R言語のサンプル・データセットをABC順(大文字先)で端から眺めております。今回のデータセットは espoh、「食道がんの症例対処研究」のデータだそうです。その要因として酒とタバコの摂取量を想定するもの。ちょいと込み入ってます。今回は処理例が提示されているので、それをつかえば処理はできると。
※「データのお砂場」投稿順Indexはこちら
esoph
今回のサンプルデータセットの解説ページは以下です。
Smoking, Alcohol and (O)esophageal Cancer
例によって1980年以前の古いデータです。フランスでとられたもの。データセットは、
case-control study
のためのものみたいです。case-control studyってなんじゃらほい?状態なので調べてみました。日本疫学会様の以下のページを参照させていただきました。
上記ページから1か所引用させていただきます。
疾病の原因を過去にさかのぼって探そうとする研究。目的とする疾病(健康障害)の患者集団とその疾病に罹患したことのない人の集団を選び、仮説が設定された要因に曝露されたものの割合を両群比較する。
要因としては以下を想定しているようです。
-
- 年齢、6層にクラス分け
- アルコール消費量、4層にクラス分け
- タバコの消費量、4層にクラス分け
上記の要因について、cases(疾病に罹患)とcontrols(疾病に罹患していない)を数えておる、ようです。
まずは生データ
いつものように、まずは生データを自力で見ていきます。データの形式は data.frameです。上記3つのグループの組み合わせにたいして、cases数とcontrols数を列挙してあるようです。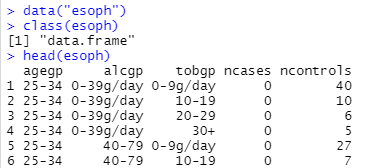
上記のようにhead()で見るよりも、Rstudioの場合、大域変数の表示ウインドウがあるので、そちらを見た方が何層に分けているなどわかりやすい気がしないでもないっす。
summary()とれば、層別の件数は一目でわかります。cases数と、controls数は平均などとられてしまっているので、意味なしかと。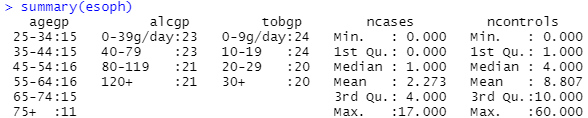
cases数とcontrols数の総数を求めてみると以下のようです。
