前回まで「ベクトル横断」命令群を練習してました。ベクトルにつまった要素を縮約処理して1個のスカラーにまとめてしまうもの。しかし、スカラーにまでまとめる前にもう一手間あるんじゃないすか、というのが今回のペア操作です。複数SIMDレジスタにまたがる長大なベクトルを隣接要素どうしで処理して半分の長さに縮めるもの。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
SIMD pairwise arithmetic
さて今回から練習する「ペアワイズな」命令どもは以下のように分類できます。
-
- 整数を処理する命令
- ADDP
- SMAXP
- SMINP
- UMAXP
- UMINP
- 浮動小数を処理する命令
- FADDP
- FMAXP
- FMAXNMP
- FMINP
- FMINNMP
- 整数を処理する命令
皆「ペアワイズ」処理とて末尾の「P」の文字が共通。その意味するところはSIMDレジスタのお隣どおし(偶数番目の要素とその1個上の奇数番目の要素)を処理して1要素の結果を得る、ということであります。
今回は整数を処理する最初の5命令を練習してみたいと思います。加算命令ADDPと、最大値、最小値をもとめる命令どもですが、符号付整数と符号無整数で命令にSとUができるので合計5命令であります。
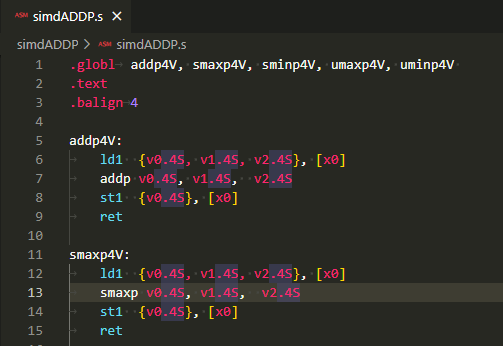
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。SIMD要素としては、バイト、ハーフワード、ワード、ダブルワードの選択肢があり、SIMDレジスタも64ビット幅か128ビット幅か選べるのでありますが、SIMDレジスタは128ビット幅のみ、SIMD要素はワード(32ビット)のみであります。いつもの手抜きなスタイル。
.globl addp4V, smaxp4V, sminp4V, umaxp4V, uminp4V
.text
.balign 4
addp4V:
ld1 {v0.4S, v1.4S, v2.4S}, [x0]
addp v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
smaxp4V:
ld1 {v0.4S, v1.4S, v2.4S}, [x0]
smaxp v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
sminp4V:
ld1 {v0.4S, v1.4S, v2.4S}, [x0]
sminp v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
umaxp4V:
ld1 {v0.4S, v1.4S, v2.4S}, [x0]
umaxp v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
uminp4V:
ld1 {v0.4S, v1.4S, v2.4S}, [x0]
uminp v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。アセンブリ言語命令としては符号付、符号無の種別があるのですが、C言語レベルではその辺踏みつぶしてしまって全部 uint32_t にしちまってます。機械語命令に精通したお兄さん、お姉さんがたには、べたな16進表記の方が分かり易いかと。
#include <stdio.h>
#include <stdint.h>
#include <math.h>
#define MAXMEM (12)
uint32_t TargetMEM[MAXMEM];
extern void addp4V(uint32_t *);
extern void smaxp4V(uint32_t *);
extern void sminp4V(uint32_t *);
extern void umaxp4V(uint32_t *);
extern void uminp4V(uint32_t *);
void initTGT() {
TargetMEM[0] = 0;
TargetMEM[1] = 0;
TargetMEM[2] = 0;
TargetMEM[3] = 0;
TargetMEM[4] = 0x00000123;
TargetMEM[5] = 0x00000456;
TargetMEM[6] = 0xFFFFF000;
TargetMEM[7] = 0xFFFFF001;
TargetMEM[8] = 0x10001111;
TargetMEM[9] = 0x20002222;
TargetMEM[10] = 0x80000000;
TargetMEM[11] = 0xFFFFFFFF;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i<4; i++) {
printf("%02d: %08x %08x -> %08x\n", i, TargetMEM[2*i+4], TargetMEM[2*i+5], TargetMEM[i]);
}
}
int main(void) {
initTGT();
addp4V(TargetMEM);
dumpTGT("addp");
initTGT();
smaxp4V(TargetMEM);
dumpTGT("smaxp");
initTGT();
sminp4V(TargetMEM);
dumpTGT("sminp");
initTGT();
umaxp4V(TargetMEM);
dumpTGT("umaxp");
initTGT();
uminp4V(TargetMEM);
dumpTGT("uminp");
return 0;
}
実機実行結果の確認
以下のようにして ビルドして実行しています。
$ gcc -g -O0 simdADDP.c simdADDP.s $ ./a.out
標準出力に現れた結果が以下に。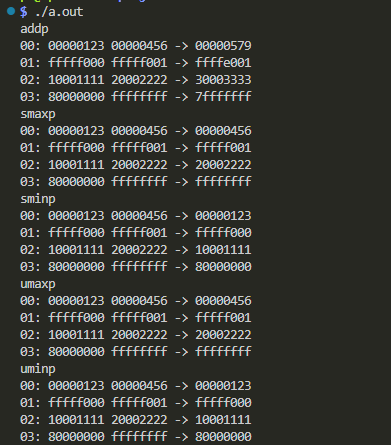
「ペアワイズ」の処理を繰り返せば、どんなに長大なベクトルでも半分の長さに縮められるっと。