R言語所蔵のサンプルデータをABC順(大文字先)で端から眺めておりますが、今回も前回に引き続き目出度いデータとは言えません。1973年の米国の各州別の都市人口比率と凶悪犯逮捕の比率です。その関係性について調べるのかと思いきや今回のテーマはデータの訂正の仕方です。誰かが転記ミスをしてそれに気づいた人がいると。流石です。
※「データのお砂場」投稿順Indexはこちら
今回のサンプルデータセットの説明ページは以下です。
Violent Crime Rates by US State
ここで統計とられているのは、日本の凶悪犯とか粗暴犯というカテゴリとはちょっと異なるように思われますがそこに含まれるヤバイものばかり。数値は人口十万人あたりの逮捕件数(逮捕ってことは、つかまってない人は数えていないのね。。。)です。これと都市部人口比率(%)を合わせて50州のデータが並んでいる表です。ただ1973年当時です。ほぼ半世紀後の現在はどうなっているのか?
ただ、このデータはそういう犯罪率を考察するためとしてサンプルデータセットになっているわけではなく、データの訂正の練習用みたいです。
まずは生データ
いつもの通り、生データをロードして、形式やらデータの一部やらを眺め、プロットしてみます。こんな感じ。
普通の data.frame データです。プロット結果が以下に。Murder(犯人率?)とAssault(犯人率?)など、ほぼほぼ比例関係にも見えますな。恐ろしや。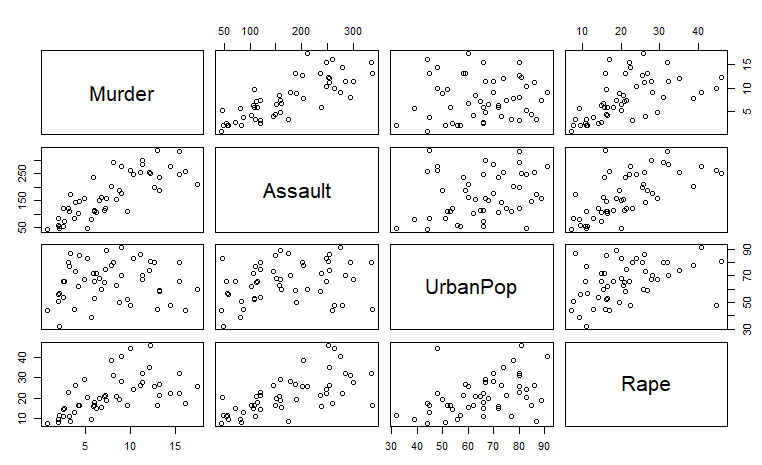
処理例
今回は訂正処理なので処理例にそって処理してみます。なんといっても「元の数字」を知らない私は手も足もでません(知っていてもどうだか?)
まずは処理例では summary()関数使ってデータの塩梅を見ています。クールね。そしてpairs使ってプロット。単にplot()している上記とは一味違いますな。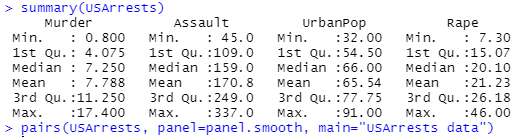
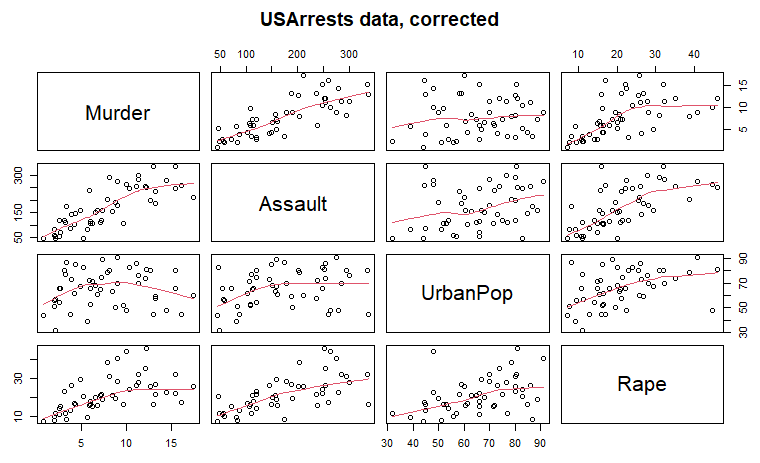
pairsの結果が以下に。赤の線が入っているだけでなんだか分かったような気がします。。。ホントか?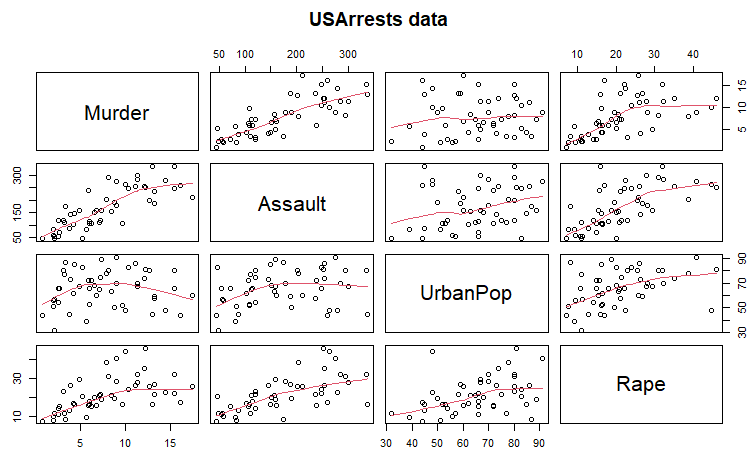
さて本題の修正です。Maryland州の都市人口比率が間違っていたみたいですな。まずはデータを複製して修正済のデータを格納する入れ物 UA.Cを作ってから、データの確認と修正が以下に。
ついでといっては何ですが、人口比率の%データが気に入らなかった?のかオリジナルに戻すようです。処理例からコメント1行引用させていただきます。
also +/- 0.5 to restore the original <n>.5 percentages
これはどういうことかというと、R言語のroundは「偶数丸め」だからです。Rに限らずモダンな言語は皆そうでないかと。世の中標準。でも小学生以来慣れ親しんだ「4捨5入」と比べると違うことがあります。以下のような例を見るとちょっと違和感がしないでもないです。
その辺を「鑑みて」か、単にデータ修正の練習か、合計6州のデータに0.5を足し引きしてオリジナルに戻しているみたいです。こんな感じ。

目出度く訂正できたので、UA.Cデータをグラフにしたものを冒頭のアイキャッチ画像に掲げました。グラフにしたらどこ訂正したのかわからんぞなもし。