過去http関係のノードを試用してみましたがNode-RED側がサーバになるものでした。今回からhttp requestノードを使ってWeb上のhtmlドキュメントをGETし、パースして所望の情報を取り出すという一連の流れを練習してみたいと思います。初回は当サイトの過去記事のテーブルを取り出してその内容を取り出すもの。
※「ブロックを積みながら」投稿順 index はこちら
※動作確認にはRaspberry Pi 3 model B+のRaspberry Pi OS(32bit)上にインストールした以下を使用しています。
-
- Node-RED v2.0.5
- node-red-dashboard 3.2.0
今回実験のフロー
今後手を入れていこうと思っているのですが、今回時点でのフローは一直線です。
-
- とりあえずWebからGETするurlはInjectノードで指定
- http requestノードで上記指定のhtmlドキュメントをGET
- http (parse)ノードでGETしたhtmlドキュメントをパースして所望要素を抽出
- functionノードで抽出要素の絞り込み
- とりあえず出力結果をDebugノードで観察
このようなフローが以下に。
これからいろいろ手を入れていけそうな部分が満載の「スタート地点」であります。
各ノードの設定
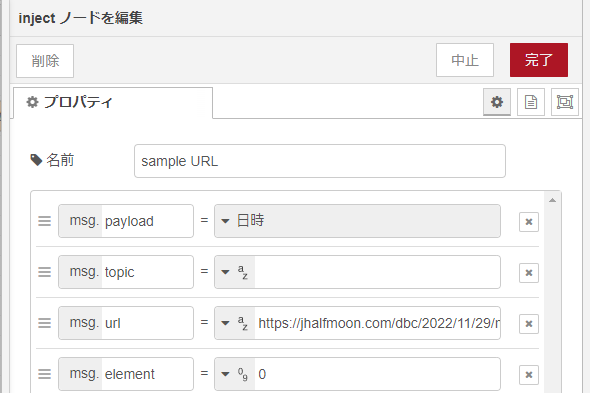
最上流のInjectノードの設定が以下に。このうち、以下2つのプロパティは 下流のhttp request ノードが利用するものです。
-
- msg.topic
- msg.url
msg.url にurlが指定されていると、http requestノードはそれに対して動作します。またhttp requestノード内にurlをハードコードした場合、一部を「マスタッシュ記法」、{{{ }}}で囲う記法、で指定でき、そのとき使用するのがmsg.topicプロパティです。今回は msg.urlにアクセス先(当サイトの過去記事です)を指定しているのでmsg.topicの出る幕はありませぬ。
また、一番下に msg. element というプロパティがありますが、これはより下流のfunctionノードで要素の絞り込みに使うために追加した独自プロパティです。
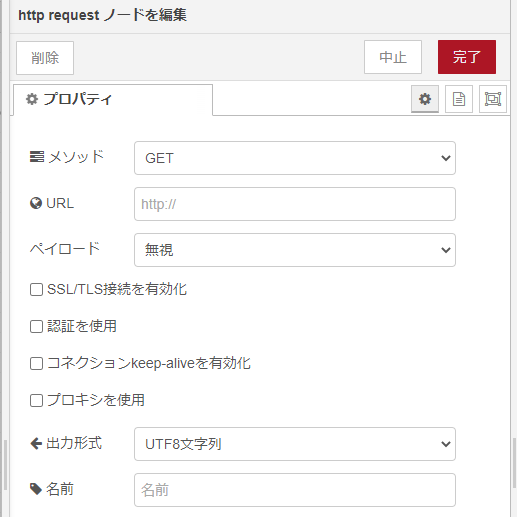
実際にネットにアクセスして、その結果を受け取る http requestノードの設定が以下に。といってデフォルト設定そのままっす。URLのところに薄く”http://”という文字が見えてますが、ここはブランクということで。
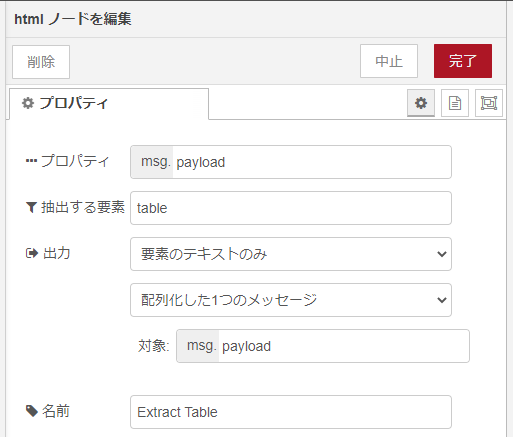
さて上記でWebから拾ってきたhtmlドキュメントをパースするのが次のhtml(parse)ノードです。ドキュメント本体はmsg.payloadに載っています。今回はそこから table 要素を取り出す設定です。取り出し時にはhtmlタグを含んだ形式でも可能ですが、今回はテキスト部分のみを取り出してます。また、複数の要素が見つかった場合、配列として取り出してます。
上記に引き続くのが function ノードです。ここでは最上流のInjectノードで載せられたmsg.elementプロパティを使って、パース後のpayloadに載っている配列の要素0のみを取り出すという操作を行ってます。まあ、本当は配列かとか、要素はいくつあるんだとかチェックが必要でしょうが、今回は形だけ。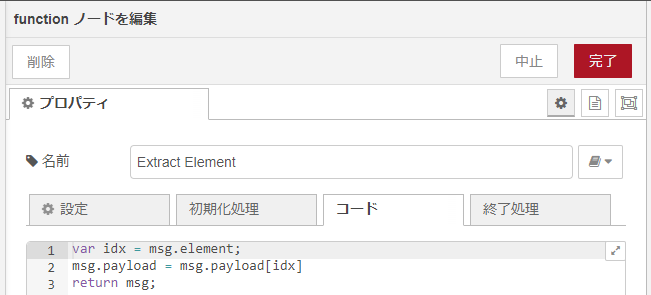
実行結果
さて、デバッグウインドウに表示された実行結果が以下に。payloadになにやら文字列がダラダラと搭載されているのが見えますか。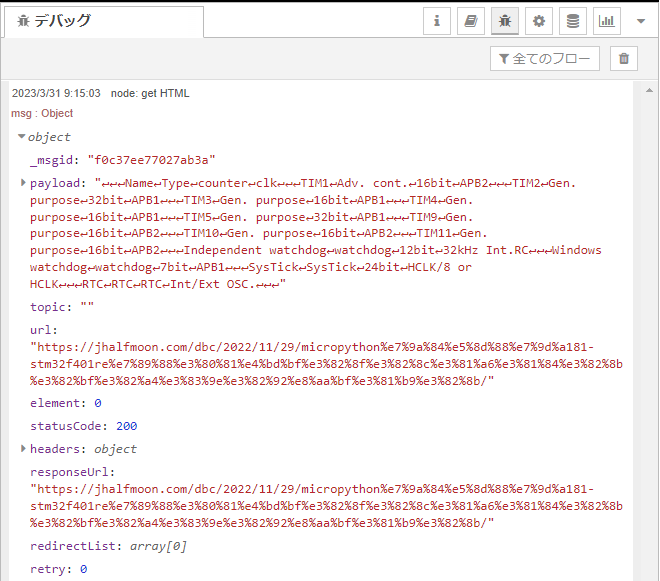
上記の結果は、本サイトの以下の過去記事掲載のテーブルです。
MicroPython的午睡(81) STM32F401RE版、使われているタイマを調べる
上記ページの中央付近、「STM32F401RE搭載のタイマ」の項の表がそれです。
「フローの原型」はこんなものか?先は長そうだな。