R言語所蔵のサンプルデータセットをABC順(大文字)優先で拝見させていただいとります。前回、前々回と太陽黒点関係のデータセットが続いています。正直飽きました。しかし今回は太陽黒点らしい解析など絶無。だただた時系列データを「いじる」ときに必要な小ネタ、TIPSの特集という感じです。勉強になったなあ。ホントか? “データのお砂場(82) R言語、sunspot.year、時系列データの小技あれこれ” の続きを読む
データのお砂場(82) R言語、sunspot.year、時系列データの小技あれこれ

デバイス作る人>>デバイス使う人>>デバイスおたく
R言語所蔵のサンプルデータセットをABC順(大文字)優先で拝見させていただいとります。前回、前々回と太陽黒点関係のデータセットが続いています。正直飽きました。しかし今回は太陽黒点らしい解析など絶無。だただた時系列データを「いじる」ときに必要な小ネタ、TIPSの特集という感じです。勉強になったなあ。ホントか? “データのお砂場(82) R言語、sunspot.year、時系列データの小技あれこれ” の続きを読む
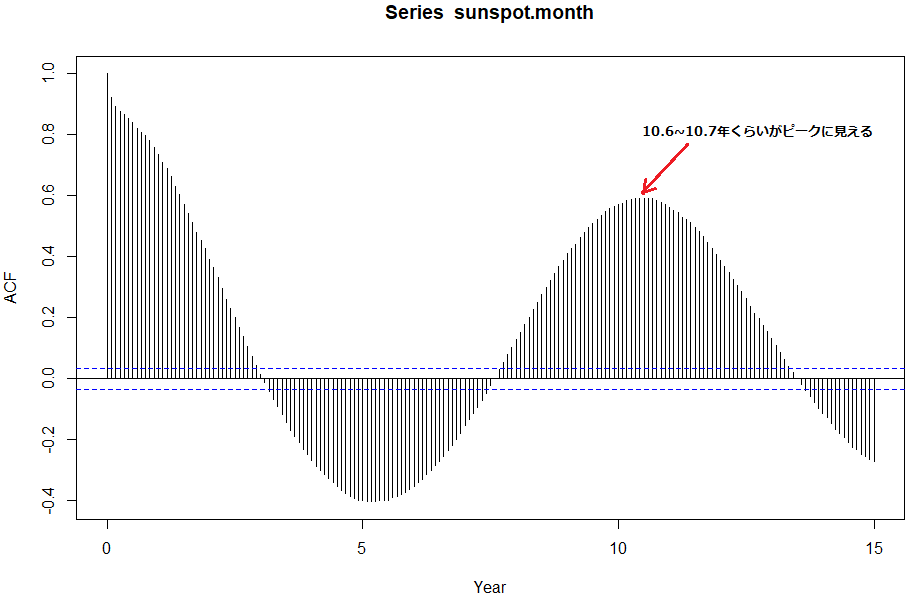
R言語所蔵のサンプルデータセットをABC順(大文字)優先で拝見させていただいとります。前回は太陽黒点関係のデータセット3種を一気にロードして比較してしまいました。しかし似ていても異なるデータセットです。個別に処理例が付属しております。今回はsunspot.monthデータセットの処理例をそのまま練習してみます。 “データのお砂場(81) R言語、sunspot.month、オケイジョナリにアップデート?” の続きを読む
