前回SQLクエリの結果でドロップダウンリストを作ったので、今回は選択結果にもとづいてデータベースから実データを抽出してみたいと思います。古いデータなのですが、各種マイコンとセンサを使って取得した数万件くらいのデータです。とりあえずの今回はダッシュボードのテーブルに列挙してみます。
※「ブロックを積みながら」投稿順 index はこちら
※動作確認にはRaspberry Pi 3 model B+のRaspberry Pi OS(32bit)上にインストールした以下を使用しています。
-
- Node-RED v2.0.5
- node-red-dashboard 3.2.0
今回実験のNode-Redフロー
今回実験のフローは、前回のフローの末尾に付け足して作ってみました。下記フローで上側で一直線に並んでいる4ノードが前回フロー部分で、下側の5ノードが今回部分です。
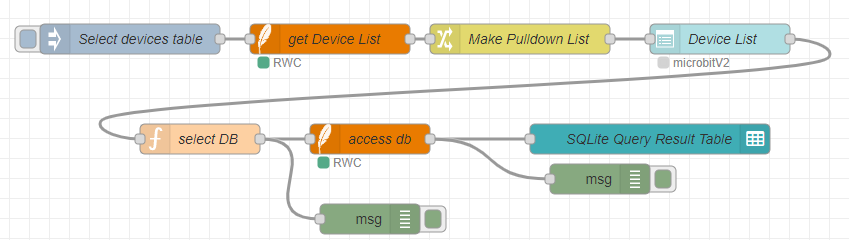
前回のフローはダッシュボードのプルダウンリストが末尾で、プルダウンリストにはデータベースにデータを記録したのであろうマイコン名がリストされてます。
今回はこのプルダウンリストからマイコン名を選択すると、該当のマイコンの測定データから「温度」の記録のみを抜き出してテーブルに表示するという段取りです。
本来はマイコン名だけでなく、データの種別、温度だけでなく湿度とかも選択、また、対象期間での絞り込みなども加えたいものですが、いまのところはマイコン名での検索のみです。
各ノードの設定
今回作成の後半部分の最初は、select DBと名前を記した function ノードからです。ここで SQL文を組み立ててます。こんな感じ。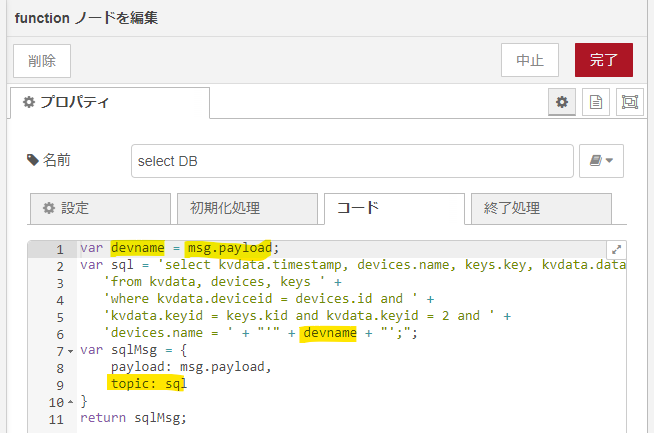
上流のプルダウンリストからは、msg.payloadにマイコン名文字列が流れてくるので、まずそれを捕捉し、devices.nameで絞りこむ部分にハメこんでいます。他の部分はキメウチです。これによって生成されるSQL文は以下のようです。
select kvdata.timestamp, devices.name, keys.key, kvdata.datafrom kvdata, devices, keys where kvdata.deviceid = devices.id and kvdata.keyid = keys.kid and kvdata.keyid = 2 and devices.name = 'microbitV2');
