MASSパッケージのサンプルデータセットを巡回中。大文字優先のABC順。前回はGAG(グリコサミノグリカン)についてでした。今回は自動車保険の請求件数データです。海外の古いデータですが、現代日本でも傾向は変わらないかも。保険といったら数理のプロフェッショナルがご活躍のイメージ。サンプル処理結果を見るのも難しいよう。
※「データのお砂場」投稿順Indexはこちら
Numbers of Car Insurance claims
今回のサンプル・データセットの解説ページが以下に。
https://stat.ethz.ch/R-manual/R-devel/library/MASS/html/Insurance.html
このデータセットは、スイスのチューリッヒで開かれた「アクチュアリー」様の会議の議事録がソースになっているらしいです。場所といい、いかにも保険業界の牙城?な雰囲気が醸し出されとります。英国(もしかすると米国)の1973年第3四半期の自動車保険請求の件数のデータです。つまりそれだけ事故があったってこと?
データには3列の「カテゴリカル」(でも順序はつけられそう)なデータが含まれてます。
-
- district 居住地区、4が主要都市、1になるほど田舎らしい?
- Group 対象車の排気量をグループ分けしたもの
- Age 被保険者の年齢をグループ分けしたもの
まあね、毎年自動車の保険料の支払いに汲々としているお惚け老人です。車種や対象者の年齢(息子ども)により保険料が大きく変わるのは実感しておりますぞ。どうも、このサンプルデータはそれの「背景」的な、ごくごくシンプルなデータみたい。でも傾向は歴然かも。
上記のカテゴリカルな変数に対してカウント値で表される変数は2つ。
-
- Holders 保険契約者数
- Claims 請求件数
どんな事故なのかはおいておいて、保険加入者様の数と、請求件数のみ集計と。
まずは生データ
いつのとおり生データをロードしたところが以下に。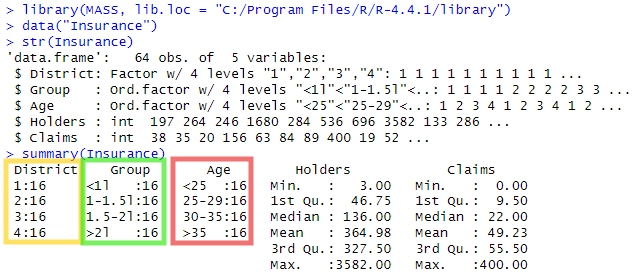
上記の下の方で、summaryとってますが、先ほどの「カテゴリカル」な3変数に黄、緑、赤の枠をかきそえました。それぞれ4分類、各分類に16個のデータが格納されているご様子。
層別してみる
上記のようにそれぞれのカテゴリに4種16点のデータが含まれておるということで「層別」してみることから始めました。
まずはDistrict列
district.w <- aggregate(cbind(Holders, Claims) ~ District, Insurance, sum)
district.r <- data.frame(district.w$Claims / district.w$Holders)
names(district.r) <- c("ClaimsHoldersRatio")
district.b <- cbind(district.w, district.r)
つづいて Group列、能が無いので上記とクリソツなシーケンスをそのまま繰り返してしまいました。
group.w <- aggregate(cbind(Holders, Claims) ~ Group, Insurance, sum)
group.r <- data.frame(group.w$Claims / group.w$Holders)