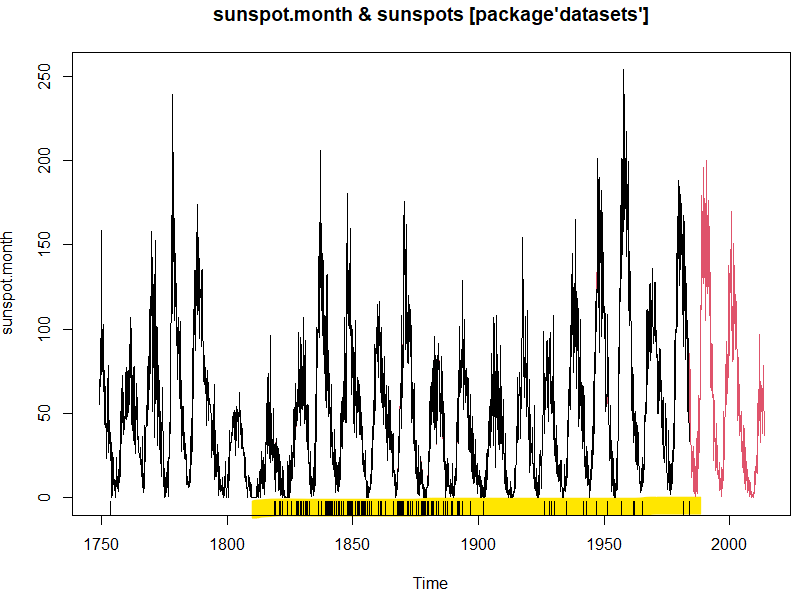
R言語所蔵のサンプルデータセットをABC順(大文字)優先で拝見させていただいとります。今回はsunspots、太陽黒点数データです。毎度サンプルデータセットのデータは古いよなどとブー垂れてましたが今回は古いことにも意義があります。3つのデータセットをあわせると1700年以来2014年までのデータが含まれている、と。
“データのお砂場(80) R言語、sunspots、太陽黒点数の月次データとな” の続きを読む
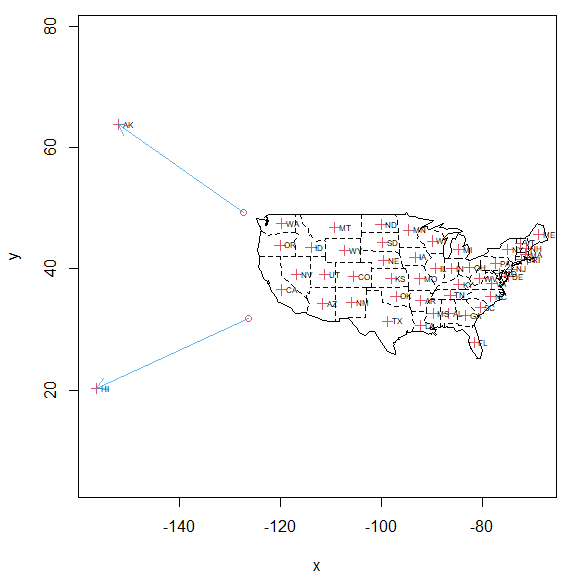
今回のデータは米国50州の「各種」データです。見ていて飽きませんが、例によって古いです。ほぼ50年以上前にまとめられたデータですが、項目によっては100年近く前に遡るデータもあり。まあこの手のデータだと、地図上に表したくなるのが人情?というもの。実際、処理例では米国地図を描いて一部を表示してみてます。地図の練習回? “データのお砂場(79) R言語、state、米国50州のFacts and Figures” の続きを読む
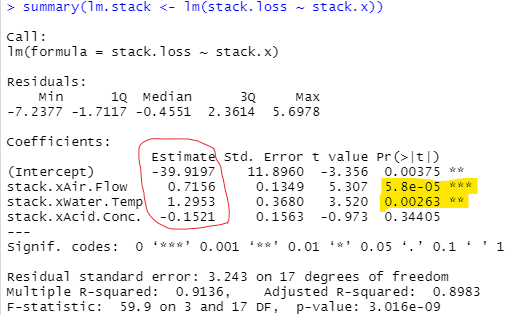
今回のデータセット、stackloss名と別に、stack.xとかstack.lossという名でも呼び出せるみたいです。独立変数3個がstack.xで、従属変数1個がstack.loss。stacklossには「もれなく」両方入っているのでこれをロードすりゃええ、というこってす。今回のデータはなんだ、無機化学?
