農業系?の方ならNPKに直ぐにピンとくるのでしょうが、頭の固い電子デバイス系年寄にはサッパリです。NPKって一体何なのよ。でも「窒素N、リン酸P、カリK」と日本語で教えてもらえれば、ようやく理解できますな。なんだ肥料じゃん。なんだとは何だ。肥料もやりすぎるとダメらしいけど、バランスよければいいんじゃね?そうでもない?
※「データのお砂場」投稿順Indexはこちら
今回のサンプルデータセット
R言語に付属のサンプルデータセットをABC順(大文字先)に眺めてます。今回のデータセット名は npk とな。冒頭述べましたるとおり、タイトルからはNPKとはなんじゃらほいでしたが、肥料とわかれば早くも分かった気になっています。大丈夫か。例によって、サンプルデータセットの解説ページが以下に。
Classical N, P, K Factorial Experiment
以下の4つの要因について、エンドウ豆の収量を記録したデータです。
-
- ブロック、1から6までの番号
- N、窒素
- P、リン
- K、カリ
なお、実験に用いられた区画は plot とよばれ、1ブロックには4プロットあるみたいです。1個のプロットの面積は、1/70 エーカ、だいたい 58平米みたいです。収量は1プロットあたりの重量(単位ポンド、約454グラム。)
どうも今回のデータセットは、分散分析(analysis of variance、ANOVA)を練習するためのもののようです。そういえば過去にも「生物系の分散分析」をやったことが何度もあったな~。
データのお砂場(14) R言語、InsectSprays、殺虫剤の効きの分散分析とな?
データのお砂場(48) R言語、chickwts、ニワトリさんの体重、「再び」とな
データのお砂場(22) R言語、PlantGrowth、植物の成長実験、無味乾燥?
データのお砂場(21) R言語、OrchardSprays、果樹園用農薬?の効果とな?
どれも one-way ANOVA とて、ほんとうに薬が効いているのかいな、ということを調べてみているのでした。もうほとんど忘却の彼方。
でも今回のデータセットは、結構複雑で、過去例みたいな感じでは許してくれないみたいです。。。
まずは生データ
例によって生データをロードし、データ形式から確かめてみます。普通のデータフレーム、要因(Factor)データ4種に対して、yieldの数値データが一つ入っている形式みたいです。
上記のサマリをみると、24組のデータは綺麗に区切られていて、ブロック6種に対して各4点づつ、N、P、Kの各要因は、ありーの、なしーので各12点づつのようです。結果、収量は44.2ポンド(約20kg)から69.5ポンド(約31.5kg)となったと。
無理やりボックスプロット
今回のデータセット解説ページには処理例あり、それに沿うと淡々と数値だけが並ぶことになるので、冒頭に掲げるグラフができませぬ。そこで、処理例の趣旨からはハズレるのですが、過去回同様にボックスプロットを行うべし、と思い定めました。
要因は4つありますが、うち一つはブロック番号という畑の区画みたいなもん?ということで、残りNPKの3要因の組み合わせを考えれば8通りしかありません。NPKの8通りの条件にたいして集計すればいいんじゃないかと。
