今回は英国における父と子の “occupational status” 統計です。1979年以前の統計、半世紀くらいは前のもの。「大人の事情」か具体的なことは一切ない、ただ数値(整数の度数)の小さなテーブルです。想像するに、英国は今もそんなに変わっていないのではないかと。それどころか、このところの日本も似てきている?
※「データのお砂場」投稿順Indexはこちら
今回のサンプルデータセット
R言語に付属のサンプルデータセットをABC順(大文字先)に眺めてます。今回のデータセット名は occupationalStatus とな。例によって、サンプルデータセットの解説ページが以下に。
Occupational Status of Fathers and their Sons
「クロス集計表」あるいは「OD表」とみなせるような8x8の表です。
-
- 表側(原因、行)、origin (father’s occupational status; levels 1:8)
- 表頭(結果、列)、destination (son’s occupational status; levels 1:8)
“occupational status”というものが、1から8のレベルに「層別」されているものの、それがどんなものなのか一切の言及がありませぬ。そういう属性に惑わされずにデータ処理に勤しめ?と。ううむ。
まずは生データ
例によって生データをロードして眺めてみます。table型、8×8サイズの表です。行方向に origin、列方向に distination というお名前が付けられていますが、その値は単なる1から8の数字です。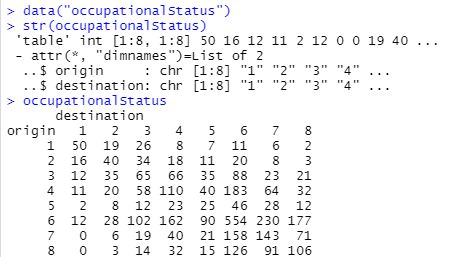
全データをダンプしても上記のように小さなデータセットです。OD表(Origin-Destination Table)と言ってよいのではないかと思います。デバ亀的視点からは1から8が何なのよ、というのは気になるところです。一切の説明ないのですが、以下の処理から勝手に想像(妄想)を膨らませましたです。
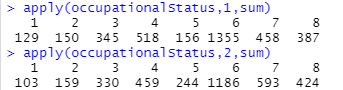
上のapplyが行方向、つまり、origin、父ちゃん側の人数集計となります。下のapplyが列方向、destination、息子側の人数集計であります。レベルは8段階、単純な平均は4.5となりますが、実際に数が多いのはレベル6です。最左端1と再右端の8をみても、明らかに左側の数が少なく、右側にかたよったグラフです。occupational statusとはいうものの、ぶっちゃけ「実入り」で層別しているような気がしてなりませぬ。個人の感想、妄想デス。ちょっぴりだけれど、息子世代の方が右に偏ってないか?