“データのお砂場(78) R言語、stackloss、オストワルト法の「逆効率」データとな” の続きを読む
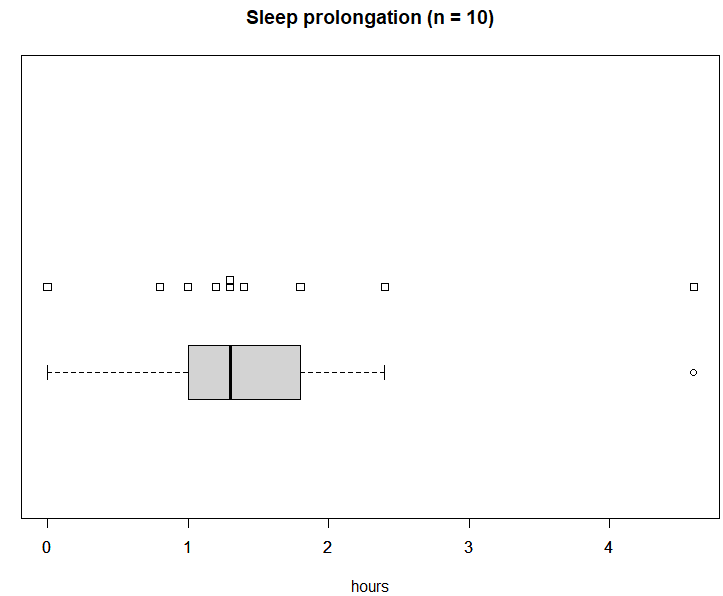
今回のサンプルデータセットには “Student’s Sleep Data” というタイトルがついてます。以前であれば「学生さんのデータなの?」とボケをかますところです。今では知っています。また出たなStudent先生、t検定をやれってことですかい?データ自体は「眠くなるお薬」を飲んだ時の睡眠時間のデータらしいっす。
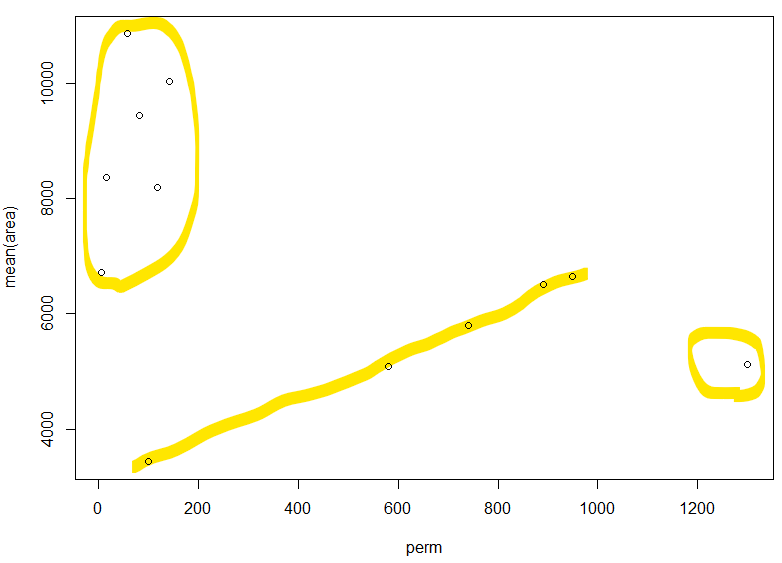
前回に続き、今回も「どう処理したらよいのかサッパリ」なサンプルデータセットです。rockとな。どうも石油貯留層から取り出した岩石サンプルの物理的な測定結果のデータセットみたいです。ただサンプルデータ眺めていても、なんのこっちゃサッパリ分かりませぬ。処理例等も一切なし。しかし国土交通省様がヒントをくれる?と。ホントか。
