前回はWebからとってきたhtml文書の中の<table>要素を抽出してNodeRedダッシュボードに表示してみました。今回はCSSセレクタを使ってより細かいレベルで要素抽出を行ってみたいと思います。フロントエンドがお得意の人には簡単なんだろうが、低レベルプログラミングな年寄には慣れない高水準だなあ。
※「ブロックを積みながら」投稿順 index はこちら
※動作確認にはRaspberry Pi 3 model B+のRaspberry Pi OS(32bit)上にインストールした以下を使用しています。
-
- Node-RED v2.0.5
- node-red-dashboard 3.2.0
今回実験のフロー
今回のフローは前回フローをコピーしてその後半をぶった切ったもの、であります。
HTML(parse)ノードの設定を変えながら、抽出できる部分を後続のDebugノードで観察するだけのもの。
ターゲットのHTML文書
前回と同じ本サイト内の過去記事(2022年11月)をターゲットにしています。今回抽出を試みている部分の構造が以下に。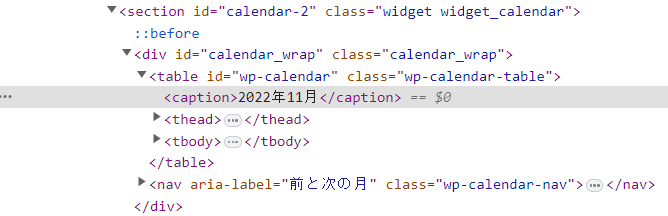
本文書にも表示されておりますがナビゲーション用の「カレンダー」部分です。パソコン等では右側に表示、スマホではかなり下の方に表示されている筈。
HTML(parse)ノードの設定
設定画面が以下に。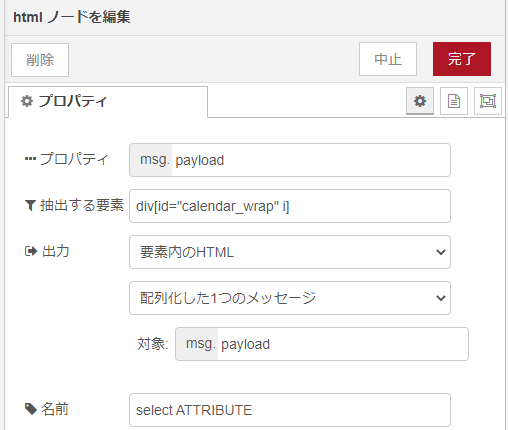
上記の「抽出する要素」のところにCSSセレクタを記入して抽出できた要素を逐一確認していきます。なお、
-
- CSSセレクタの構文を間違えると、下流のDEBUGノードにはエラーを示すmsgが流れてくる。
- CSSセレクタにヒットする要素がない場合は、ゼロ要素数の配列がmsg.payloadに載ってくる。
CSSセレクタと抽出結果
カレンダの中の<caption>に向けて上位から要素を「ドリルダウン」してまいります。
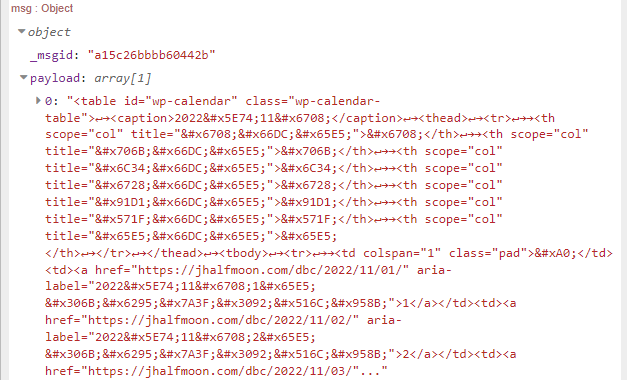
div[id="calendar_wrap" i]
まずはid属性に”calendar_wrap”をもつ要素はページ内にここしかない筈なのでそれを指定してみます。iは大文字、小文字関係なしの御印らしいっす。
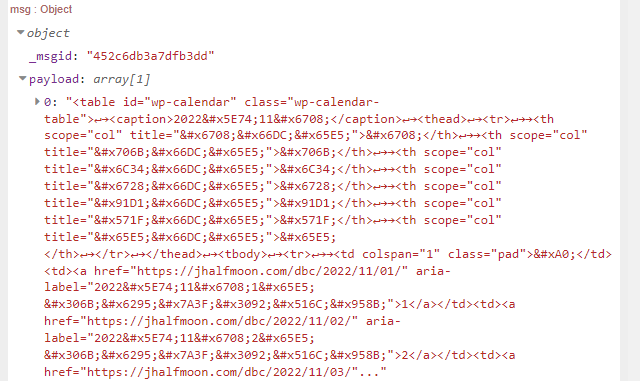
div[id="calendar_wrap" i]:first-child
子レベルの抽出では要素は1個しかなかったのですが、念のため最初の要素を取り出してます。結果は最初と同じ。
div[id="calendar_wrap" i]:first-child > *
抽出した「子要素」の中で全ての要素を列挙するために > でさらに子要素(divからみたら孫)を指定し、孫レベルの全要素を * で列挙してます。2要素みつかってます。

div[id="calendar_wrap" i]:first-child > :first-child
子の子(孫)要素の2つのうち最初の方を取り出してます。

div[id="calendar_wrap" i]:first-child > :first-child > caption
さらに取り出した孫要素の中の caption要素(ひ孫)を取り出してます。結果はこんな感じ。

ブラウザ上では「2022年11月」と読める筈のcaptionですが、HTML文書内のUnicode表記なので「年」は「E74;」 (16進)となんだかな~な文字列に見えます。
CSSセレクタで所望の部分の抽出は思いのまま。ちょっと出来たからって調子こいてんじゃねえ。