MASSパッケージのサンプルデータセットを巡回中。大文字優先のABC順。前回は交通事故と制限速度の関係でした。今回は「シリアル」です。牛乳やヨーグルトをかけて朝食にすることが多い、コーンフレークとかグラノーラみたいな食品です。そういえばお惚け老人も今朝そのようなものを食べたような。食べたもの忘れてるのは忘却力ヤバイよ。
※「データのお砂場」投稿順Indexはこちら
Nutritional and Marketing Information on US Cereals
今回のサンプルデータセットは UScereal です。解説ページが以下に。
https://stat.ethz.ch/R-manual/R-devel/library/MASS/html/UScereal.html
上記解説ページを拝見するに、元データはカーネギメロン大様のサイトにあるようです。1990年代の米国のデータですが、21世紀の日本のスーパーでも似たようなものどもが買える気がします。それほど劇的な変化はないみたい。知らんけど。
さてこのサンプルデータベースは、全部で65種類のシリアル食品について、「1食あたりの栄養分」と「マーケティング情報」を集めたものです。具体的なお名前を省略する傾向があるRのサンプル・データ・セットの中では珍しく、食品名も含んでます。
ここで「1食」というのは、アメリカン・カップ1杯分なんだそうな(下手に検索するとヨットのアメリカスカップが登場して困ります。)どうも1カップ = 約240cc(ml)ということみたいっす。念のためGoogleの生成AI、Gemini 2.5 Flash様のご見解を以下に。
