サンプルデータセットは処理のお勉強のためのものなので嘘のデータであっても問題ないと。しかし、私、密かに、サンプルデータセットを通して世界の不思議と世の中を見ておりましたぞ。しかし今回のデータセット(fudged version)とうたっております。なんだこりゃ?何か隠す必要があったのか?大統領支持率。
※「データのお砂場」投稿順Indexはこちら
今回のサンプルデータセット
R言語に付属のサンプルデータセットをABC順(大文字先)に眺めてます。今回のデータセット名は presidents とな。世にpresident様は数あれど、the President of the United States こそが presidentsの中のpresidentじゃと(誰が言ったそんなこと。)例によって、サンプルデータセットの解説ページが以下に。
Quarterly Approval Ratings of US Presidents
サンプルデータセットは古いものが多いので、これも御多分にもれず第二次大戦後から1970年代までの古い大統領支持率(4半期毎)のデータです。ただし、a fudged version と書かれてます。でっち上げ版?ともかく実際のデータとは違うみたいです。どういう意図のデータなのか知りたかったのですが、上記の解説ページには、「詳しいことは McNeil氏の本を見よ」としか書かれておりませぬ。そのために1977年にニューヨークで出版された本を探すことはあるまい。。。
まずは生データ
まあ、上記のようなデータなので、これを通して世の中の動きを顧みることは断念しました。ううむ、やる気が出ないっす。まずはロードから。
時系列(ts)データみたいですな。120点のデータなので先頭の方から半分くらい見てみます。こんな感じ。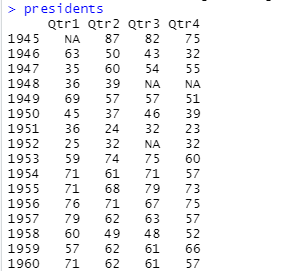
各年の4半期毎のデータみたいなんですが、結構NAとかいう期が多くないかい。実際に調査をしなかったのか、集計した誰かの手抜かりで残っていないのか、はたまた、fudgedのせいなのか?ともかく fudgedと言われるとどのデータにも疑いの目でみたくなるので何だかな。単に手法を勉強するだけと割り切ればよいのだろうけれども凹むのは、いまだ木鶏たりえず、違うか。
とりあえずグラフ化
tsのままだと、ggplot2を使って「新聞社テイストのプロット」が出来ないので以下のようにしてtsデータを無理やりデータフレームに変換して行いました。
yearTS=time(presidents)
year=yearTS[1:length(year)]
apprating=presidents[1:length(presidents)]
pressidents.df <- data.frame(year, apprating)
p<-ggplot(data=pressidents.df, aes(x=year, y=apprating))+geom_line(linewidth=2)
p1<-p + labs(title="Quarterly Approval Ratings of US Presidents(a fudged version)")
p1<-p1 + ylab("Approval Ratings[%]") + theme_economist()
p1
なお、4半期毎のタイム・シリーズなので、一端time()関数で年と4半期からなる時系列を、1950.025みたいな小数点数の時系列に変換し、それをベクトルとして取り出すようなまどろっこしい操作をしています。
本当はニューヨークタイムス風とかにできれば風味がよかったのですが、いつもの癖でエコノミスト誌風のグラフを指定してしまいました。エコノミストは英国の雑誌だよ。トホホ。こんな感じ。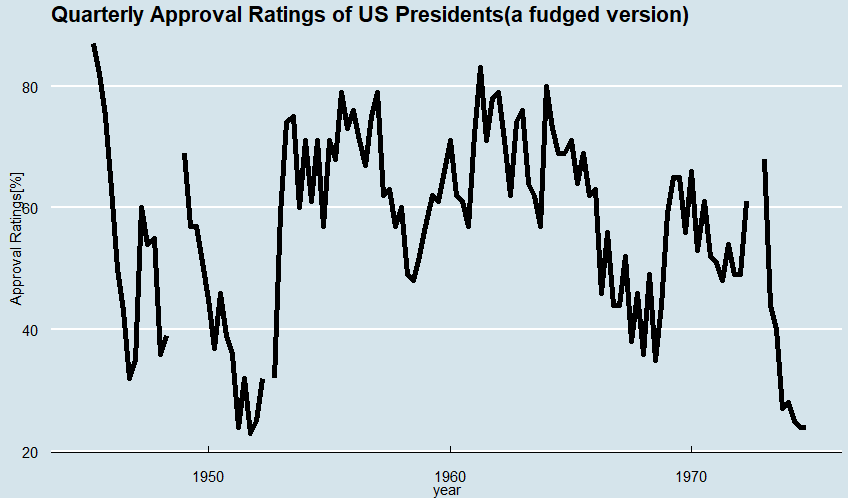
途中NAのデータが結構あるので、グラフがちぎれてます。WARNINGも出力されてましたが、しかったないっす。
本当は山と谷(とくに谷)と当時の事件を調べてみると面白そうだったんだけれども、データはfudged、やる気がおきませぬ。
処理例
解説ページに処理例が載っているのですが、今回はグラフを描いておしまいでした。時系列データのままのプロット。このグラフであれば素のままplotにtsデータを渡してやるだけで十分だな。上のような無駄な処理はいらんと。
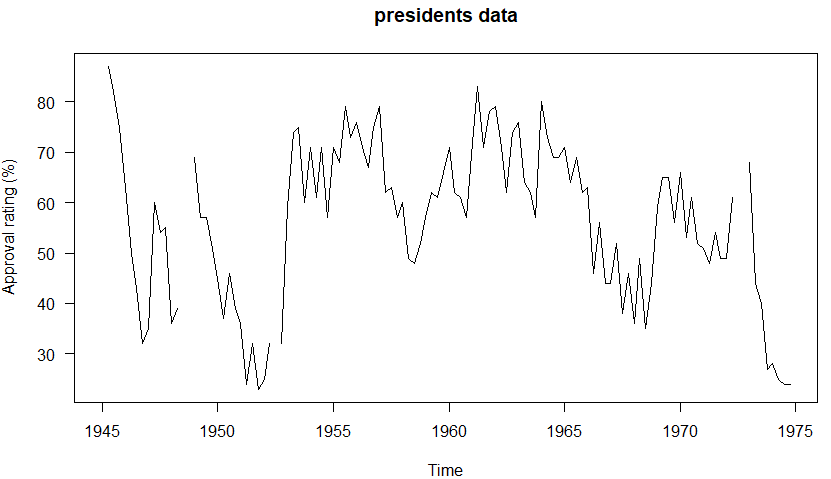
fudged、やめてくれ。やる気がおきんぜよ。