前回はcsv読み込み用のライブラリの使い方をgtestで確認しました。今回は読み込んだデータの処理です。ふと偶数個のときのmedianってどう計算するんだっけという疑問をもったのです。medianの計算をgtestしようとして今度は、gtestで浮動小数の計算のテストってどうするんだっけ、と。疑問は尽きず。
※ソフトな忘却力 投稿順 index はこちら
median、メディアンなのかメジアンなのか、日本語で言ったら中央値は、平均ほどではないですが、統計やったら出てくる定番です。多くの処理系がmedianを求める関数を持っているので、今までボーとして生きてきたので何も考えずにお任せしてきたのです。しかし、ふと気づきました。データ個数が奇数個であれば中央は分かるけれど、偶数個の時はどうしているの?気になると夜も眠れない。
当然ね、調べたらすぐに分かるのです。「皆大好き」Microsoft Excelでの処理に関するMicrosoft社の説明は以下に。
なんだ、前後2個の値の平均を取れば良いのね。
さて、medianの計算のやり方が分かったところで、前回、VSCode+gtestしてみた csvパーサで読み込んだデータの median とってみることにいたしました。ついでに、ありがちな平均(mean)、最大(max)、最小(min)も求めます。
gtestの期待値も C++処理系の中で作っても良いのですが、ここは敢えて他の処理系で作ったものを引き写して使用することにいたしました。ここでは数値計算分野の偉大なツール Octave を使ってみることにしました。その方が間違いなさそうだし。
GNU Octave
Octaveは「MATLAB互換」の処理系としても有名です。私は震災前にちらっと使ってみたことがあります。当時はGUIは無かった記憶です。しかし、何時の間にかGUI登場してました。別シリーズでScilab使わせていただいているので、またまた混乱するわいと思いつつ、収拾つかないのは好きなので、Octaveにも再挑戦することにいたしました。ウエブサイトは以下に。
インストールさせていただいたのは以下のバージョンであります。
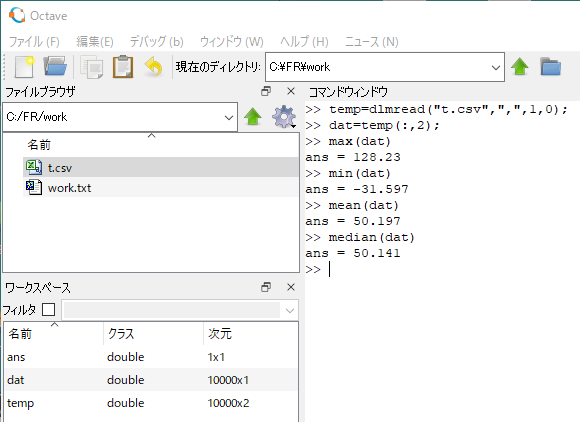
ということで、前回、C++用のcsv読み込み用のテンプレートライブラリ libfccpで読み込んだ csv ファイルを Octaveでも読み込んで、最大、最小、平均、中央値(median)を求めてみます。こんな感じ。
temp=dlmread("t.csv",",",1,0);
dat=temp(:,2);
max(dat)
min(dat)
mean(dat)
median(dat)
さすが Octave であります。上のような感じで一撃で求まります。OctaveのGUIウインドウで求めている時の様子が冒頭のアイキャッチ画像にあります。
一方、median求める途中経過を考えると、まずデータ列をソートして順番を明らかにせねばならない筈。ソートしたらトップとボトムはソート順によってmax, minとなり、中央値は先ほど分かったとおり、偶数個データであるならば中央付近の前後2個データの平均です。原理通りに求めるとこんな感じ。
temp=dlmread("t.csv",",",1,0);
datS=sort(dat);
datS(1)
datS(10000)
datS(5000)
datS(5001)
(datS(5000) + datS(5001)) / 2
以上のOctaveでの処理結果が以下に。

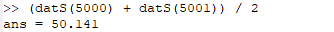
VSCode+gtest環境で C++のコードで同じ計算やってテスト
前回使用した、test_csvparser.cpp に以下のコードを追加、max, min, mean, medianを計算して確認することにいたしました。
しかしここで大いなる疑問が。私でも浮動小数点数のイコール比較はダメよ、ということは知っとります。gtestで浮動小数点数のテストはどうするのだっけ?普段、整数型の組み込みマイコンばかり使っていると浮動小数点数には疎くなります。リハビリのために別シリーズで浮動小数を少しばかりやってますが改善には程遠く。
Google Test ドキュメント日本語訳 >> 上級ガイド
上記のサイトに説明がありました。なお、上記は opencv.jp 様のページです。皆さん gtest 使っているのね。
書いたテストコードは以下です。許容誤差を明示すればよかったのね。
// median, mean, max, min
double sumData, datMean, datMedian, datMax, datMin;
int datNum = dat.size();
sumData = std::accumulate(dat.begin(), dat.end(), 0.0);
std::sort(dat.begin(), dat.end());
datMin = dat[0];
datMax = dat[datNum-1];
datMean = sumData / datNum;
if (((datNum % 2) == 0) && (datNum > 0) ) {
datMedian = (dat[datNum/2 - 1] + dat[datNum/2]) / 2;
} else {
datMedian = dat[datNum/2];
}
EXPECT_NEAR(128.23, d2R(datMax, 2), 0.005);
EXPECT_NEAR(-31.597, d2R(datMin, 3), 0.0005);
EXPECT_NEAR(50.197, d2R(datMean, 3), 0.0005);
EXPECT_NEAR(50.141, d2R(datMedian, 3), 0.0005);
普段、組み込みCばかり書いているとC++新鮮。明示的なループ回さずに皆計算できてしまう。当たり前だけれど近代的。
さて gtest の結果がこちらに。
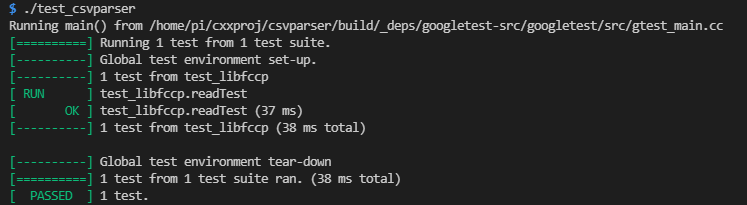
オールパス。本当に全部走っているのだろうね。お愛想で「走ってます」的な出力入れておけよ、自分。