なお、「栄養分」にリストされているのは以下のような項目です。米国FDAが表示を義務づけているみたい。
-
- calories、カロリー
- protein、タンパク質[g]
- fat、脂肪[g]
- sodium、ナトリウム[mg]
- fibre、食物繊維[g]
- carbo、複合炭水化物[g]
- sugars、糖分[g]
- potassium、カリウム[mg]
- vitamins
なお、ビタミンについては1990年代の表示は、現在の表示と違うところがあるみたい。
一方、「マーケティング情報」は以下の
-
- mfr、会社名(略字1字)。具体的な社名は以下のとおり。G=General Mills, K=Kelloggs, N=Nabisco, P=Post, Q=Quaker Oats, R=Ralston Purina.
- shelf、商品棚における位置、1が下、2が中、3が上
まずは生データ
生データはフツーのデータフレームです。ロードして、サマリをとったところが以下に。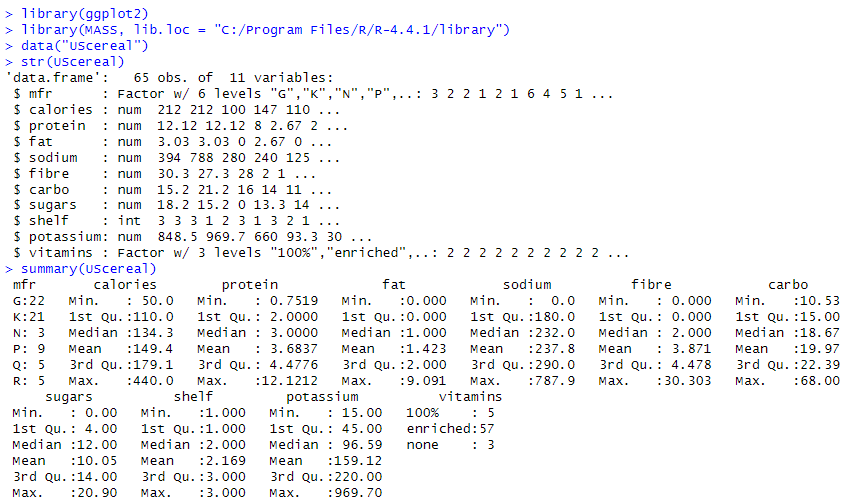
以下のように具体的な商品名も含まれてます。
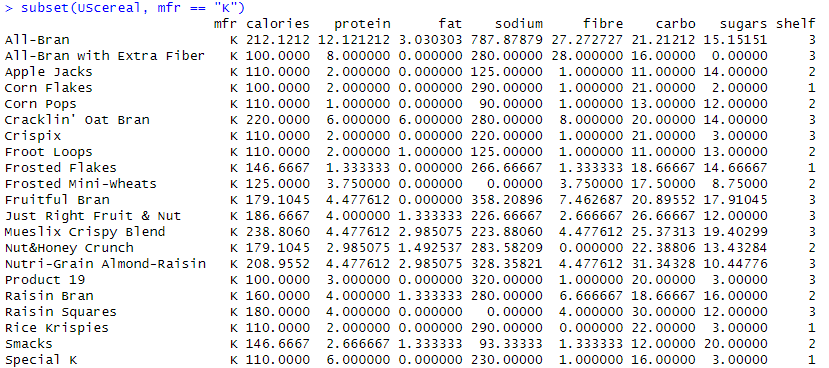
また、以下のようにすれば「ケロッグ社」の製品一覧サブセットを取り出すことも可。
何をどう処理したらよいのかサッパリなので、とりあえずプロット実施。
plot(UScereal)
結果が以下に。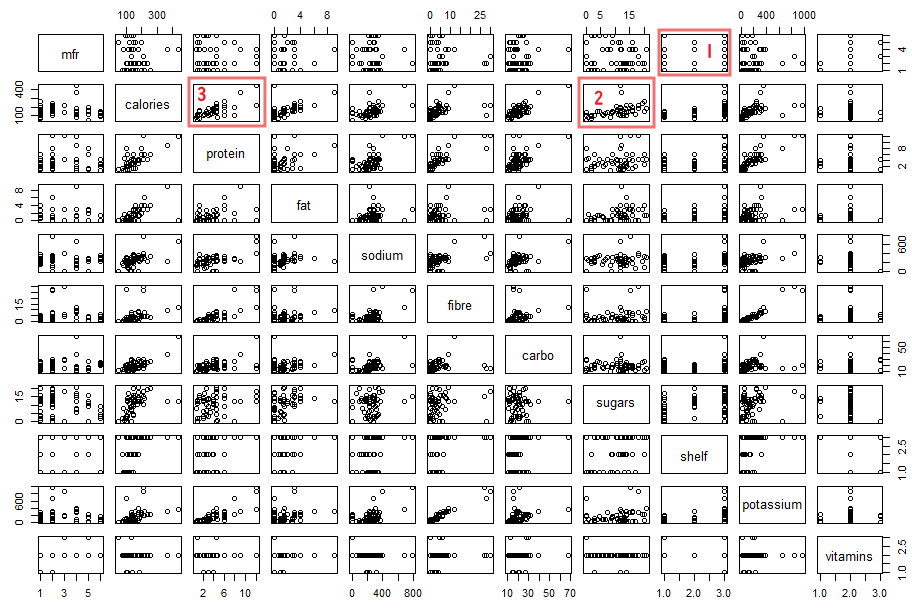
個別にちょっと調べてみる
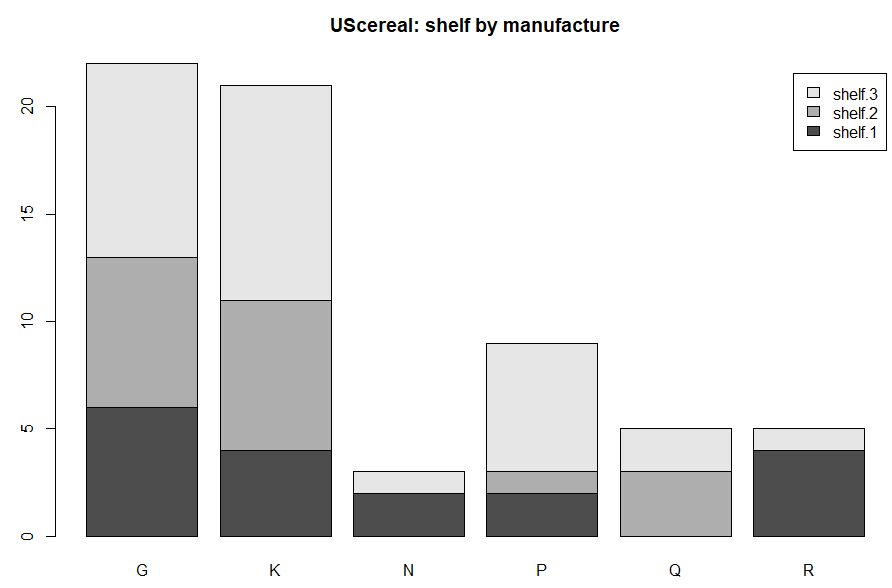