そのうち、一番、酒もタバコも摂取量が少ないレベルの件数を数えてみたものが以下に。
総数から上記の件数を引くと、多くのcasesでは、層別のレベルが高いような気がしないでもないです。
とりあえず、各要因毎単純件数の箱ひげ図を描いてみました。
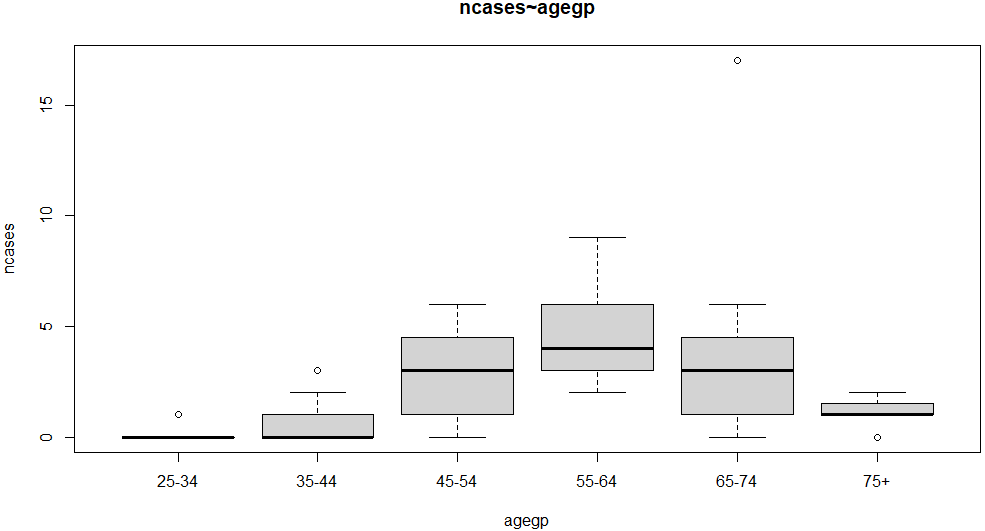
まずは対年齢のcases。処理方法が以下に。
boxplot(ncases ~ agegp, data=esoph) title(main="ncases~agegp")
グラフが以下に。もともとの件数が凸凹がある単純数なので、この箱ひげ図はあまりあてになりません。知らんけど。
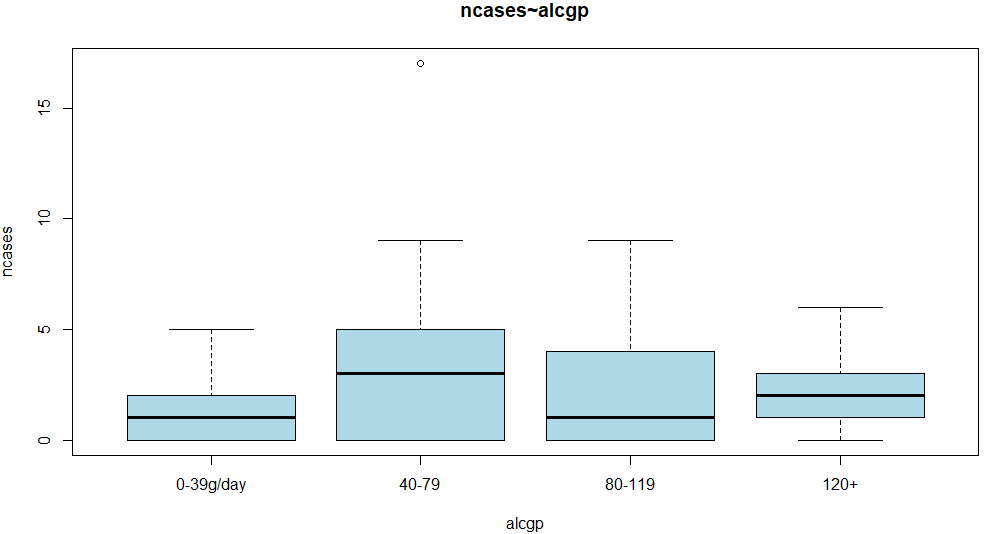
続いて酒の摂取量で箱ひげ図。処理が以下に。ちょいと色を変えてみました。
boxplot(ncases ~ alcgp, data=esoph, col="lightblue") title(main="ncases~alcgp")
これまた、この図ではなんだかな~
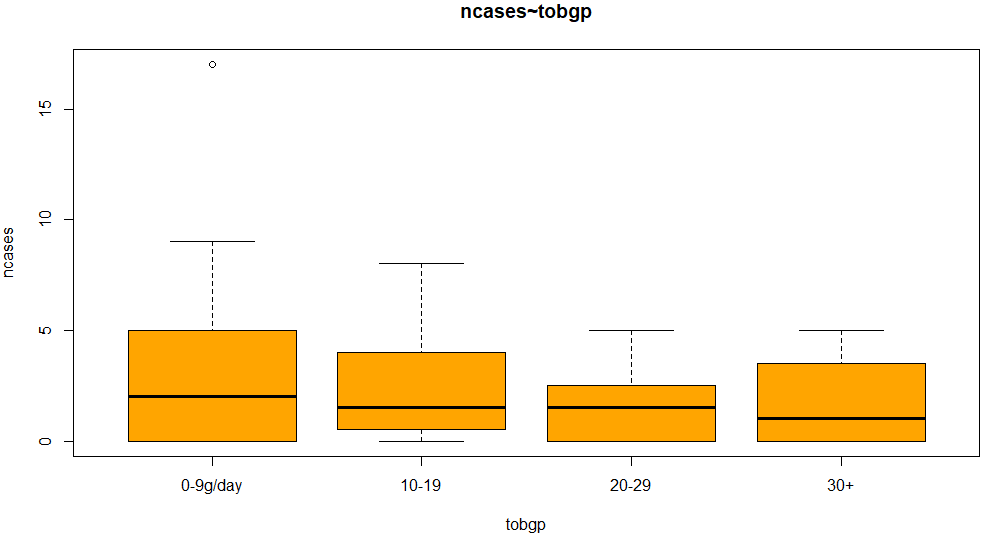
続いてタバコの摂取量で箱ひげ図。処理が以下に。
boxplot(ncases ~ tobgp, data=esoph, col="orange") title(main="ncases~tobgp")
グラフが以下に。これではタバコの摂取量とあんまり関係ないように見えてしまうぞなもし。いいのかそいうことで。
処理例に記載の処理を行ってみる
折角、解説ページに処理例が記載されているので、それをそのままやってみることにいたしました。以下の処理関数を使用してます。
-
- glm(), Fitting Generalized Linear Models
- anova(), analysis of variance
上記の使い方についてはR素人がとやかく書きますまい。いつもお世話になっております。同志社大の先生様のページに解説記事があります。
まずは glmかけて、anovaしている最初のモデル。
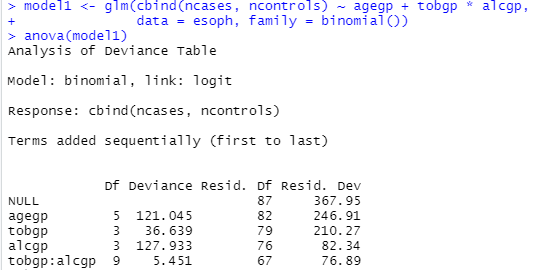
計算はできたけれども、結果はなんだかな~。素人にはわけわからないデス。「要因の影響はない」ことは無い、ってことでいいんでしょうか?