names(group.r) <- c("ClaimsHoldersRatio")
group.b <- cbind(group.w, group.r)
最後にAge列ね。年齢若いと保険料は超高い、実感。
age.w <- aggregate(cbind(Holders, Claims) ~ Age, Insurance, sum)
age.r <- data.frame(age.w$Claims / age.w$Holders)
names(age.r) <- c("ClaimsHoldersRatio")
age.b <- cbind(age.w, age.r)
上記の集計結果をグラフにまとめたものが以下に。
par(mfrow=c(1, 3)) plot(district.b$District, district.b$ClaimsHoldersRatio, main="by District", xlab="district", ylab="ClaimsHoldersRatio") plot(group.b$Group, group.b$ClaimsHoldersRatio, main="by Group", xlab="Group", ylab="ClaimsHoldersRatio") plot(age.b$Age, age.b$ClaimsHoldersRatio, main="by Age", xlab="Age", ylab="ClaimsHoldersRatio")
実際のプロット(とそこにお惚け老人がコメント書き入れたもの)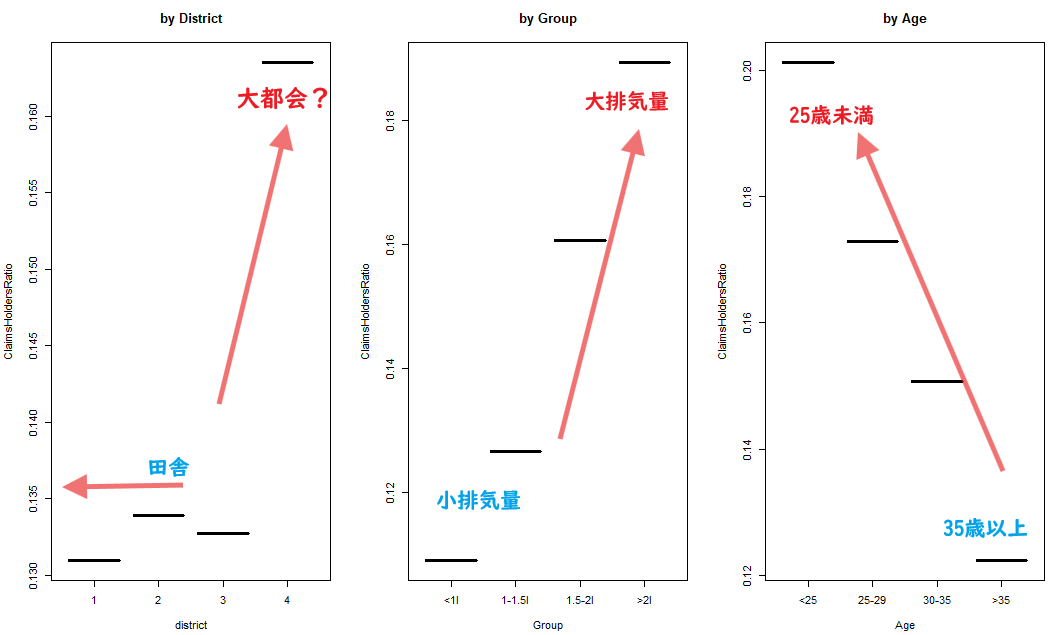
結構、「一目瞭然」とした集計だな、おい。
処理例あり
MASSパッケージのサンプルデータセットにしては珍しく処理例がついてました。カテゴリカルなデータを含むこのデータにglm、loglmかけてみよと。
統計素人老人は、lmで「量的なデータに線形な回帰」をかけるのが精いっぱいです。glmとかloglmとかを使う意味をついGoogleの生成AI、Gemini 2.5 Flash様に問いかけずにはいられませぬ。ご回答のまとめの表が以下に。
分かったような、分からぬような。もうイッチョ引用しておくと、上記は以下のようにも言い換えられるっと。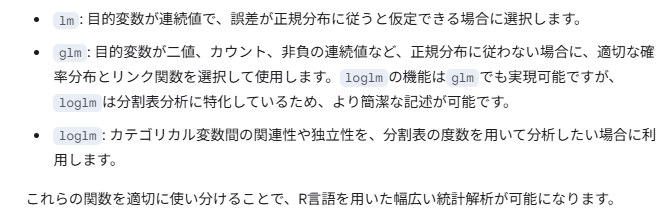
さて、サンプルデータへのglmの適用から。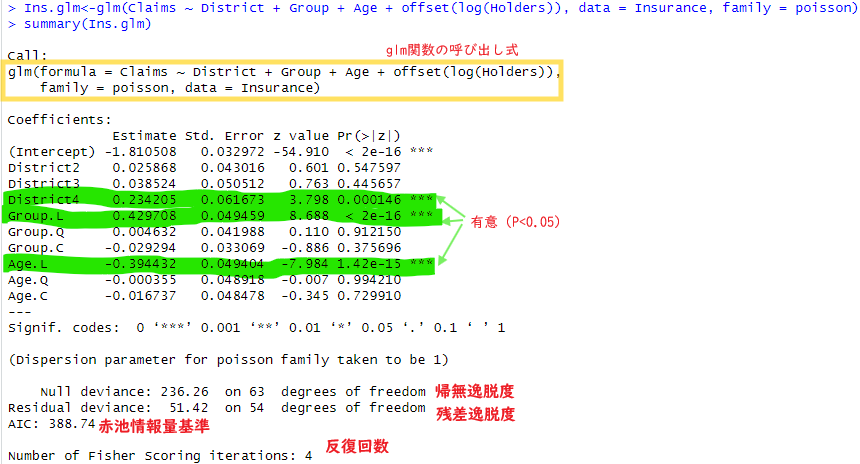
結果にいくらか註釈を書き込みしてみましたが、素人老人はサッパリです。難しいっす。なお、カテゴリカルな変数にL、Q、Cというものが登場してますが、
-
- .L 線形
- .Q 2次
- .C 3次
の意味らしいっす。4次以降は4とか数字になるみたい。どうもカテゴリカルな変数(順序がある)をglmで解釈するときに、線形で当てはめるとしたら、とか2次関数であてはめる、とか考えてくれるみたいです。上記ではGroupとAgeに関しては「線形」と考えると座りが良いみたい。「層別」グラフで見たとおり?かな。
一方、loglmはもっとムズイよ。こんな感じ。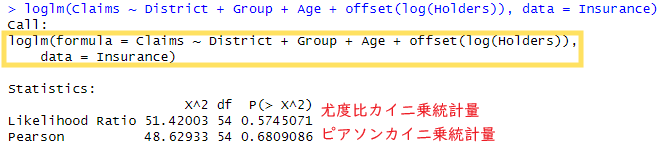
もともとの知識が全然ない素人老人は跳ね返されました。はい。