データの中でも気になったのが shelf という変数とmfrの関係です。上のプロットでは「1」と番号振ったところです。当然売れ筋の製品が目立ついい場所に置かれることになると想像。また、メーカ各社の力関係もそこには現れるような気がします。
shelf.1 <- table(UScereal[UScereal$shelf==1,]$mfr) shelf.2 <- table(UScereal[UScereal$shelf==2,]$mfr) shelf.3 <- table(UScereal[UScereal$shelf==3,]$mfr) shelf.all <- rbind(shelf.1, shelf.2, shelf.3) barplot(shelf.all, legend=TRUE) title(main="UScereal: shelf by manufacture")
上記のような処理で描いてみた「会社別商品棚位置」の棒グラフが以下に。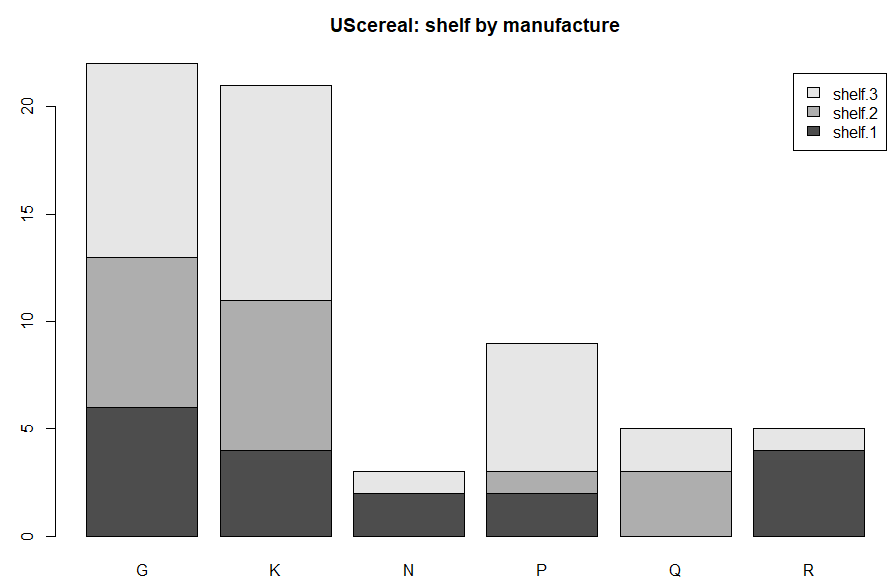
Gはジェネラル・ミルズ社、Kはケロッグ社であります。この2社が商品点数で他社を圧倒している感じ。そして多分「一番目立つ」と想像される「真ん中の棚」shelf.2におかれている感じです。今はどうなんだろ?
つづいて、プロットで「2」と番号を振った、砂糖とカロリーの関係ね。
p0 <- ggplot(UScereal, aes(x=sugars, y=calories)) + geom_point(aes(color=mfr))
