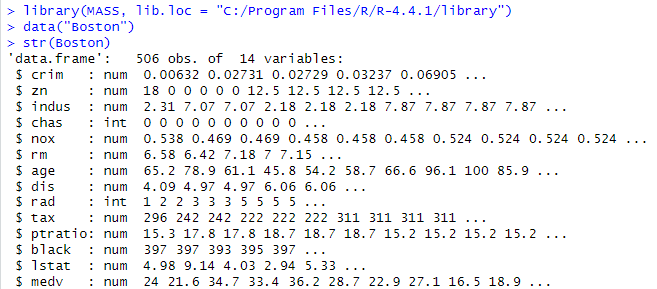
通常のデータフレームです。とりあえず summary をとってみました。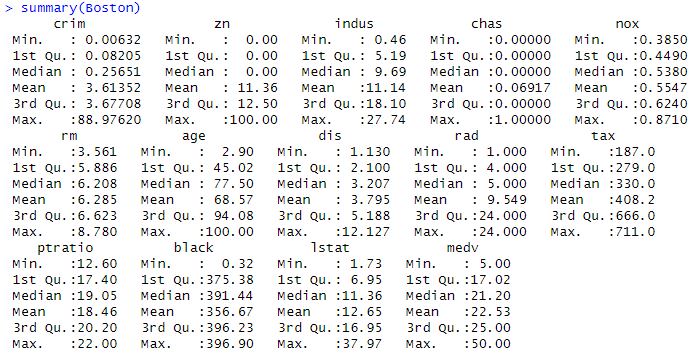
中でちょっと異質なのが、chasという変数です、これはチャールス川に面しているか否かを0と1で表した変数らしいです。チャールス川はボストンの中心市街とケンブリッジ(勿論、米マーサチューセッツ州の方です。ハーバード大やMITが鎮座している街)の間を流れている川です。隅田川みたいなもん。まあ、墨田川花火が見えるというのは地価に影響するか?チャールス川も都会を流れている割に風光明媚かも?
被説明変数である、medvについてヒストグラムを描いておきます。
hist(Boston$medv)
こんな感じ。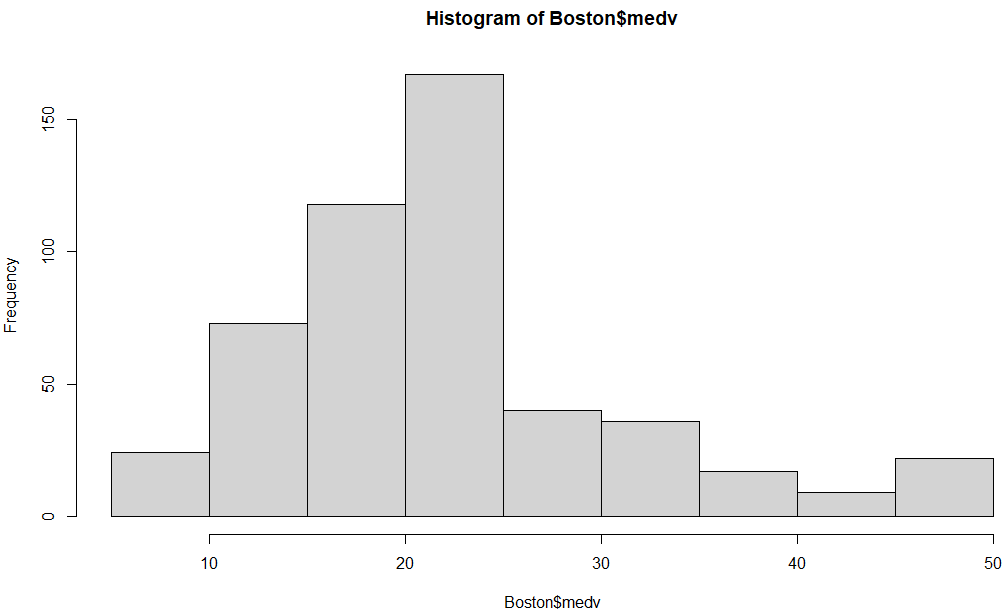
この後、半世紀後の現在の住宅価格は何倍、いや何十倍になっているのか?
