R言語付属のサンプルデータベースをABC順にめぐってます。今回は mapsパッケージのunempです。米国の各州郡別の失業率データみたいです。同名で異なるデータが複数あるようです。このmapsパッケージのunempの個別の説明は見当たりません。どうも他のサンプルデータセットのサブセット?みたいな感じです。
※「データのお砂場」投稿順Indexはこちら
※使用させていただいている Rのversionは 4.3.1。RStudioは 2024.04.2+764 “Chocolate Cosmos” です。
unemp サンプル・データセット
失業率は、経済指標として関心の集まるデータであるためか、同名の unemp という名をいただくサンプル・データセットが複数存在します。
上の双方とも、「時間に対する」米国全体の失業率データです。対象時期が異なる上に、1はデータフレーム、2は時系列データとデータ形式も異なります。
一方、今回の unemp は maps データセット付属のサンプル・データセットです。単に Sample datasets という記述があるだけで、mapsパッケージ内のドキュメンテーションはみあたりません。郡単位のfipsコードと郡の人口、失業率を列挙したデータフレームとなってます。
上記のmapsパッケージのデータに近そうなデータセットを調べたところ、以下のものが近そうでした。
unemp: USA Unemployment in 2009
上記ページCSVデータへのURLが掲載されてます。該当データは8変数あるのですが、ここから3つを取り出すと maps パッケージ所蔵の unemp になるんでないかと。知らんけど。
練習台はカリフォルニア州内
サンプル・データセットといっても3000以上の郡が含まれているので、メンドイです。そこでカリフォルニア州部分のみ取り出して処理の練習に使おうと思います。以下の過去回で、カリフォルニア州内の郡のFIPSコードを図にしているからです。
データのお砂場(169) R言語、county.fips、廃止されたけど使用中?{maps}
その時作製のFIPSコードの地図が以下に。
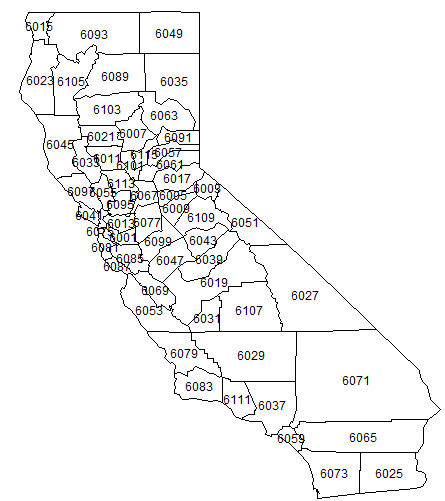 まずは生データ
まずは生データ
まずは、mapsパッケージのunempデータセットのロードとその中身の確認から データフレームで、郡のFIPSコードと人口、失業率が列挙されているようです。
データフレームで、郡のFIPSコードと人口、失業率が列挙されているようです。
カリフォルニア州部分を処理
まずは、ここからカリフォルニア州の部分を取り出します。FIPSコードで6000番台がカリフォルニア州内の郡なので
calif <- unemp[(unemp$fips >= 6000) & (unemp$fips < 7000),]
上記でとりだせた筈。
取り出したデータベースのsummaryを見てみます。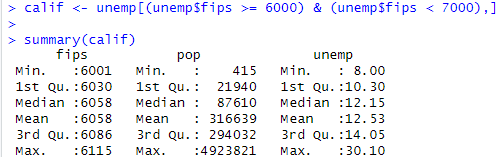
失業率 unemp は、8%から30.1%とかなりバラついてます。
失業率の最大、最小のレコードを調べておきます。
califUNEMP[which.max(califUNEMP$unemp),] califUNEMP[which.min(califUNEMP$unemp),]
結果が以下に。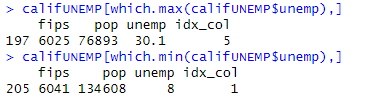
このデータセットには郡名は含まれていません。過去回で使ったcounty.fipsなどを使えば郡名に変換できますが、FIPSコードから群名検索は簡単なので調べてみると以下のとおり。
-
- 失業率最大は、6025 imperial County
- 失業率最小は、6041 Marin County
インペリアル郡まで行った記憶はありませぬが、メキシコ国境へ広がる荒涼とした荒野、という勝手な意見(偏見)です。一方、マリン郡は金門橋(ゴールデンゲート・ブリッジを年寄は漢字で呼ぶのだな)のすぐ北側にある、いかにもお金持ちが住んでいる(実際、州内でも所得が一番らしい)海に面した高級住宅地っす。自然も豊かだけれど大都会の直ぐ近く。格差カイデー。
さてこれを図示すべく以下のように処理してみました。
breaks <- c(0, 10.3, 12.15, 14.05, 30, 31)
labels <- c("-10.3", "10.3-12.15", "12.15-14.05", "14.05-30.0", "30.0-")
idx_cut <- cut(calif$unemp, breaks = breaks, labels=labels, include.lowest = TRUE)
idx_col <- as.numeric(idx_cut)
califUNEMP <- cbind(calif, idx_col)
idx_pal <- c("#F1EEF6", "#D4B9DA", "#C994C7", "#DF65B0", "#980043")
stateNam <- c('California')
map('county', stateNam, fill = TRUE, col = idx_pal[califUNEMP$idx_col])
title("unemployment by county, California")
この結果が以下に。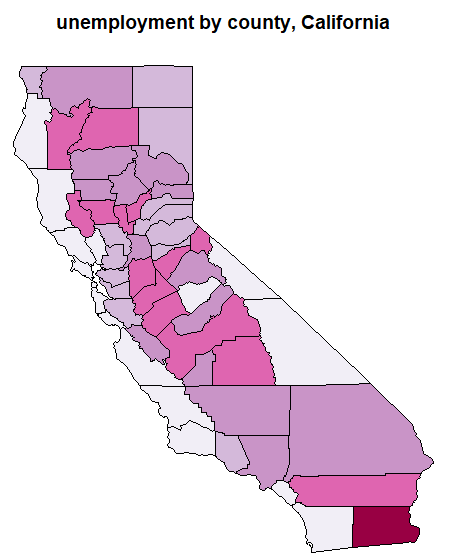
郡名を表示するために以下のコードを追加して、
data("county.fips")
califCounties<-county.fips[grep("calif", county.fips$polyname), ]
map.text('county', add=TRUE, califCounties$polyname)
勝手なコメントを手書きしたものが以下に。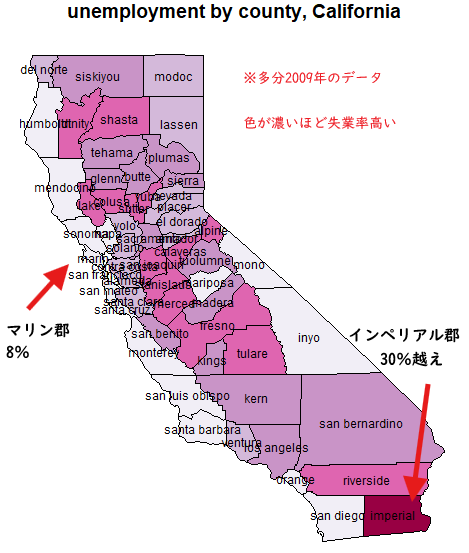
いやあ、太平洋ぞいの地域の失業率は低く、サンホアキン・バレーあたりの農業地帯とモハーベ砂漠の方は失業率高め。でも山の中なのに、マリポーサとかモノとかが低いのは観光地だから?知らんけど。