生成したSQL文は、msg.topicに載せて下流に流します。
なお、既存のデータベーステーブルの構造をご理解いただくために、上記で扱っている3テーブルのスキーマを以下に示しました。kvdataがセンサデータの記録の本体。keysが記録したセンサ等データの種別を保持する台帳、devicesが測定を行っているマイコン名の台帳です。
CREATE TABLE `kvdata` (
`timestamp` TEXT,
`deviceid` INTEGER,
`keyid` INTEGER,
`data` TEXT
);
CREATE TABLE `keys` (
`kid` INTEGER,
`key` TEXT,
PRIMARY KEY(`kid`)
);
CREATE TABLE `devices` (
`id` INTEGER,
`name` TEXT,
PRIMARY KEY(`id`)
);
さて、本題のsqliteノードは、例によってアクセス先のデータベース・ファイル名を指定しているだけです。上流からmsg.topicに載って流れてくるクエリを処理するのみ。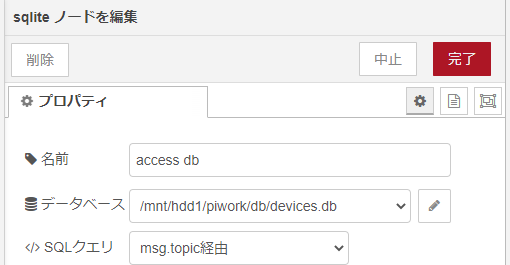
上記のクエリの結果は、selectされたデータののったJSON配列の形で到来します。今回処理のケースではクエリの指定により各レコード4フィールド、1万レコードくらいのデータが到来します。
tableノードの設定の上の方が以下に(ずらずらとまだ下に続いております。)
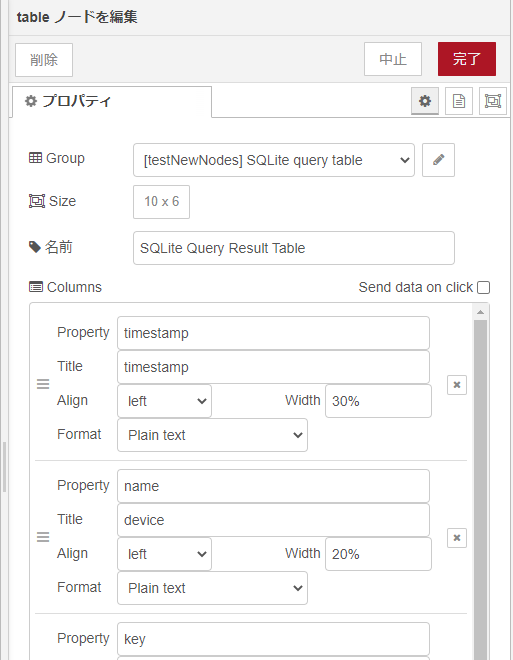
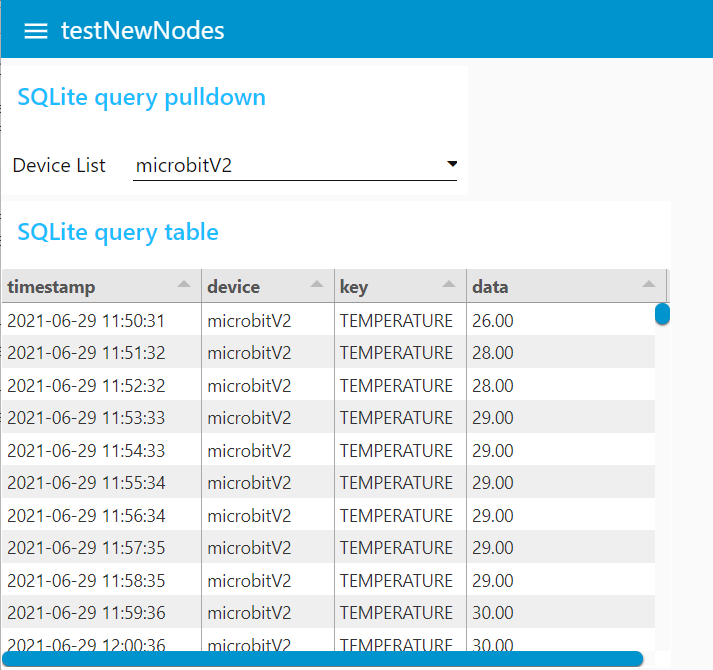
クエリの結果
microbitV2を指定したときの様子が以下に。1年半以上前のデータです。ほぼ1分ごとにmicrobitV2のオンボードの温度センサで測った温度データみたいです。精度もないのに温度(摂氏)が小数点以下2桁00になっているのは猪口才だな。
とりあえずデータベースにクエリを掛けられる雰囲気が出てきたので、次回以降もっと使いやすくすべく、SQLを勉強していきたいと思います。