ここ暫くプロファイラなど使っておらず。すっかり使い方を忘却しております。今回は、open, read, writeなど基本中の基本?のシステムコールのリハビリをしながら、これまた一番基本の gprof を動かして関数が何回呼び出されているんだか勘定してみたいと思います。数えたら早くなるってもんでもないケド。
※ソフトな忘却力 投稿順 index はこちら
※実験(リハビリ?)に使用したのはRaspberry Pi 3 model B+機であります。OSは以下のバージョンの32ビットRaspberry PI OS “buster” です。CoreはArm Cortex A53。gccのバージョンも以下に
-
- Linux Pi3 5.10.103-v7+ #1529 SMP Tue Mar 8 12:21:37 GMT 2022 armv7l GNU/Linux
- gcc (Raspbian 8.3.0-6+rpi1) 8.3.0
実験に使ったソース
これみよがしに無駄なソースが以下に。やっていることは、カレントディレクトリにある ”testin.txt” という名のファイルを “testout.txt” にアペンドする、だけです。open して read して、writeして、終わったら close っす。ミソというほどでもないですが、頭の方にあるTBUFSIZという定数の値をテキトーに換えるとシステムコールに渡すバッファの大きさが変わります。すると
呼び出し回数とか、実行時間とかが変わる
という点です。ファイルが小さかったらほどんど無視できる実行時間です。
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#define TBUFSIZ (16)
char tbuf[TBUFSIZ];
int read000(int fdr) {
return read(fdr, tbuf, TBUFSIZ);
}
int write000(int fdw, int numRD) {
return write(fdw, tbuf, numRD);
}
void copy000(int fdr, int fdw) {
ssize_t numRD, numWR;
int cnt = 0;
while ((numRD = read000(fdr)) > 0) {
numWR = write000(fdw, numRD);
printf("count: %d (%d) -> (%d)\n", cnt++, numRD, numWR);
}
}
int main(int argc, char** argv) {
int fdr, fdw;
if ((fdr = open("testin.txt", O_RDONLY)) < 0) {
perror("ERROR: open to read.");
exit(1);
}
if ((fdw = open("testout.txt", O_WRONLY|O_CREAT|O_APPEND, 0644)) < 0) {
perror("ERROR: open to write.");
exit(1);
}
copy000(fdr, fdw);
close(fdr);
close(fdw);
exit(0);
}
まずはバッファサイズを16バイトでやってみる
コンパイルして、実行しているところが以下に。-pgが gprof 使うためのオプションです。gprofはプロファイラといっても gcc が埋め込んでくれるプロファイリング用の細工の出力結果を後で集計するためのツールみたいな感じです。-pgつけてコンパイルしたファイルを実行すれば裏でプロファイリング結果がファイルに落ちてます(だから間違ってもリリースビルドにつけてはイケないです。)
なお、後で見ますがオプティマイズするとソース上では関数にしたつもりでも、インライン化されたりして消えることも多いです。消えたもんは集計対象になりません。今回のソースは簡単で、オプティマイズすると全ての関数呼び出しが「消える」ので、ここはワザと -O0 しています。
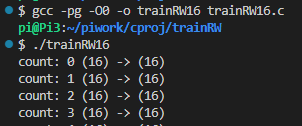
上記のcount: のところはプログラムの中で、リードライトする度にわざわざ出力している情報です。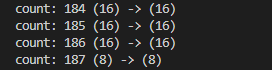
バッファサイズが小さいので合計188回(0はじまりなので。なお最後の1回は8バイト)もread/writeしとりますなあ。
その様子を gprof に聞いてみます。まずは -p オプション。もっと時間のかかるプログラムであれば、各関数毎にかかった時間が一覧できてうれしいのですが、なにぶん短いプログラムなので皆ゼロ秒です。唯一の情報らしい情報がcallsに記されている呼び出し回数ですな。上記でカウントしたとおりwriteは188回です。readは最後の読み出し、EOFだったの回があるので189回読んでいるみたいです。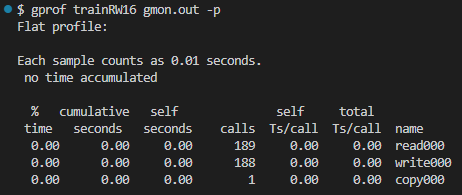
-p オプションではどの関数がどの関数を呼んでいるのだか、コールグラフってやつは見えません。-q オプション使ってみます。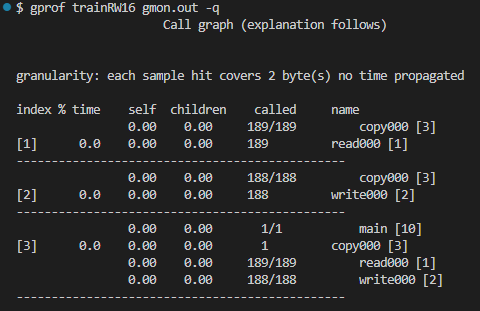
こうすると表示される行数が相当多くなりますが、呼び出し、呼び出されの関係が一目瞭然かと。
つづいてバッファサイズを増やしてみる
バッファサイズをケチらないで増やしてやれば速度は改善される筈。といってドンと渡しすぎるとプロファイル結果がツマラナクなるので、テキトーにお茶を濁して1024バイトにしたものが以下です。
まずはビルドして実行。3回の繰り返しで終わりました。
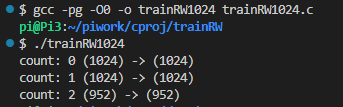
今回は、最初から -q オプションで見てみます。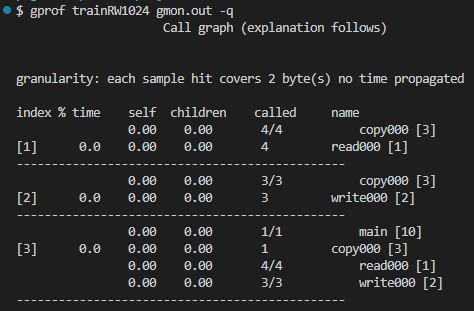
16バイトの時と比べると、ダンチで回数少なくなりましたな。よかった。
-03でオプティマイズすると
この規模のプログラムだと、オプティマイズするとプロファイリングする対象が無くなってしまうので最後にとっておきました。オプティマイズしたところが以下に。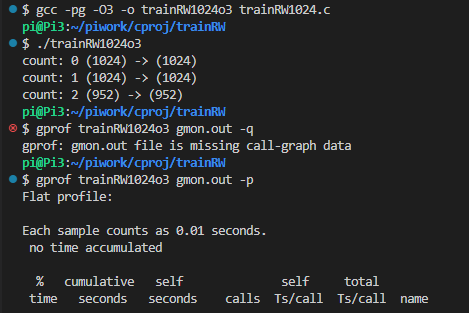
-q しても、コールグラフなど無いと怒られてしまいます。-pの結果もほとんど意味なし。
まあ、実際には重くて長いプログラムをオプティマイズした後で、しみじみ味わうためのプロファイラなので、結果がショボいということは普通ないんでありますが。