MASSパッケージのサンプルデータセットを巡回中。大文字優先のABC順。前回は「刑罰制度が犯罪率に与える影響」でした。今回もフェイタルな感じのデータですが、医療系です。肺がん患者の生存時間解析デス。1980年以前に米国「退役軍人局」(現在は退役軍人省に昇格?しているらしい)が行った試験結果みたいです。
※「データのお砂場」投稿順Indexはこちら
Veteran’s Administration Lung Cancer Trial
今回のサンプルデータセットは VA です。解説ページが以下に。
https://stat.ethz.ch/R-manual/R-devel/library/MASS/html/VA.html
データセット名は VAと素っ気ないです。日本人には馴染みがない人が多いと思います。しかし、VAといえば米国人にはお馴染みの組織みたいです。なんたって米国連邦政府の職員数でも予算でもかなり大きな比重を占める巨大なお役所らしいです。
今回のサンプルデータセットの出元は1980年発行の文書なので、当時のお役所名は、
Veteran’s Administration
だったようです。この当時は独立行政機関であったみたい。それが1989年になると連邦政府の「省」に昇格?しています。
米国退役軍人省(United States Department of Veterans Affairs, VA)
です。どちらの場合もVAと略すみたい。なお、VAが何をやっているかというと、
-
- 退役軍人への医療
- 退役軍人への給付
- 国立墓地
の3つが主たる業務みたい。巨大な米軍組織であるので退役軍人様の数も膨大。
今回のデータは、退役軍人局様が何か新しい肺がんの治療法を試していた試験データ、であるみたいです。データに含まれる変数は以下のとおり
-
- stime 生存期間または追跡日数
- status 死亡または調査打ち切り
- treat 標準治療か試験的な新しい治療法か
- age 年齢
- Karn カルノフスキー・スコア
- diag.time 治験参加時の診断からの経過月数
- cell 細胞(多分がんの)タイプ(4種類)
- prior 以前の治療法
上記のうち、「カルノフスキー・スコア」についてはお惚け老人は聞いたこともありませんでした。例によってGoogleの生成AI、Gemini 2.5 Flash様にお聞きすると、
なんだ、%といって10%単位なのね。分類される11段階についてもお教えいただいているので掲げさせていただきます。
まずは生データ
生データはフツーのデータフレームです。ロードしてみたところが以下に。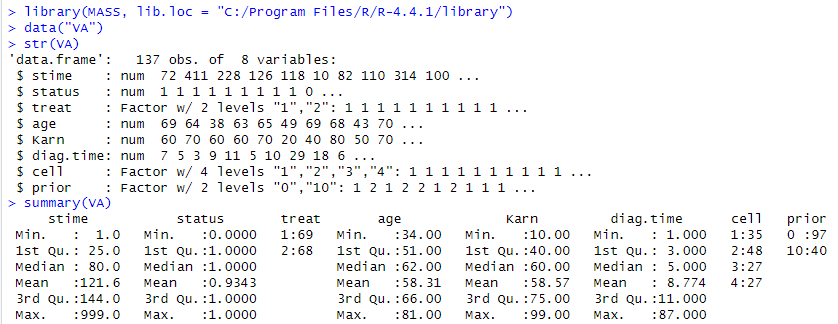
ヤバイデータですが、淡々と数字が並んでいるのみ。ちょっと違和感があるのが、summaryuのKarnの項目です。Max.=99.00とな。あれ、10%単位でなかったの? データを見てみるとこんな感じ。
よくみると、上記の中に99という数字が紛れこんでおります。また、75とか85とかも。お惚け老人が推察するに、75とか85というのは「どっちか判断に困る」ようなスコア、そして99というのはほんとは100なのだけれども100と記入できないので99と書いた、みたいな?
そう思ってみると stime も Max.は999です。勝手な想像では本データの集計はCOBOLのような固定長のフィールドを扱う言語で処理されていて、stimeは10進3桁、Karnは10進2桁であったのではないかと。まあ、それでどうしたという感じですけど。
Kaplan-Meier curve
しかし、このサンプルデータをもってきて、どういう処理したら良いのか素人老人はサッパリです。過去回でも似たような不吉な「死亡統計」を扱った記憶。
データのお砂場(52) R言語、esoph、食道がんの症例対処研究とな?