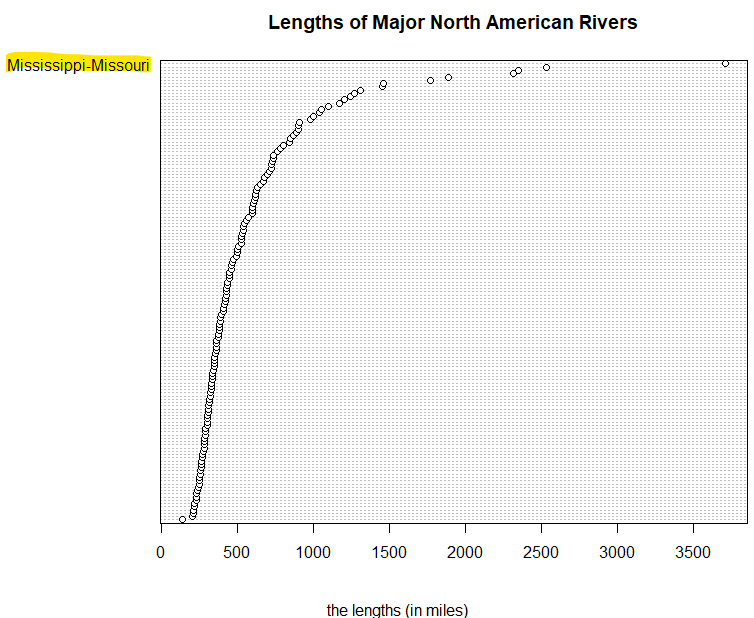
R言語所蔵のサンプルデータセットをABC順(大文字)優先で拝見させていただいております。今回は rivers とな。北米の主要河川の「長さ」のデータみたいです。長さ順に並べるくらいしかその処理を思いつかないのです。しかしデータは名無しの権兵衛、単なる数値の羅列です。川のお名前がありませぬ。 “データのお砂場(75) R言語、rivers、川のお名前をつけたい、名無しベクトルに名前を” の続きを読む
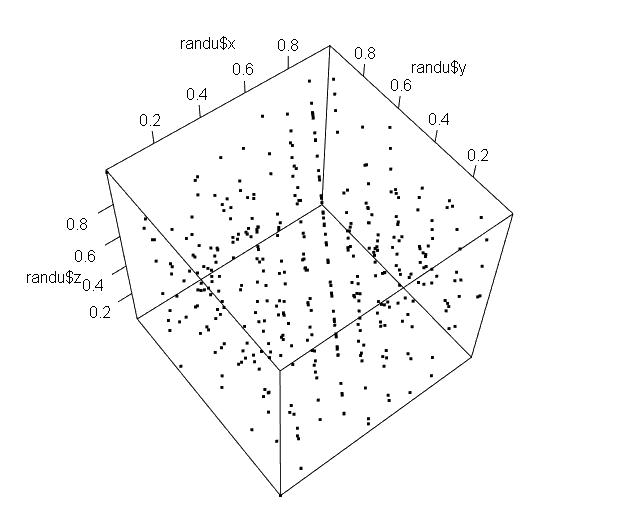
前回は地震の震源?を3次元空間にプロットしたらばプレート界面らしきものが浮かび上がってきました。今回は乱数を3次元空間にプロットすると平面が現れてくるの巻です。最近使われるカッコイい乱数発生アルゴリズムではなく古典的な線形合同法によるものです。VAX FortranのRANDU関数とな。ナツカシー?
