今回は米国各地の年間平均降水量データです。しかし眼目は「つづり間違い」の訂正みたいです。都市名をタイプしつづけて、つい綴りを間違えてしまったみたい。タイポの訂正ならばちゃちゃっと直して口を拭っておいても良いのに、データの修正方法と修正の検証の事例にしちまっているみたいっす。エラーに悪乗り?やらせじゃないみたいだが。
※「データのお砂場」投稿順Indexはこちら
今回のサンプルデータセット
R言語に付属のサンプルデータセットをABC順(大文字先)に眺めてます。今回のデータセット名は precip とな。例によって、サンプルデータセットの解説ページが以下に。
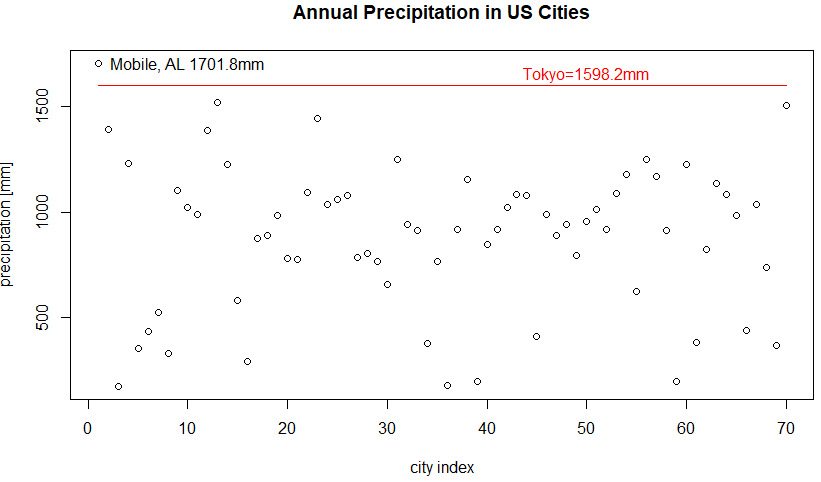
Annual Precipitation in US Cities
米国(プエルトリコ含む)の70都市名とその年間平均降水量、米国のことですから勿論インチ単位のデータセットです。
しかし、どうも今回はデータの数字に関心は向いておらず、データに含まれている「タイポ」、ほんとうは Cincinatiなのに、Cincinnatiとづづっちまったい!という一件についての対処がメインみたいっす。ありがち?
まずは生データ
いつものように生データのロードからです。以下のようにデータは都市数分、70要素の名前付き数値ベクトルであります。
最大値を与える都市を調べてみました。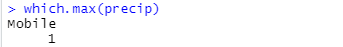
モバイル、いやモービルってどこだっけ?アラバマ州はメキシコ湾岸のあたりでした。ときどきハリケーン襲来するあたりかい?行ったことないけど、蒸し暑そうだな。
データの全貌を知るべくプロットしてみることにいたしました。プロットに際しては
-
- インチ単位をミリメートル単位に換算
- 比較のため、日本国東京の年間平均降水量を示す
- 最大値をあたえるアラバマ州モービル市にはその値を示す
ということにいたしました。なお、東京の年間平均降水量については、気象庁のデータを参照させていただきました。
プロットコマンドはこんな感じ。
precipMM<-precip*25.4 plot(precipMM, main="Annual Precipitation in US Cities", ylab="precipitation [mm]", xlab="city index") lines(rep(1598.2,70), col='red') text(x=50, y=1650, "Tokyo=1598.2mm", col="red") text(x=10, y=1700, paste(names(which.max(precipMM)),", AL ", max(precipMM), "mm", sep=""))
プロットが以下に。なんだ、東京はモービルと似たようなもんじゃん。米国のほとんどの都市は東京より乾いているのね。。。
処理例
今回は解説ページに処理例も掲載されています。まずはプロットから。コマンドはこんな感じ。降水量でソートした上でドットチャートで都市のお名前も列挙してます。
実際のプロットが以下に。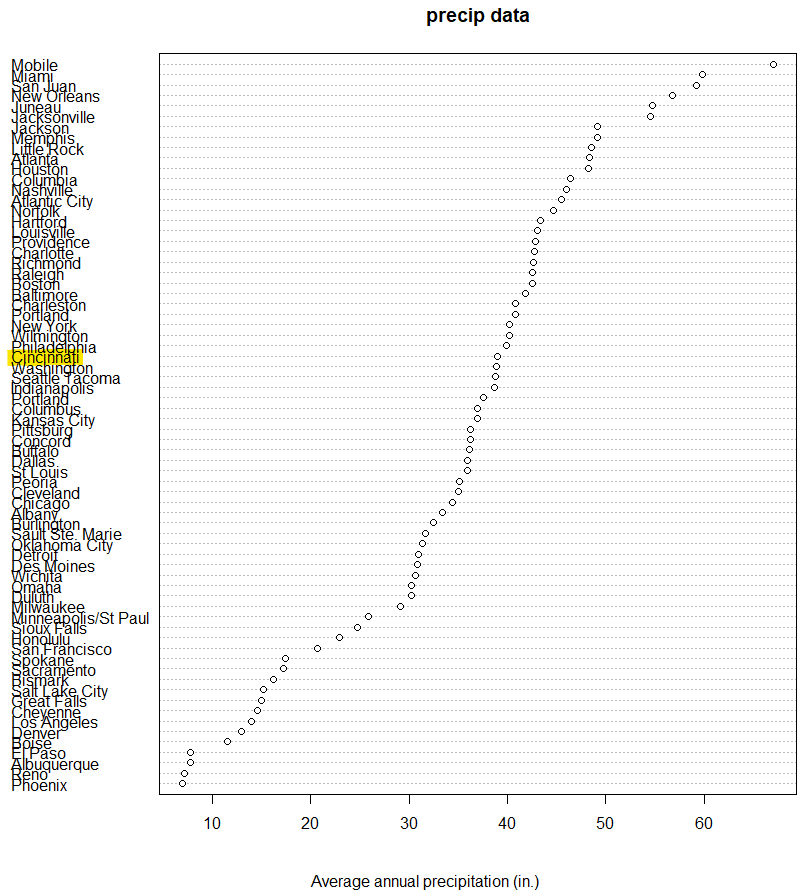
上記の都市名は狭いところに印字されていて読みずらいのですが、黄色のマーカ部分にご注目ください。シンシナティ(オハイオ州、シンシナティといえばレッズしか思い浮かばん。これまた行ったことないケド)の綴りミス発覚であります。よく見つけたなという感じ。
さてその修正と修正確認方法が以下に。
上記の手順で、precip.oに正しく綴られたデータが格納されます。そしてstopifnot関数で、修正前、修正後のデータ(数値)の一致と、綴りをミスッたインデックスの確認、そして修正したシンシナティ以外のお名前が変化していないことを確認してます。ただエラー無なので実行しても何も出力されません。
上記例ではstopifnotが何も文句を垂れないのでその動作がわかりずらいです。そこで自主的にエラー発生ケースを作って実行してみました。Phoenix、アリゾナなど、降水量は0じゃ、と。乱暴な。
というわけで、エラーが検出されています。
しかし[]の中にマイナスのインデックスをいれると、それ以外全部が取り出せるみたいっす。こんな感じ。
R言語は、いろいろ「技」が多くて覚えきらんよな~。