忙中閑あり、ホントか?まあドタバタは続いていて投稿もままならない日がある中で本日は閑?大丈夫か?MASSパッケージのサンプルデータセットの巡回デス。大文字優先のABC順。今回は cabbages です。キャベツの「頭の重さ」と「ビタミンC」のデータっす。昼はキャベツ食わないとイケないな。
※「データのお砂場」投稿順Indexはこちら
Data from a cabbage field trial
今回のサンプル・データ・セットについての解説ページが以下に。
https://stat.ethz.ch/R-manual/R-devel/library/MASS/html/cabbages.html
キャベツの重さとアスコルビン酸(ビタミンC)の含有量についてのサンプル・データ・セットです。変数は以下の通り。
-
- Cult、キャベツの品種、c39 とc52。
- Date、3植え付け日のうち 1 つを指定するファクタ、d16、 d20またはd21。
- HeadWt、キャベツの重さ(「おそらく」 kg 単位。)
- VitC、アスコルビン酸含有量(単位は不明。)
サンプル・データそのものは、Dr Gertrude Mary Coxがオリジナルみたいっす。どうもCox女史は20世紀の米国統計学会の大立者だったみたい。知らなかったです。モグリなので仕方ない。。。
さて似たようなデータがあるんじゃないか(処理例の参考になるかと)と思って調べたらすぐに日本語の論文が見つかりました。『北海道立総合研究機構』様の以下の論文であります。
北海道立農試集報 82, 97-102(2002)、坂口、中村、日笠、「キャベツのアスコルビン酸含有率に及ぼす 栽培条件の影響」
上記を読ませていただいて、知ってしまいました。
キャベツの重さが重いとビタミンCの含有量は少ない
ううむ、この歳になるまで知らんかったぞなもし。
まあ、知ってしまったからには「その線」でサンプル・データを処理させていただきます。
先ずは生データ
生データをロードして、眺めたところが以下に。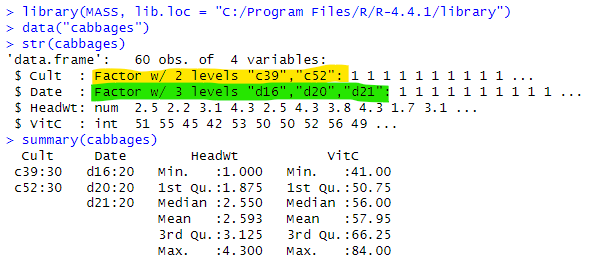
フツーのデータ・フレームです。キャベツの「食べるところ」、「キャベツの頭」と唱えるのだねえ。頭を食っているのか?
層別してみる
層別して平均を求めてみます。方法は古典的なやり方ね。
aggregate(cbind(HeadWt, VitC)~Cult+Date, cabbages, mean)