いかにも線形回帰
何は無くても以下のようにプロットすれば手がかりはつかめるはず。
plot(Boston)
その結果が以下に。赤枠が被説明変数「medvの行」です。
緑の矢印をつけた、crimは「いかにも反比例」、一方rmは「いかにも比例」関係がある感じがします。
-
- crimは犯罪率
- rmは部屋数
です。まずはそれぞれ1個の説明変数に対する単純な回帰直線を引いてみます。
最初は対 rm
plot(Boston$medv ~ Boston$rm) lm.rm<-lm(Boston$medv ~ Boston$rm) abline(lm.rm, col="red")
プロット結果が以下に。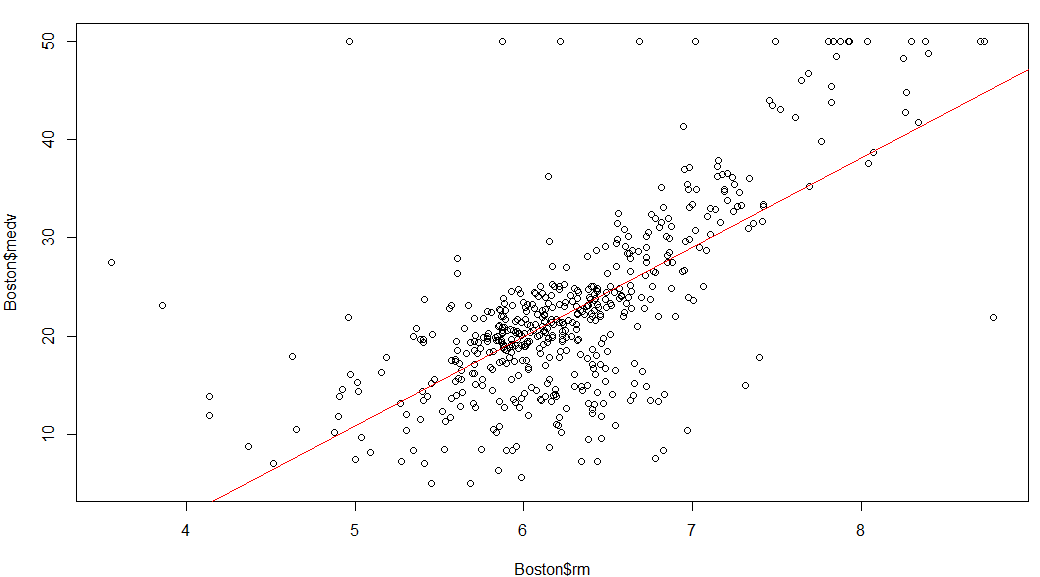
このプロット結果をみると、medvの上限は50000ドルでサチらせた数字じゃないかと思われます。知らんけど。
続いて対 crim
plot(Boston$medv ~ Boston$crim) lm.crim<-lm(Boston$medv ~ Boston$crim) abline(lm.crim, col="orange")
プロット結果が以下に。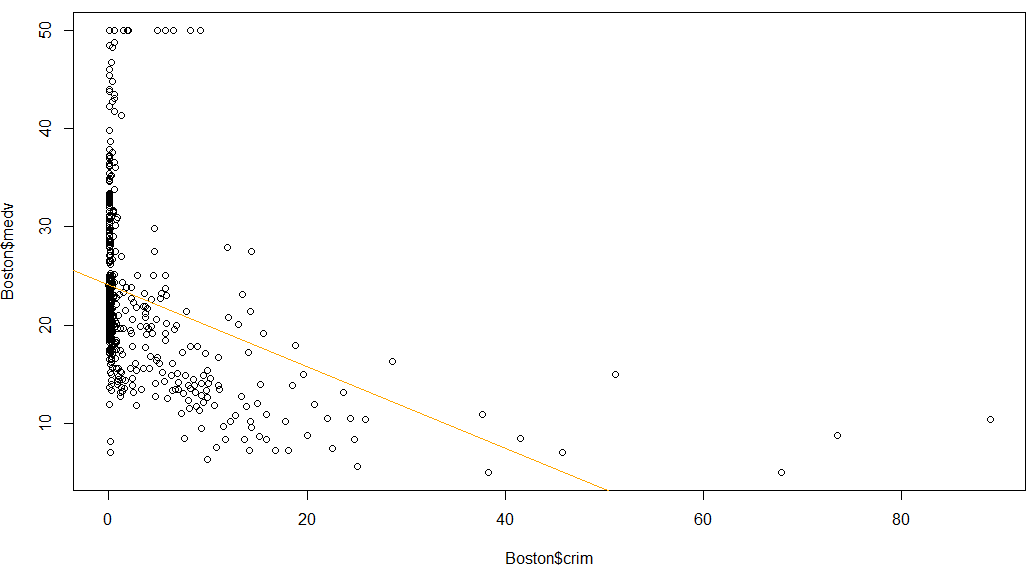
crimが0のところは、満遍なく事例があり、レートが入った後は急速に反比例という感じっす。
上記2つの変数のみの重回帰分析の計算(なんちゃって)が以下に。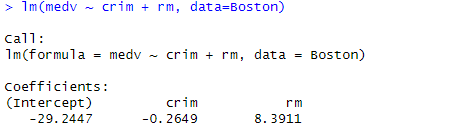
ううむ。まあ、2つだからなあ。後でMLしてみるのがちょっと楽しみだが。大丈夫か?