前回までSIMD(ベクトル)レジスタ間での転送を練習してきましたが、今回は汎用(整数)レジスタとSIMDレジスタ間での転送を練習してみます。前回も登場したINS命令とDUP命令がここでも登場します。またUMOVとかSMOVとか一味違う奴らも登場。例によってMOVはエイリアスなんだけれどここでは幅を利かせてるみたい。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
整数レジスタとSIMD(ベクトル)レジスタ間の転送
整数レジスタはWx(xはレジスタ番号)と呼ばれれば32ビット幅、Xxと呼ばれれば64ビット幅です。SIMDレジスタとはビット幅が異なるので、相互の転送は対称にはなりえません。非対称ね。ざっくりとまとめると以下のようになります。
-
- 整数レジスタの内容をSIMDレジスタの要素にDuplicate
- 整数レジスタの内容をSIMDレジスタの要素にInsert
- SIMDレジスタの要素を整数レジスタにMove
1は整数レジスタの内容を1要素としてみて、SIMDレジスタに複製して詰め込むもの。前回も登場したDUPというニーモニックのソースに整数レジスタを指定することで行えます。ただし、Duplicateするデスティネーションのビット幅は、バイト(B)、ハーフワード(H)、ワード(S)、ダブルワード(D)と選択の余地あり。また、SIMDレジスタも64ビット幅とするか128ビット幅とするかの選択もあり。デスティネーション側の要素指定はビット幅で7種類ということになります。メンドクセー。
2も1同様にビット幅の選択肢があります。さらに特定要素を1個書き換えることになるので要素の指定も必要です。ニーモニックはINSですが、MOVと書いても良いみたいです。いつものエイリアスね。でもマニュアル読むとこのケースでディスアセンブラはMOVとディスアセンブルするらしいのでご優待です。どっちがエイリアスなんだかなあ。知らんけど。
3は、1,2と逆方向でSIMDレジスタの要素を整数レジスタに転送します。整数レジスタのビット幅はWかXなのだけれど、転送元のSIMD要素のビット幅はいろいろです。整数扱いだけれど、符合拡張したいケースもあると思われるので、ニーモニックは2種類、符号無のUMOVと符号付のSMOVが用意されとります。また、例によってUMOVの一部のオペランド組み合わせはMOVと記述してもよいと(またまたエイリアスね。)
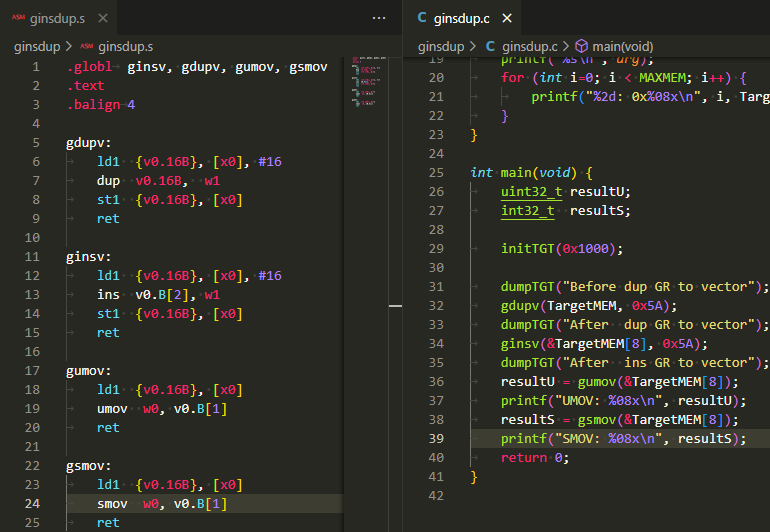
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。ビット幅はいろいろとれるので、今回は一番コマケー奴ということでバイトにしてみました。
.globl ginsv, gdupv, gumov, gsmov
.text
.balign 4
gdupv:
ld1 {v0.16B}, [x0], #16
dup v0.16B, w1
st1 {v0.16B}, [x0]
ret
ginsv:
ld1 {v0.16B}, [x0], #16
ins v0.B[2], w1
st1 {v0.16B}, [x0]
ret
gumov:
ld1 {v0.16B}, [x0]
umov w0, v0.B[1]
ret
gsmov:
ld1 {v0.16B}, [x0]
smov w0, v0.B[1]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。例のとおりで前回のソースの「チョイ変」っす。メモリにテキトーな値を並べておいてSIMDレジスタにロード、汎用レジスタからdupとinsした結果を再びメモリにストアして眺めてます。umovとsmovについては読みだした結果を素直にレジスタに返して吟味?しております。
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (16)
uint32_t TargetMEM[MAXMEM];
extern void gdupv(uint32_t *, uint8_t);
extern void ginsv(uint32_t *, uint8_t);
extern uint32_t gumov(uint32_t *);
extern int32_t gsmov(uint32_t *);
void initTGT(uint32_t c) {
for (int i=0; i < MAXMEM; i++) {
TargetMEM[i] = c * (i+1);
}
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < MAXMEM; i++) {
printf("%2d: 0x%08x\n", i, TargetMEM[i]);
}
}
int main(void) {
uint32_t resultU;
int32_t resultS;
initTGT(0x1000);
dumpTGT("Before dup GR to vector");
gdupv(TargetMEM, 0x5A);
dumpTGT("After dup GR to vector");
ginsv(&TargetMEM[8], 0x5A);
dumpTGT("After ins GR to vector");
resultU = gumov(&TargetMEM[8]);
printf("UMOV: %08x\n", resultU);
resultS = gsmov(&TargetMEM[8]);
printf("SMOV: %08x\n", resultS);
return 0;
}
実験結果
以下のようにしてビルドして実行しています。
$ gcc -g -O0 ginsdup.c ginsdup.s $ ./a.out
標準出力に「ダラダラ」現れる結果を折りたたんで、見やすいように関係個所を枠で囲ってみました。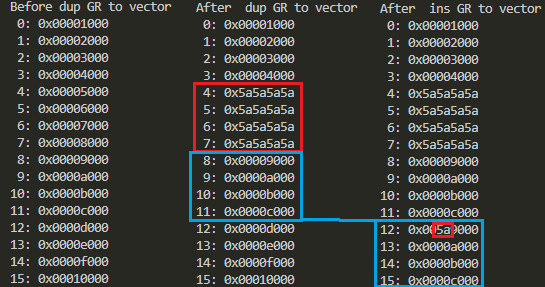
中央赤枠が バイト幅でDUPした結果です。ビッシリ0x5aという値が繰り返されておりますな。右下の青枠がバイト幅で要素[2]にINSした結果です。SIMDレジスタをロードしてストアしている青枠の中に、汎用レジスタからバイト幅INSした結果が赤枠0x5aとして現れとります。
一方、UMOVとSMOVでは、どちらも上記の8番目にダンプされている0x0000900の下から2バイト目の0x90を取り出して、汎用レジスタに転送しています。UMOVとSMOVで符合の始末の扱いが変わっているのが分かると思います。
動作は明快、だと思うんですけど言葉で書くのはシンドイな。アセンブラで書きたい。書いてるだろ~。