今回練習するのは frecps 命令です。なんじゃそれ?という感じ。これぞニュートン法(ニュートン・ラフソン法)で方程式を解く(当然SIMD命令を駆使して)ときに活躍する命令なのであります。遥かなる太古の時代、大学の数値解析の授業の最初の方でニュートン法やりましたな。最近の縁の下ではこういう命令が駆使されておる、と。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
FRECPSとFRSQRTS
今回、練習してみるのは「なんだかよく分からん」以下の2つの命令です。
-
- FRECPS、Floating-point peciprocal step (vector and sclar form)
- FRSQRTS、Floating-point peciprocal square root step (vector and sclar form)
字ずらを眺めていてもサッパリなので、御本家Arm様の以下のページを参照してみます。
上記を読めば、命令の動作そのものは理解可能ですが、何に使うんだか分かりません。使い途も書いておいてよ、という感じ。
調べてみれば、数値解析の論文などがチラホラ見つかります。ニュートン法やるときにこれがあると良いみたいっす。知らんけど。調べた中では、ScienceDirect様の以下のページにそのものズバリA64のSIMD命令の話が書かれていました。
上記の中の、Adavnced SIMD instructions というところにA64の話が書かれてます。他にもGPUでの活用とかも書かれているので、現代(モダーンで並列なプロセッサども)においてニュートン・ラフソン法をやるときには必須みたい。勿論、x86_64のAVXにも同様な命令はあるみたいです。大昔、FORTRAN(大文字)で「素直な」ニュートン法で方程式の根が求まったとか、発散したとか言っていたころからすると段違いね。まあ、モダンなソフトウエアの場合、その内部の奥深くに方程式を解くためのソルバなどは隠されていて、「ニュートン法」なんてものが表に見えること自体、まずないのだけれど。
本シリーズでは算法(アルゴリズム)に深入りしたくないので今回はそのまま(って逃げてるな、自分。)後で別シリーズでやってみるかな~でも難しそうだし。。。
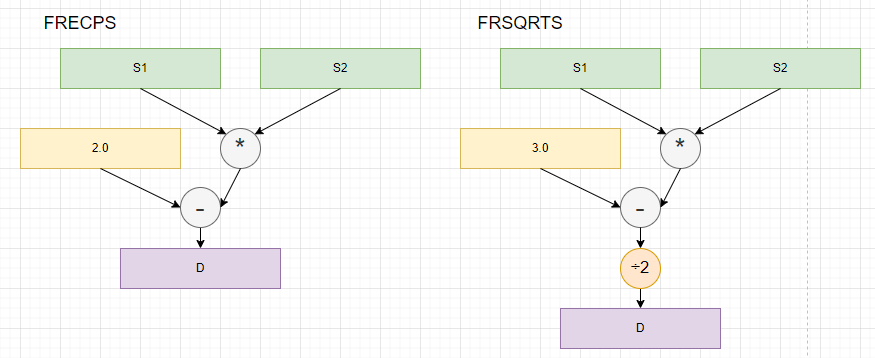
命令そのものの動作は、図にすれば簡単。こんな感じ。2命令、データの流れはほぼほぼ一緒じゃん。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。命令そのものは、同じニーモニックでスカラーでもベクトルでもお好みのまま。オペランドには以下の3種類をとれます。
-
- 半精度
- 単精度
- 倍精度
しかし実習機はARMv8p0なので半精度はありません。メンドイので例によって単精度のベクトルの場合のみ練習してみます。
.globl frecpsSV, frsqrtsSV
.text
.balign 4
frecpsSV:
ld1 {v1.4S, v2.4S}, [x0], #32
frecps v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
frsqrtsSV:
ld1 {v1.4S, v2.4S}, [x0], #32
frsqrts v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。結果をセルフテストしてOK/NGにすることはせず、これまた通例通り、標準出力垂れ流しです。その方が「やっている感」がするし。
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (12)
float TargetMEM[MAXMEM];
extern void frecpsSV(float *);
extern void frsqrtsSV(float *);
void initTGT(float c) {
for (int i=0; i < MAXMEM; i++) {
TargetMEM[i] = c * (i + 1.0);
}
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < MAXMEM; i++) {
printf("%02d: %f\n", i, TargetMEM[i]);
}
}
int main(void) {
initTGT(0.01);
dumpTGT("Before frecps");
frecpsSV(TargetMEM);
dumpTGT("After frecps");
frsqrtsSV(TargetMEM);
dumpTGT("After frsqrts");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 frecps.c frecps.s $ ./a.out
標準出力に「ダラダラ」現れる結果を折りたたんで、見やすいように関係個所を枠で囲ってみました。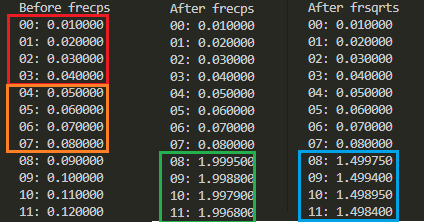
赤枠の4要素がソース1、オレンジ枠の4要素がソース2です。緑枠がFRECPS命令の実行結果、青枠がFRSQRTS命令の実行結果です。計算結果は合っている筈。算法は分からんケド。