つづいてglmでモデルの係数を求めるもの。unclass()で層別のレベルを単なる番号にしてくれるのね。
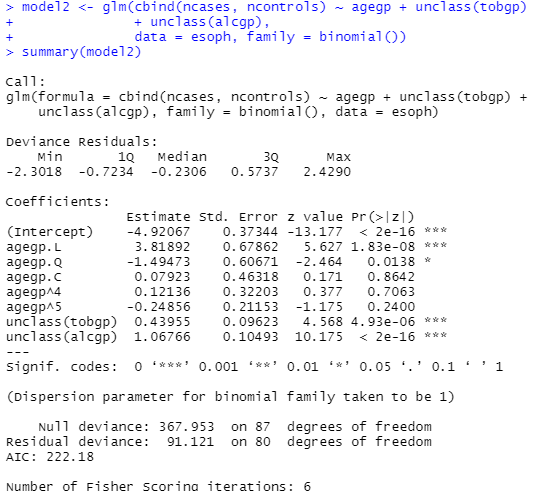
Prの値を見ていると、酒やタバコの影響はないことはないみたいだけれども、年齢に関してなんだかいっぱい係数があるのがこれまたわかりませぬ。なんじゃらほい。
最後にようやく素人目にもわかりやすい結果がでるものがありました。モザイクプロットの描画です。横方向が年齢グループで、左端が25-34歳グループ、右端が75歳以上グループです。縦方向がお酒のグループで、上が一番少ない0-39g/日グループ、下が一番多い+120g/日グループです。縦横の分後の各エリアの中で左から右にタバコ量のグループが並んでいます。左が小、右が大です。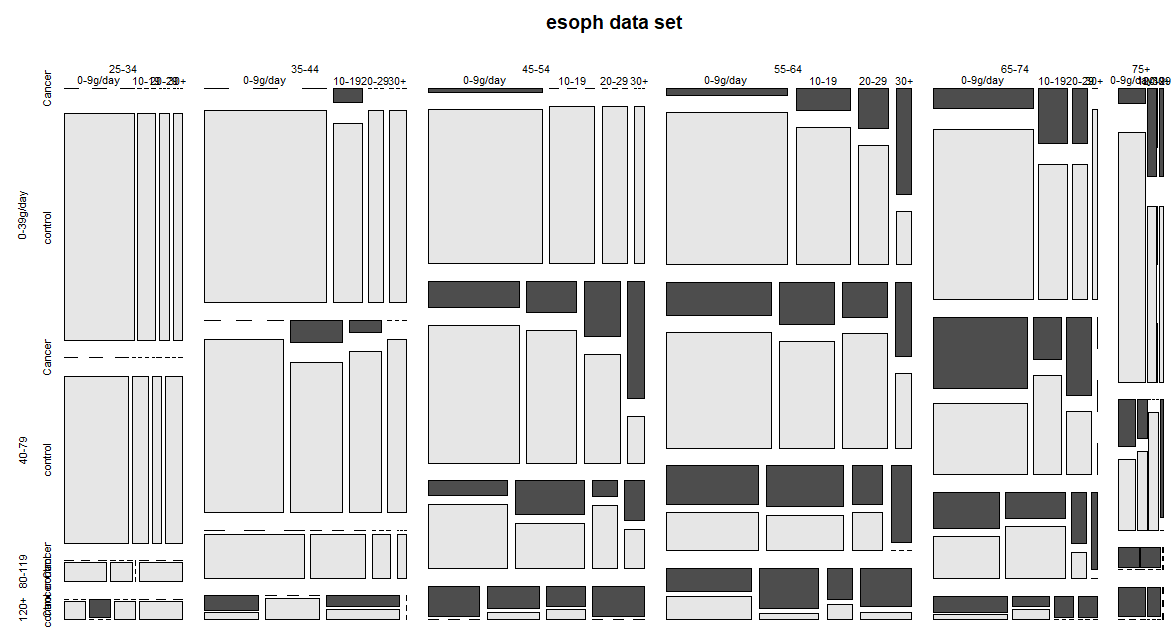
これをみるとようやく、右下に向かうほど罹患する割合が高くなりそうな雰囲気が感じ取れますです(感じるだけだけれども)。でもさ、こういう結果になるのは計算しなくても皆知っている気がします。
ちゃんと統計勉強しないと、ANOVAの結果を正しくできませんな。でもいつやるの?