データのお砂場(100) R言語、breslow、喫煙医師の死亡統計? bootパッケージ
この辺の処理を真似たらどうか、などと悩んでいたら見つけました。
カプランマイヤー曲線
です。経過時間とともに生存率をプロットしていく「生存時間解析」という手法です。Gemini様による説明が以下に。
さて、カプランマイヤー曲線は、パッケージ”survival”を使えば、簡単にプロットできることが判明。 Gemini様に教わった手順でプロットしてみます。
fit <- survfit(Surv(stime, status) ~ 1, data = VA) plot(fit, main = "VAデータセットのKaplan-Meier曲線", xlab = "生存時間 (日)", ylab = "生存確率", lwd = 2, col = "blue")
プロットした結果が以下に。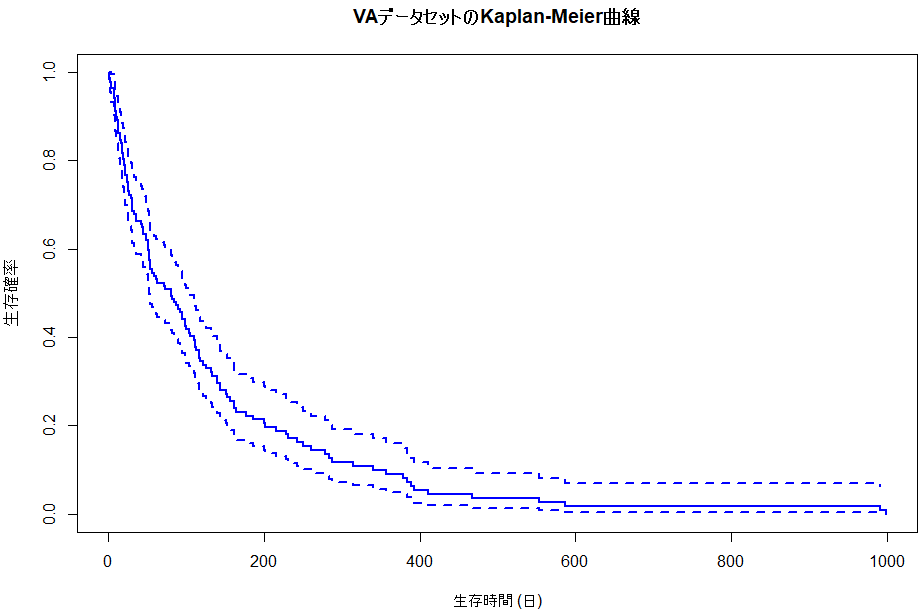
さらに、「標準的な治療法(standard)」と「新たな治療法(test)」で曲線を分けて比べる場合の処理が以下に。
fit_by_group <- survfit(Surv(stime, status) ~ treat, data = VA)
plot(fit_by_group, main = "治療法別のKaplan-Meier曲線", xlab = "生存時間 (日)", ylab = "生存確率", lwd = 2, col = c("blue", "red"))
legend("topright", legend = c("標準治療", "新しい治療"), col = c("blue", "red"), lwd = 2)
そのプロット
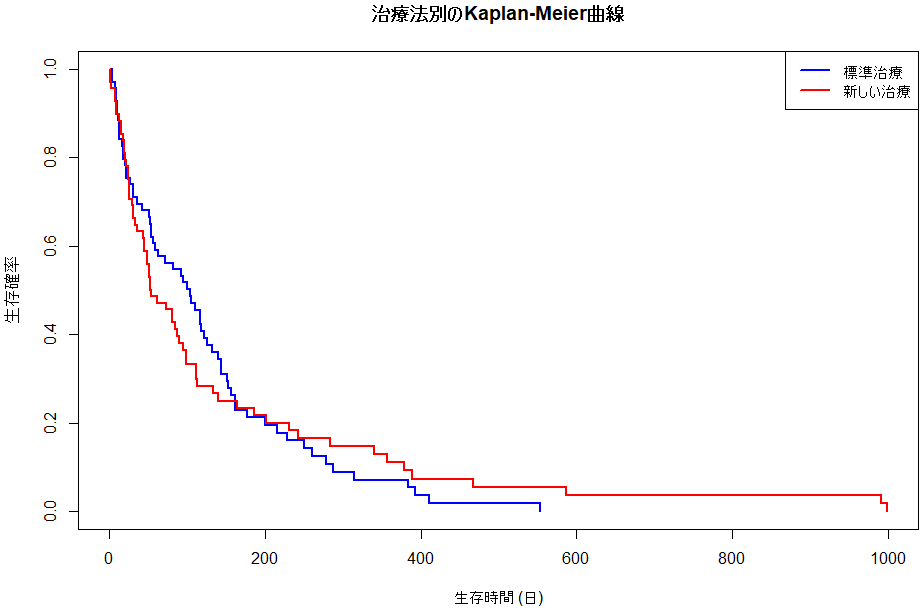 グラフみると、どっちか選べと言われたらきっと悩む曲線だぞ、これは。
グラフみると、どっちか選べと言われたらきっと悩む曲線だぞ、これは。