MASSパッケージのサンプルデータセットを巡回中。大文字優先のABC順。前回はお子様の滲出性中耳炎のデータOMEでした。今回は、米国のネイティブ・アメリカンのピマ族の御婦人方の糖尿病データ Pima です。どうも機械学習で御病気の発症予測を行った「機械学習業界の古典」ともいえるデータらしいです。知らないとモグリ的な?
※「データのお砂場」投稿順Indexはこちら
今回のサンプルデータセット
サンプルデータセットの解説ページが以下に。
Pima族の「インディアン」女性の糖尿病データということみたいです。今時「インディアン」とか言って良いのかよ?と思いましたが、ピマ族の方々が属するコミュニティのお名前にバッチリIndianが入っており、自らそう名乗っておられるみたいです。
Salt River Pima-Maricopa Indian Community
コミュニティの略称、SRPMICです。「インディアン」の「リザベーション」は米国の各地にあり。各地といっても、不毛の荒野であることが多いです。大昔、ある荒野の真ん中のリザベーションに泊り、お酒を買いに町に一軒しかないスーパーに行ったことがあるのです。でもお酒は売ってませんでした。おばさんに聞いたらば「リザベーションの中ではお酒は売ってない。欲しければ隣町まで行け」ということでした。そして隣街まで300km以上あるのでした。どうも不毛の大地に押し込められた人々は仕事もなく政府のお金で生活しており、そのせいでアル中ばかりになった時代があり、自治政府(コミュニティ)が禁酒を決断したみたいでした。自治の権限強力。
ところが、本SRPMICについてはロケーションがバッチリみたい。アリゾナ州フェニックス(人口100万越えの大都市の筈)の中心となるスカイハーバーエアポートの「直ぐ横」です。そういえば、近くには半導体会社も多いです。最近ではオンセミ社が本社をフェニックスからSRPMICの中に移転したと発表していたような。大都市近郊の立地を生かして「稼げている」コミュニティなのではないかと思われます。知らんけど。
例によってGoogleの生成AI、Gemini 2.5 Flash様にPima族についてお教えいただきました。
Gemini様がいろいろお教えくだすっている中で、以下の赤枠の部分に注目したいと思います。
健康関係のプロジェクトをできる財政的な余裕もあったということかいなあ。勝手な想像。
ADAP
そのピマ族の皆さまから取得したデータを処理するにあたって開発されたアルゴリズムがあるみたいです。ADAPとな。Gemini様のお教えが以下に。
おお、現代的なニューラルネットワークの先駆け的なアルゴリズムに使われた「由緒正しい」データセットなのね。そして以下のように、一定の成果が見られたと 。
。
DPF
上記のような機械学習(糖尿病対象)で、重要な変数であるのが、DPFというものらしいです。これまたGemini様のお教え。
子沢山で、親類縁者がまとまって住んでいる(そして糖尿病患者も多かった)ピマ族の方々は、多分、家族歴の調査がやりやすかったんじゃないかと勝手に想像。それにSRPMIC様は立派な病院なども運営されているみたいで、きっと地域のデータを網羅しやすかったのではないかと。