処理例
さて、今回の解説ページには処理例あり、処理例にそって「淡々」と処理を実施してみます。よくわからんよな~。
まずはデータ全体をplot関数に渡してます。こういう漠然としたことをしてもRは、内部でテキトーに判断してそれらしい処理を呼び出してくれるのでうれしい。![]()
結果のプロットは以下のようです。なお、このグラフではX軸側が origin、父ちゃん側で、Y軸側が destination、息子側です。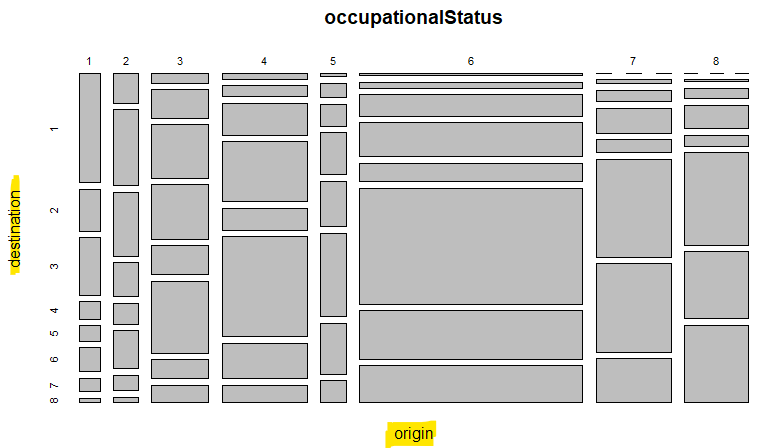
父ちゃんが7,8で、息子が1というケースは皆無。父ちゃんの数は結構いるんだけど。逆に父ちゃんが1なら息子が1というのは多数派と。だいたい父ちゃんが1というのは数でいったら少数派なんだけれども。
さて、このようなデータに対して、処理例では、glm(一般化線形モデル)を適用しようとしてるみたいです。glmについては、いつもお世話になっております以下の同志社大の先生のページなどご覧ください。私はサッパリっす。
まあ、処理例で準備をしている操作はいろいろ参考になります。まずは、対角行列的な奴を生成してます。こんな感じ。
それをファクタ化してます。あらよっと。1本のベクタになってしまったみたい。
行方向を平均値でセンタリングするための準備みたいっす。こんな感じ。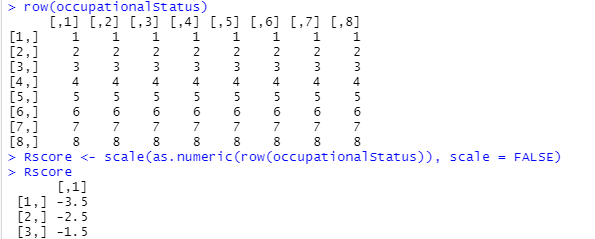
計算結果の末尾は以下に。
同様な操作を列方向にもやってます。わけもわからずえいやー。
こうして準備した、Diag、RScore、CScoreを使ってglmを計算してます。なお以下ででてくるRScore:CScoreの”:”は前回もでてきた「交互作用」の演算子ってことかい?知らんけど。
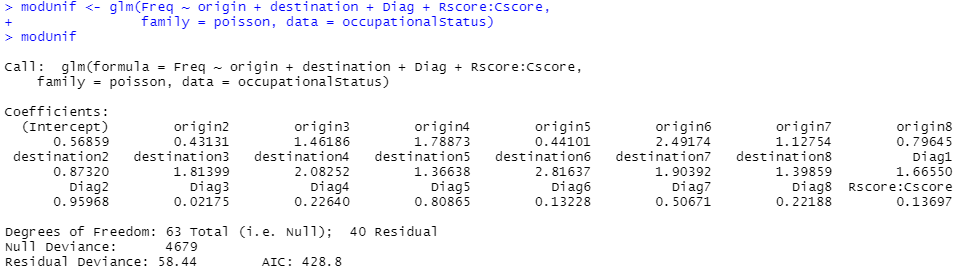
glmの計算結果のサマリが以下に。私はサッパリです。なんじゃらほい。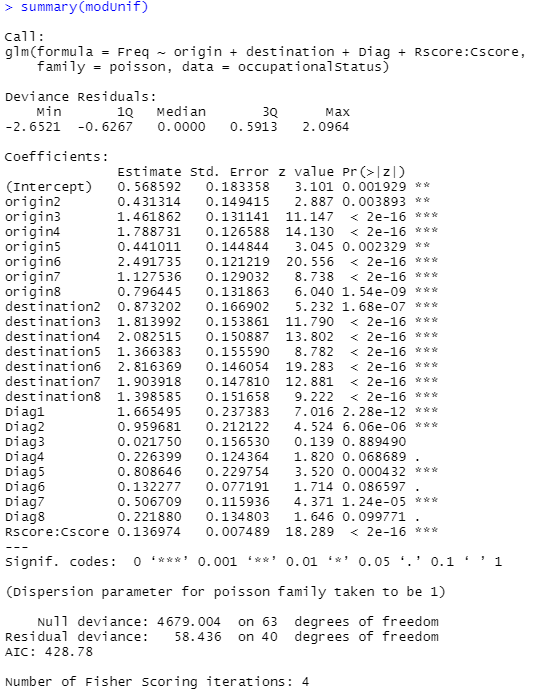
そして結果のプロット。Hit <Return>と促されて4枚もプロットを書き出すことになりました。
最初の一枚。
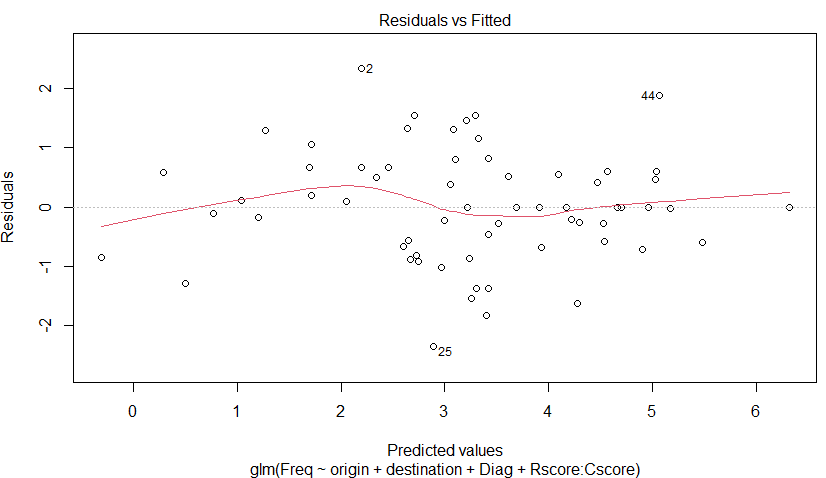
2枚目は、だいたい線上にのっている?