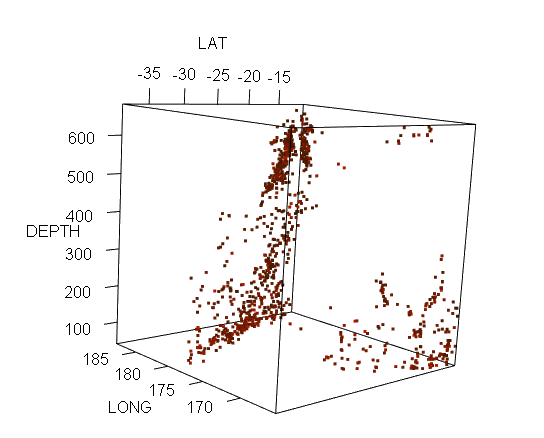
今回は日本人には馴染み深い、地震データです。といっても場所は南太平洋、フィジー周辺のもの。最近も火山の大噴火がありましたが、フィジーも日本同様のプレート沈み込み帯、それもプレート2枚に挟まれたそれなりに複雑な地域みたいっす。Rのサンプルデータを見てもプレートの存在が一目瞭然じゃないかと。ホントか? “データのお砂場(73) R言語、quakes、フィジー周辺の地震、3次元分布とな” の続きを読む
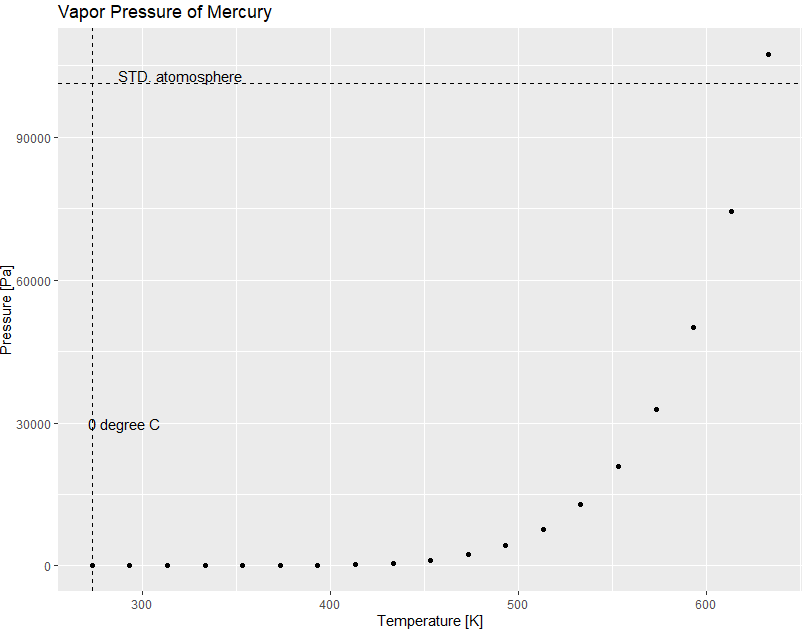
今回、解説のvapor pressure of mercury in millimeters (of mercury)という句を読んで、一瞬親父ギャグと思った私の頭が親父ギャクです。水銀の蒸気圧曲線データです。古いので単位もmmHg(水銀柱高さ)です。当時はSI単位じゃなかったんだな。水銀が重なるのはいたしかたない。
“データのお砂場(72) R言語、pressure、水銀の蒸気圧、単位はミリメートルHgで” の続きを読む
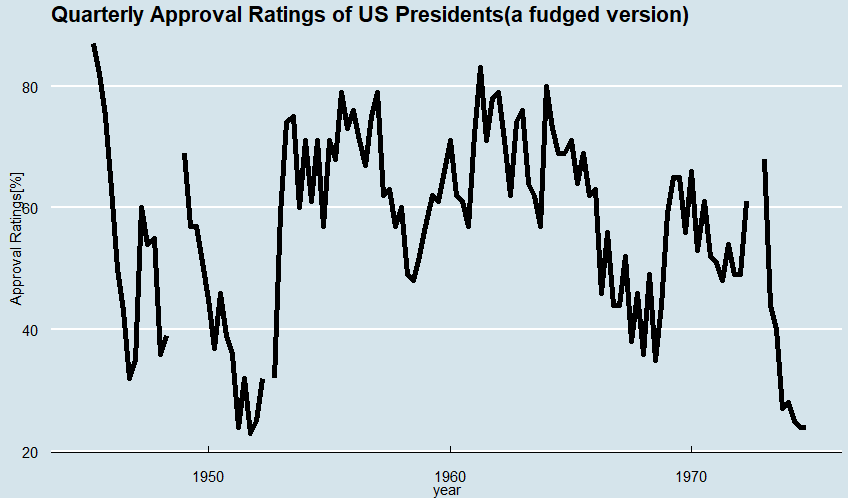