まずは生データ
まずは生データなのですが、Pimaデータセットには以下の3つのファイルが存在してます。
-
- Pima.tr、ランダム選択200名の被験者
- Pima.te、残り332人の被験者
- Pima.tr2、Pima.tr + 説明変数に欠損値を持つ100名の被験者
3ファイルがありますが、2、1、3の順に生データをロードしてみたところが以下に。
最初は、「残り332人の被験者」様のデータ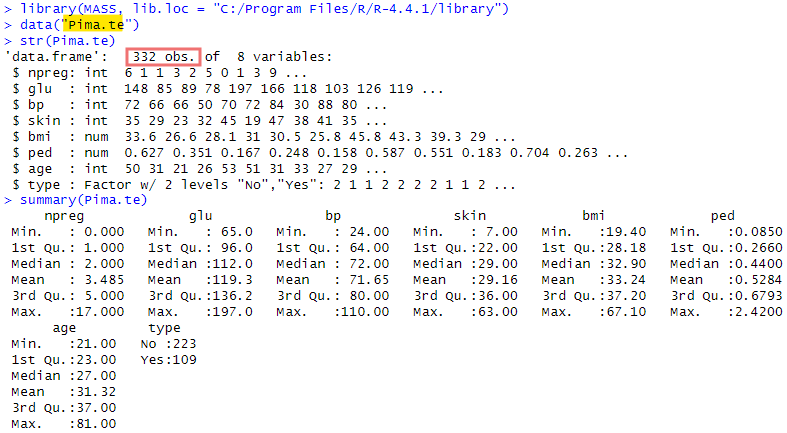
各変数の意味は以下のようでないかと。
-
- npreg 妊娠回数
- glu 経口ブドウ糖負荷試験における血漿ブドウ糖濃度
- bo 拡張期血圧(mmHg)
- skin 上腕三頭筋の皮下脂肪の厚さ(mm)
- bmi Body Mass Index
- ped 糖尿病家系機能 diabetes pedigree function
- age 年齢
- type WHO基準で糖尿病か否か
メインの200名様のデータが以下に。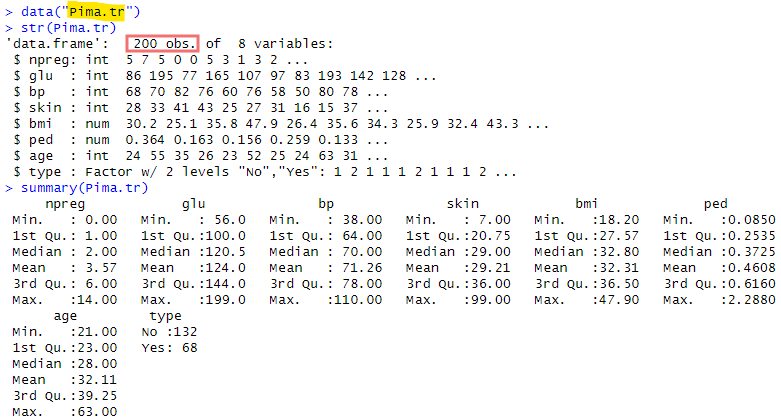
上記の200名様に加えて、一部NAの含まれている被験者様を含めたものが以下に。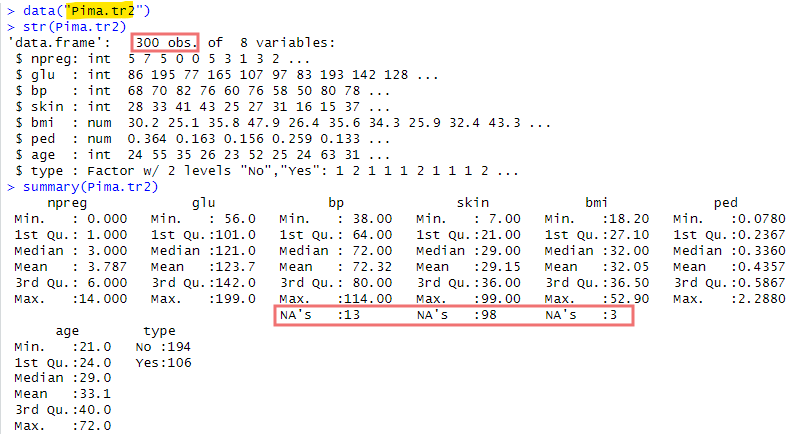
とりあえずヒストグラムを描いてお茶を濁す
今回のデータセットは、ADAPアルゴリズムで機械学習すると、糖尿病発症の予測が「ある程度」できるようなモデルが構築できると分かってます。しかし、お惚け老人はそれをする気力も技術もありませぬ。とりあえず、遠くからデータを眺めてホンワカした感じに浸りたいと思います。その処理が以下に。
Pima.all <- rbind(Pima.tr2, Pima.te) split.screen(figs = c(2, 3)) screen(1) hist(Pima.all$npreg, xlab="number of pregnancies") screen(2) hist(Pima.all$glu, xlab="plasma glucose concentration") screen(3) hist(Pima.all$bp, xlab="diastolic blood pressure [mmHg]") screen(4) hist(Pima.all$skin, xlab="triceps skin fold thickness [mm]") screen(5) hist(Pima.all$bmi, xlab="body mass index") screen(6) hist(Pima.all$ped, xlab="diabetes pedigree function.")
上記の結果のグラフが以下に。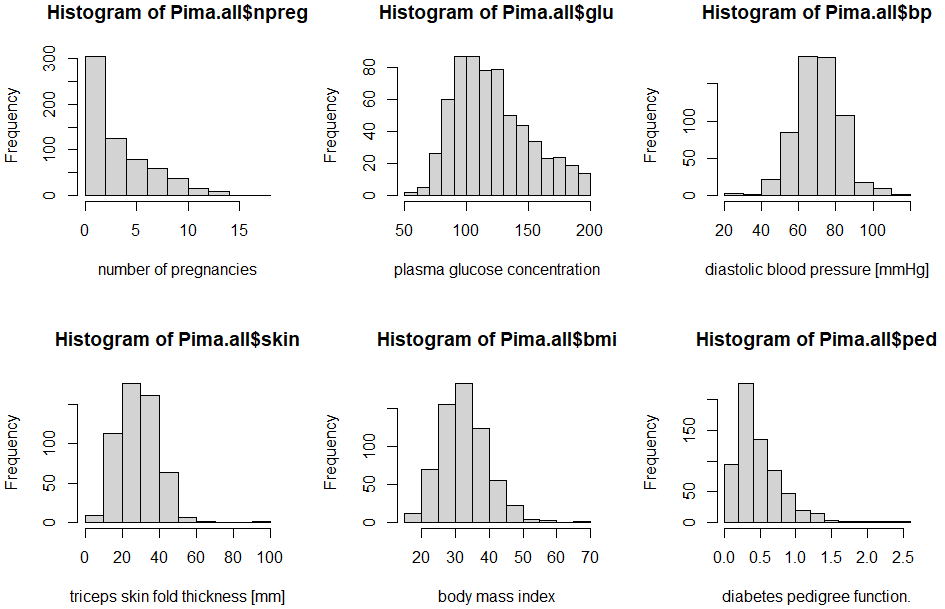
左上のグラフなどみると、極端に子供の数が多い人がおられますな。多分、お年寄りの世代?そして、下の行の真ん中みると、BMI多め。日本的な基準だと、左から2つ以外はみんな基準以上(人のこと言えないが。)