結果が以下に。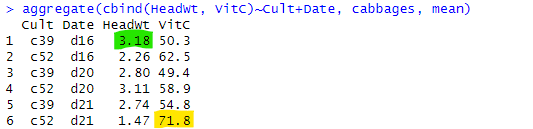
頭の重さが一番のグループ(緑)はビタミンCが2番目に低い。逆にビタミンCの含有量が一番のグループ(黄)は頭の重さが一番軽い。
グラフにしてみたところ
キャベツの品種2種類があるので、品種毎に色分けしたプロットが以下に(とりあえず植え付け日は無視。)
cabbages.c39 <- cabbages[cabbages$Cult=="c39",]
cabbages.c52 <- cabbages[cabbages$Cult=="c52",]
labels <- c("c39", "c52")
cols <- c("salmon", "skyblue")
plot(VitC~HeadWt, data=cabbages.c39, xlim=c(1.0, 4.5), ylim=c(40, 90), main = "Cabbages VitC~HeadWt", xlab = "HeadWt[kg]", ylab = "VitC[unkown unit]", pch=16, col = cols[1])
par(new=T)
plot(VitC~HeadWt, data=cabbages.c52, xlim=c(1.0, 4.5), ylim=c(40, 90), pch=16, col = cols[2], ann=F)
legend("topright", legend = labels, col = cols, pch=16)
処理結果のグラフが以下に。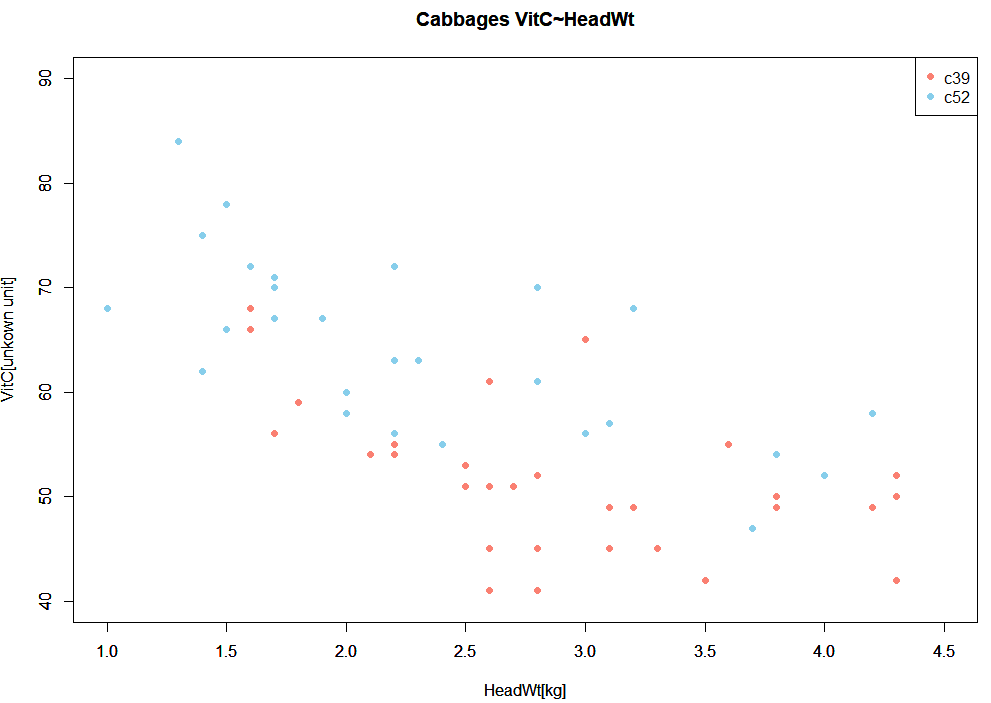
線形回帰をやれ、と言われている感じがするので(気のせいではないよね)、処理が以下に。
cabbages.c39.lm <- lm(VitC~HeadWt, data=cabbages.c39) abline(cabbages.c39.lm, col=cols[1]) cabbages.c52.lm <- lm(VitC~HeadWt, data=cabbages.c52) abline(cabbages.c52.lm, col=cols[2])
上記で描いた回帰直線付きのグラフが以下です。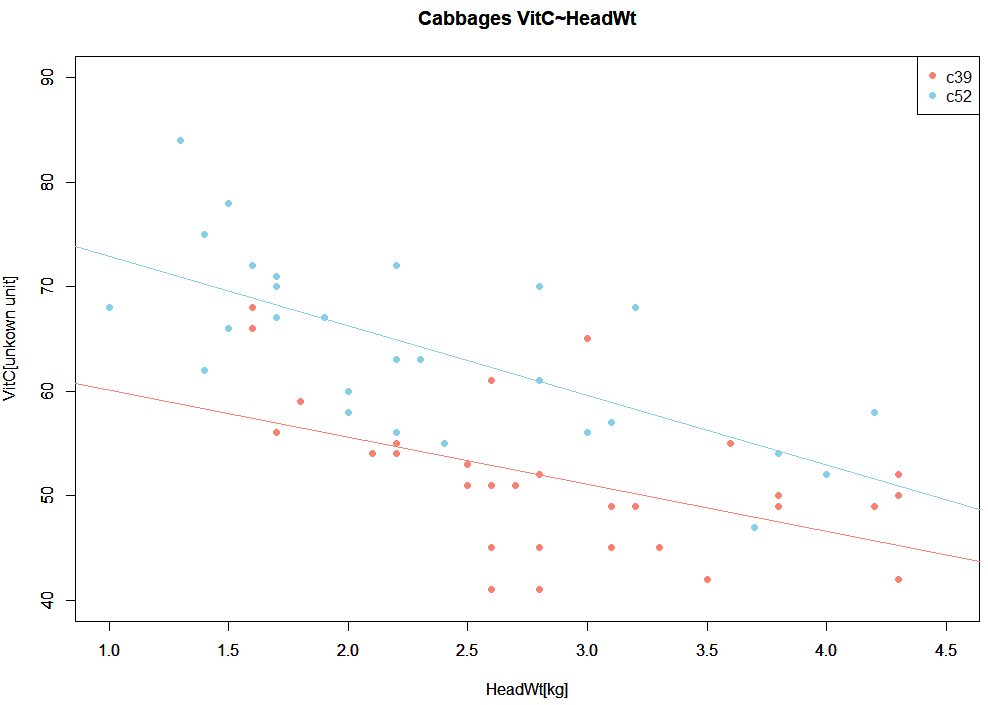
「頭が軽い」やつの方が「ビタミンC」は濃ゆいみたい。そうだったのか。