p1 <- p0 + ggtitle("Nutritional and Marketing Information on US Cereals") + xlab("sugars") + ylab("calories")
p1
プロット結果が以下に。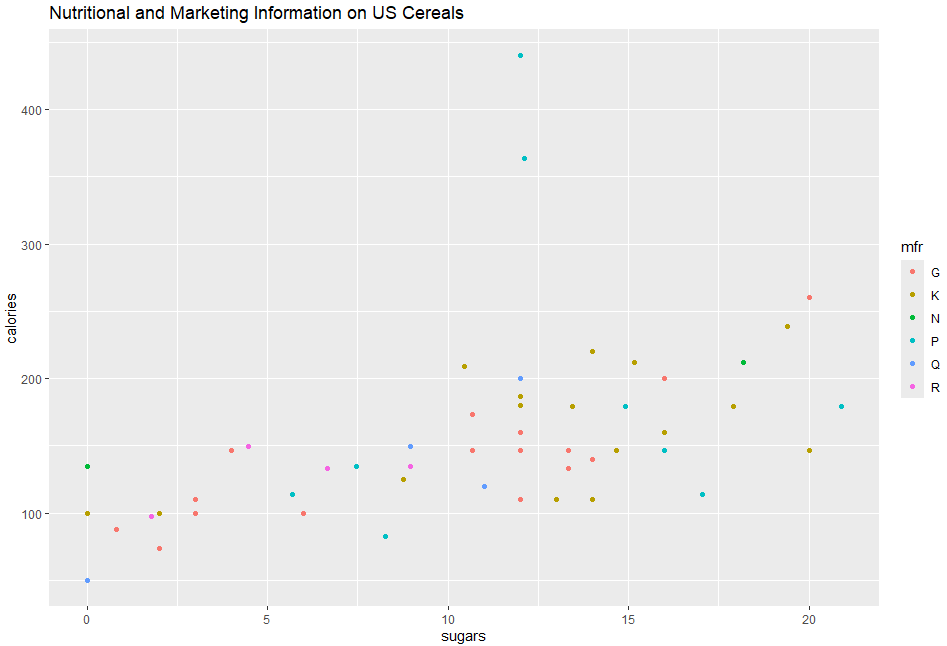
またプロットで「3」と番号を振った、プロテインとカロリーの関係。
p2 <- ggplot(UScereal, aes(x=protein, y=calories)) + geom_point(aes(color=mfr))
p3 <- p2 + ggtitle("Nutritional and Marketing Information on US Cereals") + xlab("protein") + ylab("calories")
p3
グラフが以下に。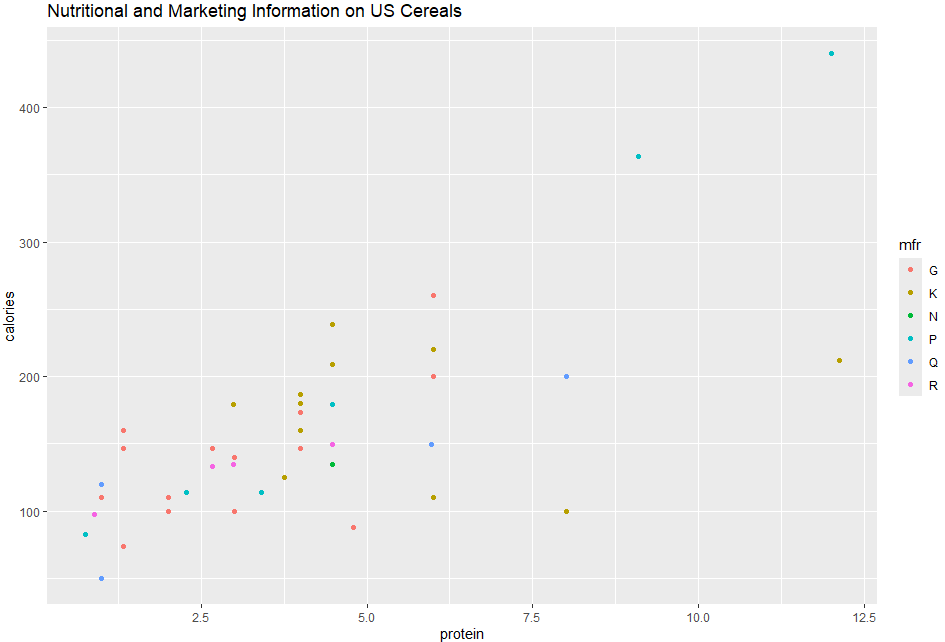
クラスタリングしてみる
思い立ったので、シリアルどもをクラスタリングしてみました。
library(cluster, lib.loc = "C:/Program Files/R/R-4.4.1/library") plot(agnes(UScereal), ask=TRUE)
結果のデンドログラムが以下に。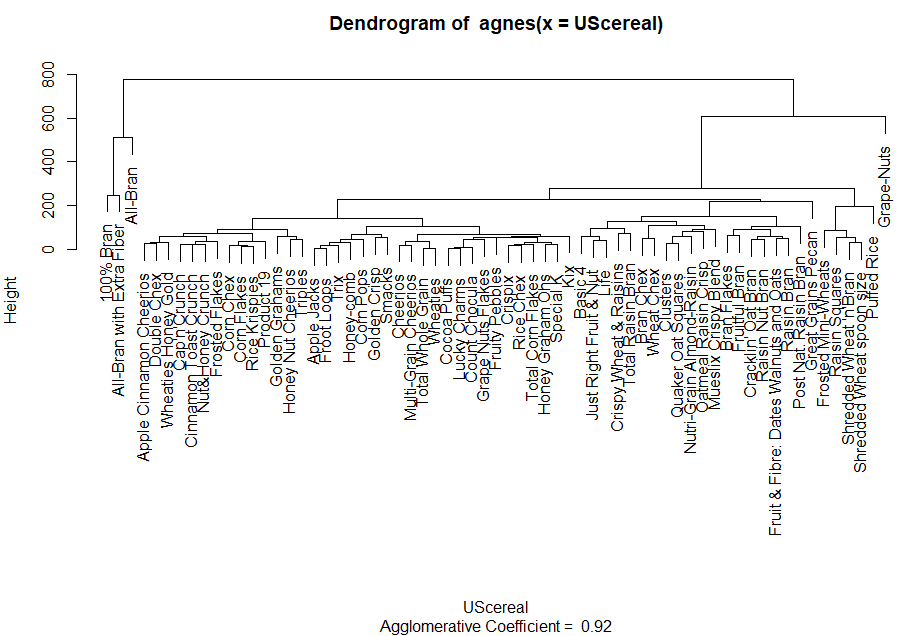
上記をみると、左端と右端に「遠い」ものがあって、他は似たりよったり?な感じがしないでもない。それぞれのクラスタから一つ取り出して具体的な数値をみてみたものが以下に。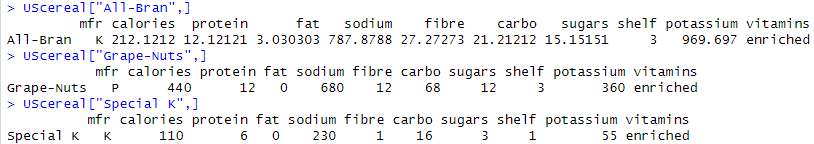
朝食シリアル、実は奥深い?