前回はベクトルレジスタ2個の隣接要素どうし演算、ベクトルレジスタ1個分(半分の長さ)に縮める「ペアワイズ」操作のうち整数演算の命令5つを練習。今回は残りの「ペアワイズ」操作命令5個を練習してみます。今度は浮動小数点命令ね。やっぱりADDとMAX、MIN操作なのだけれどもNANの扱いでMAX、MINは各2命令あり。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
SIMD pairwise arithmeticのこり
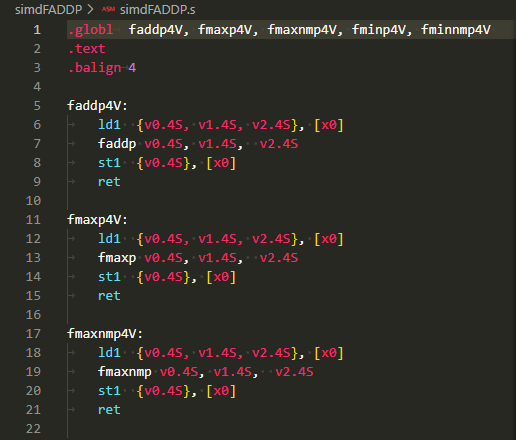
今回練習する、浮動小数点数を処理する命令は以下の5つです。
-
- FADDP
- FMAXP
- FMAXNMP
- FMINP
- FMINNMP
全て同じレジスタの隣接要素どうしの演算です。FMAXとFMINについて「NM」がついている命令と無い命令があります。これは演算の中にNAN(NOT A NUMBER)が現れたときに、NANを無視して数値の方をとる「NM付」と、NANが現れたら「処理できね~」ということでNANを返す「無」のNANの扱いの違いです。メンドイよ。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。ARMv8p0は半精度浮動小数を持っていないので、使用可能なSIMD要素としては、単精度、倍精度の2つですが、テストしているのは単精度のみです。いつもの手抜き。
.globl faddp4V, fmaxp4V, fmaxnmp4V, fminp4V, fminnmp4V
.text
.balign 4
faddp4V:
ld1 {v0.4S, v1.4S, v2.4S}, [x0]
faddp v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
fmaxp4V:
ld1 {v0.4S, v1.4S, v2.4S}, [x0]
fmaxp v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
fmaxnmp4V:
ld1 {v0.4S, v1.4S, v2.4S}, [x0]
fmaxnmp v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
fminp4V:
ld1 {v0.4S, v1.4S, v2.4S}, [x0]
fminp v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
fminnmp4V:
ld1 {v0.4S, v1.4S, v2.4S}, [x0]
fminnmp v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。”NM”付とそうでない命令の差はNANを食わせてみないと明らかにならないので、ことさらNANを食わせるコードになってます。
#include <stdio.h>
#include <stdint.h>
#include <math.h>
#define MAXMEM (12)
float TargetMEM[MAXMEM];
extern void faddp4V(float *);
extern void fmaxp4V(float *);
extern void fmaxnmp4V(float *);
extern void fminp4V(float *);
extern void fminnmp4V(float *);
void initTGT() {
TargetMEM[0] = 0;
TargetMEM[1] = 0;
TargetMEM[2] = 0;
TargetMEM[3] = 0;
TargetMEM[4] = 1.23;
TargetMEM[5] = 4.56;
TargetMEM[6] = -1.11;
TargetMEM[7] = -1.22;
TargetMEM[8] = 1.81;
TargetMEM[9] = 2.91;
TargetMEM[10] = 3.333;
TargetMEM[11] = 6.67;
}
void initTGT2() {
TargetMEM[0] = 0;
TargetMEM[1] = 0;
TargetMEM[2] = 0;
TargetMEM[3] = 0;
TargetMEM[4] = 1.23;
TargetMEM[5] = 4.56;
TargetMEM[6] = -1.11;
TargetMEM[7] = -1.22;
TargetMEM[8] = NAN;
TargetMEM[9] = 2.91;
TargetMEM[10] = 3.333;
TargetMEM[11] = 6.67;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i<4; i++) {
printf("%02d: %8.5f %8.5f -> %8.5f\n", i, TargetMEM[2*i+4], TargetMEM[2*i+5], TargetMEM[i]);
}
}
int main(void) {
initTGT();
faddp4V(TargetMEM);
dumpTGT("faddp");
initTGT2();
fmaxp4V(TargetMEM);
dumpTGT("fmaxp");
initTGT2();
fmaxnmp4V(TargetMEM);
dumpTGT("fmaxnmp");
initTGT2();
fminp4V(TargetMEM);
dumpTGT("fminp");
initTGT2();
fminnmp4V(TargetMEM);
dumpTGT("fminnmp");
return 0;
}
実機実行結果の確認
以下のようにして ビルドして実行しています。
$ gcc -g -O0 simdFADDP.c simdFADDP.s $ ./a.out
標準出力に現れた結果が以下に。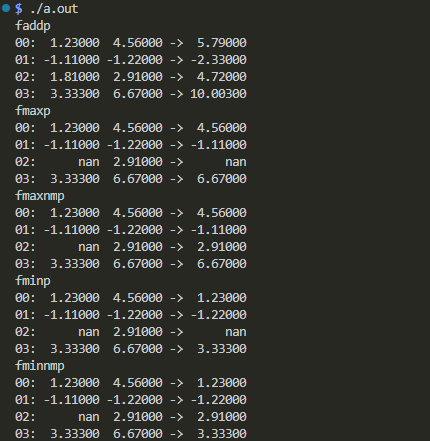
波乱なし、予定どおりか。