
Common Lispの系譜を継ぐマイコン上のuLispをラズパイPico2上で練習中です。前回までで算術演算系の関数どもはひと段落。今回は、文字と文字列を扱うものどもです。Common Lispでは多数ある関数どもが uLisp ではこじんまりとした数です。必要最小限?知らんけれども。いくつかは既に練習済じゃと。
※Lispと一緒 投稿順 index はこちら
※実機確認は Raspberry Pi Pico2で行ってます。
※使用させていただいとります uLisp のバージョンは 4.6b (Arm用)です。
※uLispとCommon Lispとの動作比較のために使わせていただいている処理系は以下です。
SBCL 2.2.2 (SBCL = Steel Bank Common Lisp )
練習済の関数と今回練習の関数
文字、文字列の関数のうち以下の2関数は第9回にて既に練習済です。「ピー」一族の関数。文字か文字列か判断するもの。
-
- characterp
- stringp
今回は以下の9関数を練習してみます。Common Lispなどでは、char-ナンチャラ、とかstring-ナンチャラというお名前の関数がやたら大量にある感じがしますが、uLispは控えめ。
-
- char
- char-code
- code-char
- string=
- string/=
- string<
- string>
- string>=
- string<=
文字列から文字を取り出す char 関数
まずはCommon Lispで文字列から文字を取り出してみます。
過去回でやったとおり、「文字」は #\ナンチャラというスタイルのメンドクセー記法になります。char関数の第2引数は先頭文字を0番目とする数え方っす。
同じことを uLispでやったものが以下に。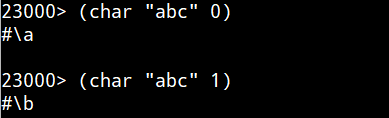
文字と文字コード間の変換
表示してしまうとメンドクセー記法になる「文字」データと、文字コード(数字)間の変換用の関数を使ってみます。まずはCommon Lisp。
小文字の a はASCIIコードで97(十進)ね。なお Common Lispの場合ユニコード文字を与えても正常に処理できるようです。あたりまえか。
uLispが以下に。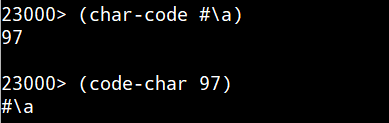
なお、uLispにユニコード文字など与えるとマルチバイト文字の最初のバイトだけを拾ってトボケた値を返してくるようです。
文字列の比較
文字列比較は「辞書順、アルファベットの」です。ただし Common Lisp/uLispにはクセがあり(差異はありませぬ)、偽の場合はNILが返りますが、真の場合は、Tが返る関数もあれば、一致の文字数(数値)を返してくるものもあるみたい。NILでないなら真だ、と。
まずは一致、不一致、Common Lispの場合。
string=(一致)は、一致するとTを返してきますが、string/=(不一致)は一致しないと先頭から一致した文字数を返してくれるみたい。
uLispではどうよ。
uLispでの挙動も一致。ちょっとクセつヨだけども。
文字列の大なり小なり、Common Lisp。
uLispの結果。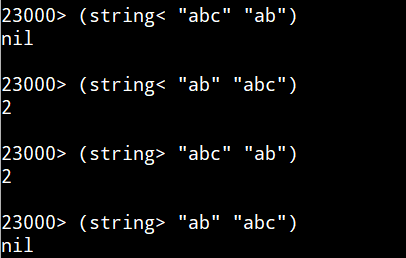
大なりイコール、小なりイコール、Common Lispの場合。
uLispの場合。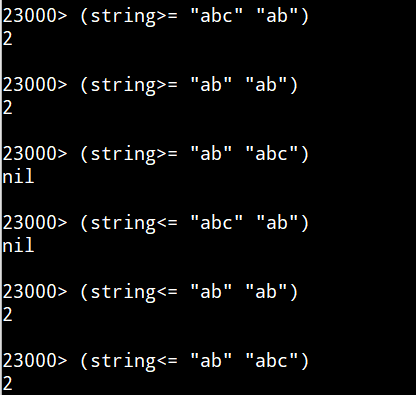
関数の数は少ないケド、概ね挙動は一致。