SIMDの即値シフト命令の練習4回目。今回は勝手命名「即値シフトのアキュムレート系」を練習。即値シフト後の値をデスティネーションレジスタの値に加えるものです。命令を並べてみるとこの一族は「直交的」です。A64にはめずらしい対称性?ただし、アキュムレート一族は右シフトのみ。根本的なところで対称性は破れている?違うか。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
今回練習の「アキュムレート」一族
今回練習の一族には何やら明確な意図があるようです。即値右シフトで「桁合わせ」をして足し込むと。その際、以下の選択肢があります。
-
- データは符号付か符号無か
- シフトで消えた下の方を丸めて足すか、切り捨てるか
よって2x2で合計4命令であります。こんな感じ。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。今回もSIMD要素の幅は、バイト、ハーフワード、ワード、ダブルワードをとれるのですが、これまた手抜きでワード(32ビット)のみ練習してます。シフト量は右4ビットきめうち、HEX表記で「一桁」だけ右シフトってことだな。
.globl srsra4V, ssra4V, ursra4V, usra4V
.text
.balign 4
srsra4V:
ld1 {v0.4S, v1.4S}, [x0]
srsra v0.4S, v1.4S, #4
st1 {v0.4S}, [x0]
ret
ssra4V:
ld1 {v0.4S, v1.4S}, [x0]
ssra v0.4S, v1.4S, #4
st1 {v0.4S}, [x0]
ret
ursra4V:
ld1 {v0.4S, v1.4S}, [x0]
ursra v0.4S, v1.4S, #4
st1 {v0.4S}, [x0]
ret
usra4V:
ld1 {v0.4S, v1.4S}, [x0]
usra v0.4S, v1.4S, #4
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。符号付、符号無と扱うデータは異なりますが、例のごとくC言語レベルでは皆 uint32_t で宣言してます。手抜きだよ。
#include <stdio.h>
#include <stdint.h>
#include <math.h>
#define MAXMEM (8)
uint32_t TargetMEM[MAXMEM];
extern void srsra4V(uint32_t *);
extern void ssra4V(uint32_t *);
extern void ursra4V(uint32_t *);
extern void usra4V(uint32_t *);
void initTGT() {
TargetMEM[0] = 0x00010000;
TargetMEM[1] = 0x00010000;
TargetMEM[2] = 0x00010000;
TargetMEM[3] = 0x00010000;
TargetMEM[4] = 0x00000028;
TargetMEM[5] = 0x00000027;
TargetMEM[6] = 0xFFFFFFE8;
TargetMEM[7] = 0xFFFFFFE7;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i<4; i++) {
printf("%02d: %08x\n", i, TargetMEM[i]);
}
}
int main(void) {
initTGT();
srsra4V(TargetMEM);
dumpTGT("srsra v0.4S, V1.4S, #4");
initTGT();
ssra4V(TargetMEM);
dumpTGT("ssra v0.4S, V1.4S, #4");
initTGT();
ursra4V(TargetMEM);
dumpTGT("ursra v0.4S, V1.4S, #4");
initTGT();
usra4V(TargetMEM);
dumpTGT("usra v0.4S, V1.4S, #4");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 simdSFTImm4.c simdSFTImm4.s $ ./a.out
実行結果が以下に。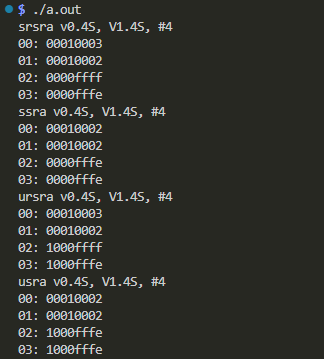
丸め有り(srsraとursra)と無(ssraとusra)で結果の値が1違っているのが分かりますな。また符号付き数としてシフトする(srsraとssra)と符号無し数としてシフトする(ursraとusra)で負の数をシフトしてから足し込んだときの値が異なるのも分かりますな。予定通り。ま、それでどうしたと言われたらどうもしませんのですけど。
淡々と練習していけば命令多過ぎA64の命令も何時かは尽きる?それまで生きていたいものだが。