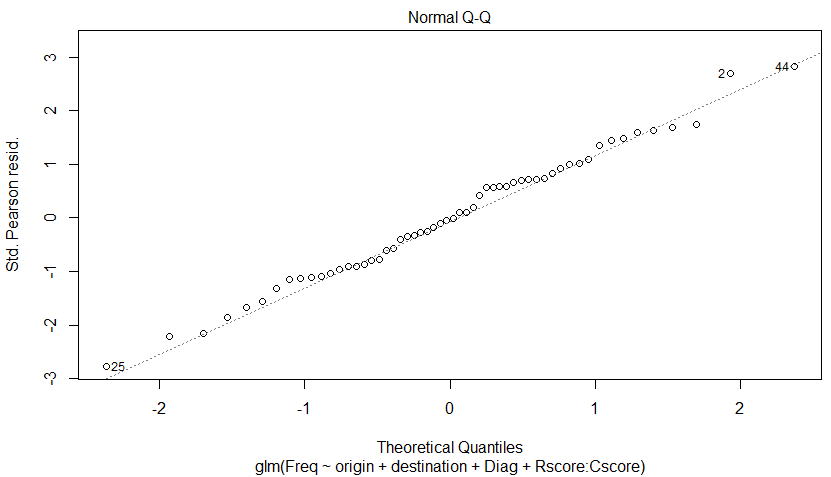
これはどうみたらよいのよ。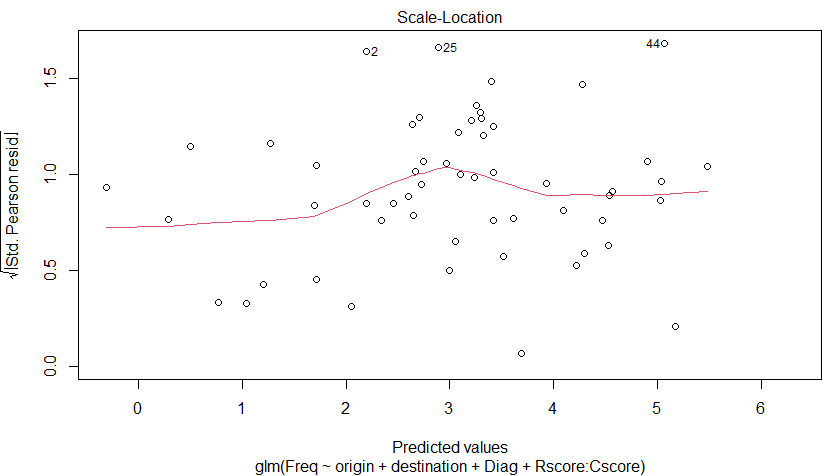
さっきから44番のデータが外れている?
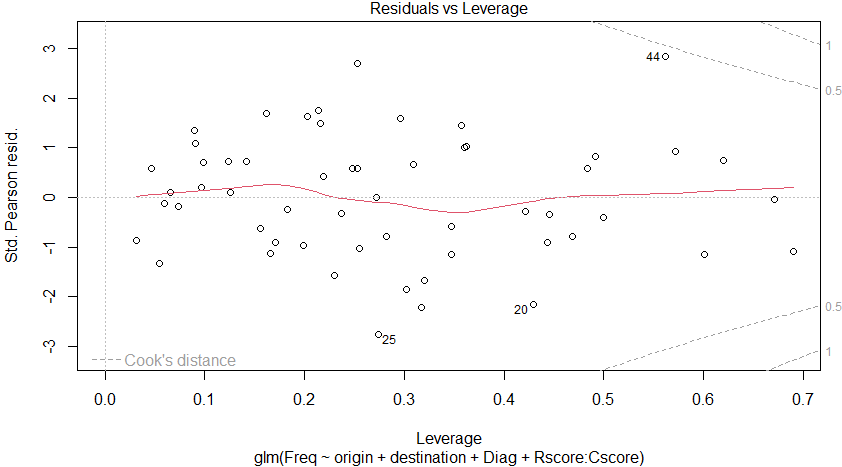
計算して、プロットはできるけれども、結果はサッパリ理解できまっせん。glmってやつを勉強しないと。いつやるんだ?