npkNUM <- 100*as.numeric(npk$N) + 10*as.numeric(npk$P) + as.numeric(npk$K) npkWORK <- data.frame(npkCOMB=factor(npkNUM), yield=npk$yield) aggregate(npkWORK$yield, by=list(npkWORK$npkCOMB),mean)
まずは aggregateで平均収量の集計結果です。NPKの三要素について111はすべてが無、222はすべてが有りで、例えば211はNのみあり、P、Kは無しということになります。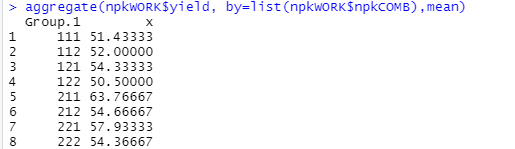
ボックスプロットを描くコマンドが以下に。
boxplot(yield ~ npkCOMB, data=npkWORK, main="npk" ylab="Yield of peas [pounds/plot]")
結果プロットが以下に。一応、赤字でコメント書き加えました。
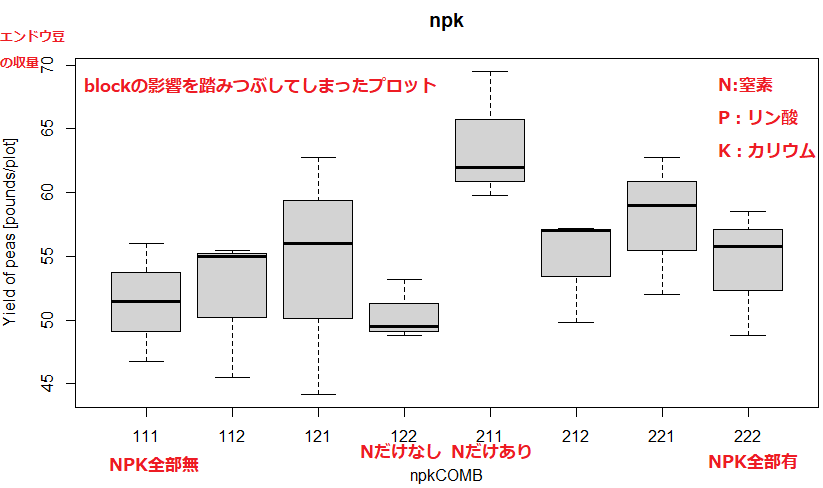
ううむ、肥料は全部あればいい、ってもんでもないみたいね。素人目には明らかに窒素が効いているような気がするのだけれど。。。
処理例に従ってAOV関数使う
今回の処理例、ムツカシーです。まず最初にoptionsとかいって、「グローバルな設定」をいじっているみたいなのだけれど、それがどういう意味になるのかサッパリです。よくわかりません。
それにaov()関数で、分散分析しているのだけれど、黄色のところFactorどおしの*って何よ?ここでの「*」は掛け算ではなくてクロス(線形和+交互作用)ということらしいです。知らんけど。下にでてくるN:Pなどはみな「交互作用」。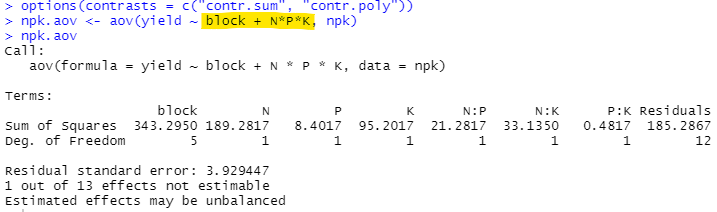
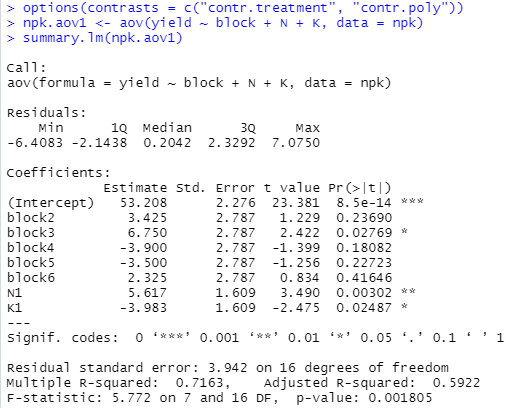
まあ、上記のように処理例通りに処理していただくと、各ブロック、N、P、KそしてNPKの各組み合わせの交互作用全部が解析されるみたいっす。サマリが以下に。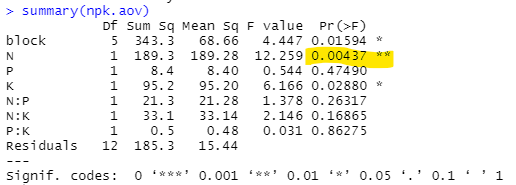
上記みると、やっぱりNは「有意」ね。blockとK(カリ)もまあまあ。交互作用はとりあえず良いのかな。それにPも影響ない感じ。係数計算したものが以下に。
すでにわけわからないのに、処理例はこれでは許してくれず、もう一回オプション変更し、「Pを外して」再度aovを計算してます。こんな感じ。
そして、以下を計算するのです。
se.contrast
上記は、Standard Errors for Contrasts in Model Terms のことみたいです。標準偏差ではなくて、そいつらをまとめた上にある標準誤差じゃと。どうしたらよいの?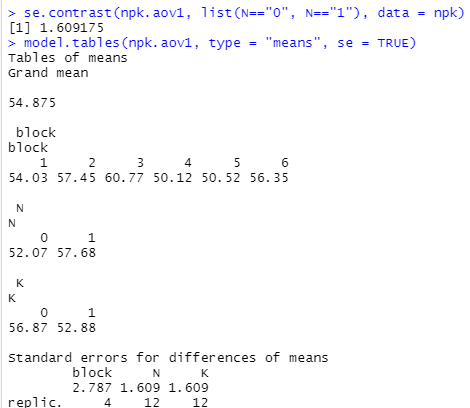
計算はできるものの、処理例でやっていることはサッパリです。ちゃんと基礎から勉強しないとわからんよな、自分。