サンプルデータセットは処理のお勉強のためのものなので嘘のデータであっても問題ないと。しかし、私、密かに、サンプルデータセットを通して世界の不思議と世の中を見ておりましたぞ。しかし今回のデータセット(fudged version)とうたっております。なんだこりゃ?何か隠す必要があったのか?大統領支持率。
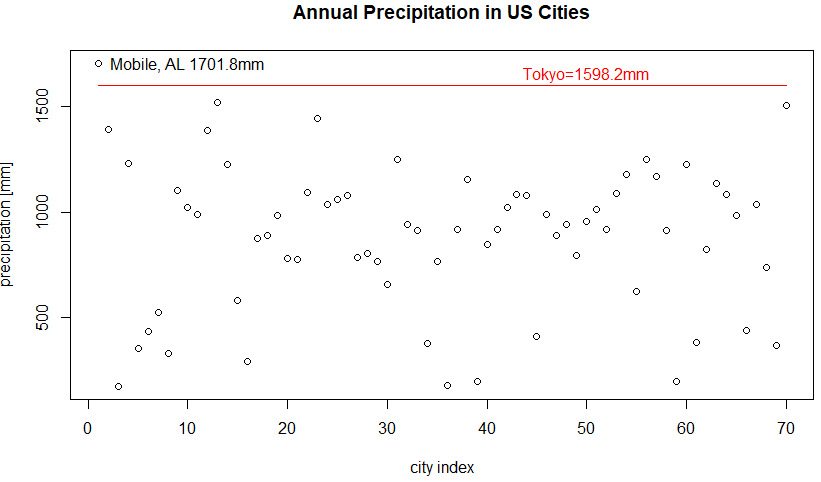
今回は米国各地の年間平均降水量データです。しかし眼目は「つづり間違い」の訂正みたいです。都市名をタイプしつづけて、つい綴りを間違えてしまったみたい。タイポの訂正ならばちゃちゃっと直して口を拭っておいても良いのに、データの修正方法と修正の検証の事例にしちまっているみたいっす。エラーに悪乗り?やらせじゃないみたいだが。
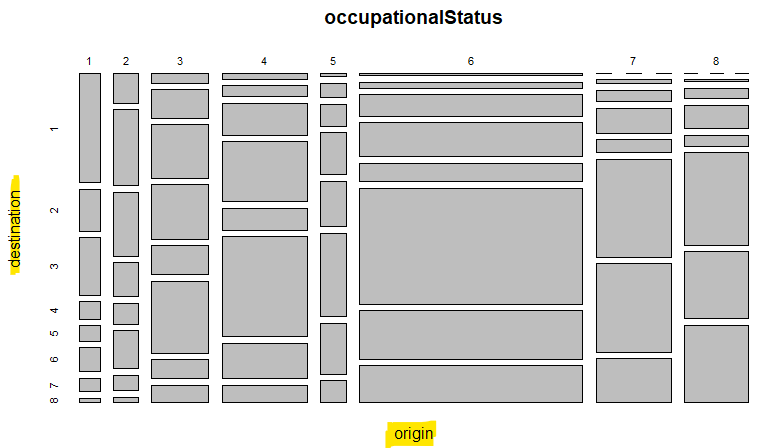
今回は英国における父と子の “occupational status” 統計です。1979年以前の統計、半世紀くらいは前のもの。「大人の事情」か具体的なことは一切ない、ただ数値(整数の度数)の小さなテーブルです。想像するに、英国は今もそんなに変わっていないのではないかと。それどころか、このところの日本も似てきている?