前回は1940年と古いデータでした。今回のデータはWWWねたなので、それほど古いことはないでしょう。でも振り返ると最初にWWW(ワールドワイドウエッブ)にアクセスしたのはNCSA Mosaicというブラウザででした、まだWindows 3.x の時代だったかと。それからすると30年くらいたってますな。今は昔、違うか。
※「データのお砂場」投稿順Indexはこちら
R言語に所蔵されとりますサンプルデータセットをABC順(大文字先)で端から眺めております。今回触ってみるサンプルデータセットは WWWusageというものです。その解説ページが以下に。
見れば、どこかの「サーバー機1台」を介してインターネットに接続している毎分のユーザー数、100分間の時系列データのようです。現代的な感覚だと吹いて飛ぶ?ような数のユーザ数じゃないかと思います。
推測するに1990年代のどこかで測定されたデータではないかと。1990年代、Mosaicを嚆矢として、Netscape Navigatorや、IEなどが続々登場してWWWというものが一世を風靡し始めた時代ですな。。。
この時系列データをいじってみるにあたっては例によって同志社大の先生が書かれている以下のページを参照させていただきました。
頭の方に名言が書いてあったので、1か所引用させていただきます。
時系列データを分析する際には、まずデータの変動がランダムウォークで表現できるか、そうでないかを調べることが重要である。
専門家は「単位根検定」と呼ぶみたいデス。知らんけど。
まずは生データ
生データをみてみるとこんな感じ。

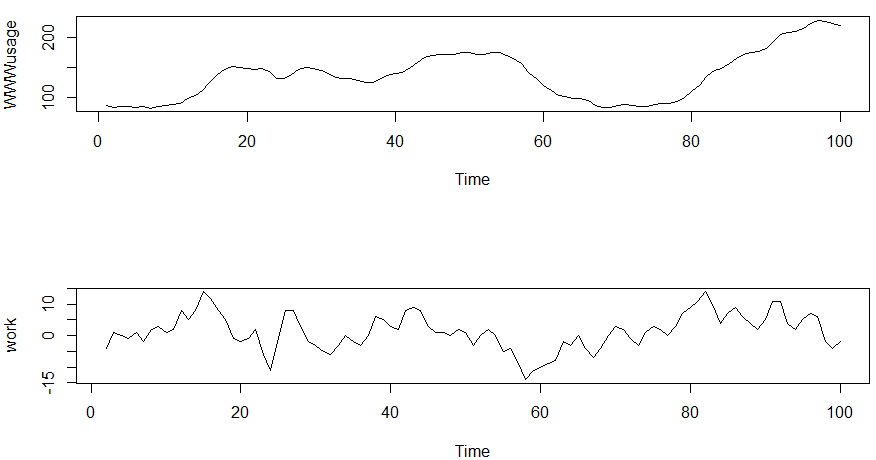
時系列データの「素の」プロット結果が以下に。横方向は時間(分)で、縦方向がユーザ数なのだと思います。100人を下回るあたりから、200人を上回るあたりまで時間によって変動しておる、と。
ランダムウオーク?
さて、さきほどの引用にもとづき、「このデータ変動はランダムウオークだ」という「帰無仮説」を「棄却」できるかどうかR様に計算してもらうと

p-value = 0.9385 全然「棄却できへん」ということで良いのかな?ほんとか? 棄却できないだけでランダムウオークだとも言えないところがもどかしいデス。でもいつWWWを見て、何時見るのをやめるかなんざ、100人、200人の人がいたらみなバラバラ、ランダムじゃないかと体感が教えてくれます。まあ、夜になると寝る人が多くなるし、ご飯食べる時間帯など「生活周期のトレンド」もあるだろうけれども、たかだか100分を切り取ったデータではそういうトレンドは分かりますまい。
説明の処理例
処理例では、差分をとったグラフも書いてました。処理は以下に。
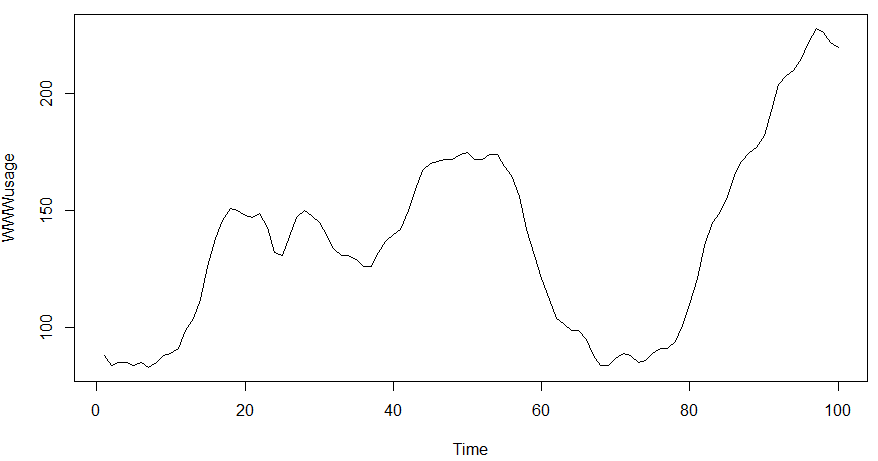
結果グラフは冒頭のアイキャッチ画像に掲げたとおりです。ユーザ数はゆるやかに山になったり谷になったりしてますが、差分をとると0を中心に増えたり減ったりしておりますな。ランダムウオーク、酔歩ってやつ?
その後も処理例は続いているのですが、その注釈に
Not run
などと書かれています。そういわれると動かしてみたくなるので、つい動かしてしまったところを以下に並べてしまいました。私は何だかわかってません。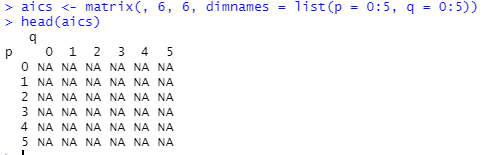
途中でNaNが出来てるみたいですが、そういわれてもな~。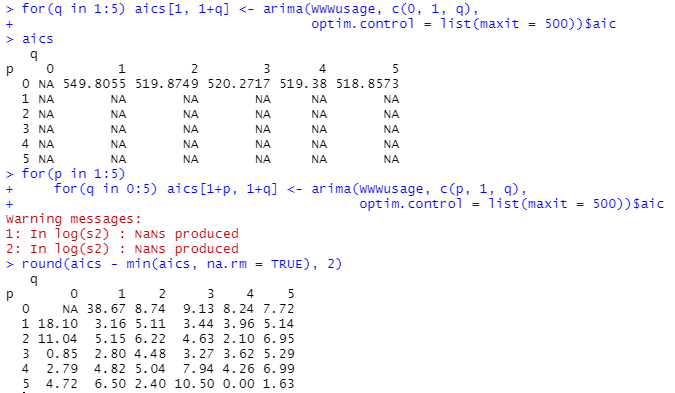
ARとかARMAとかARIMAとか勉強しないと分からんデス。何時になったら?