前回はRISC-Vプラットフォームタイマを試用。このHWは唯一無二。今回はラズパイPico系にユニークなインターポレータを試用してみます。コア毎に2個のインターポレータを装備、そして1個のインターポレータには2レーンあり、合計8個の演算パスを平行利用可能です。今回は基本操作POPをつかって等差数列を生成してみます。
※Pico関係投稿一覧は こちら 『Pico三昧』は一覧の末尾付近にひっそりと。
※Pico2対応のMicroPython処理系(バイナリ、uf2形式)は以下のURLからダウンロード可能です。
https://micropython.org/download/RPI_PICO2/
※動作確認に使用しているMicroPython処理系は以下です。
MicroPython-1.24.0-riscv–with-newlib4.3.0
上記はRISC-Vコア用のバイナリですが、Arm用でも同様に動くかと(確かめてないケド。)
インターポレータ(Interpolator)
ラズパイPicoのRP2040からインターポレータ(補間器と訳すべきか?)が搭載されています。SIO(シングルサイクルIO)内に出入口のレジスタがあるハードウエアの整数演算データパスです。なんでも計算できるというわけではありませんが、パターンにハマった演算であればプログラムで処理するより高速に演算可能なHWです。その名の通り補間計算などに使えますが利用方法はアイディア次第かと。本シリーズでも以下の過去回を先頭に複数回練習してみてます。
Pico三昧(7) Pico C/C++SDKでinterp その1、popとpeek
ただし、過去回ではラズパイPicoのRP2040上でC/C++SDK利用でした。今回はPico2上のMicroPythonから「ゆるゆる」と動作確認してみます。その代わり、コアはRISC-V、そしてデュアル・コアでインターポレータを使ってみます。
インターポレータはそれぞれのコアが独立な2個を利用できます。コア0から見えるインターポレータ0とコア1から見えるインターポレータ1は異なるハードウエアで同時に利用可能です。それぞれのインターポレータには2レーンあり、単独演算に使うも、2レーン共同で結果を得てもよし、というスタイルです。
なお、SIO内のハードはセキュア、ノンセキュアで2重化されているものが多いですが、インターポレータは単なる演算器ということでセキュアでもノンセキュアなコードでも使えるHWは同一です。MicroPythonのコードはノンセキュア側で走っているようですが、このような場合セキュア側のアドレスで読み書き可能です。
今回実験のMicroPythonコード
今回は上記の過去回でも練習しているPOP操作を2コアでやってます。インターポレータの演算そのものは双方のコアから勝手に使えるので何も排他制御してませんが、その後の結果のprintが混ざると見ずらいので、そこに排他制御入れてます。実行するとTask Aは102から始まる公差2の等差数列を、Task Bは3から始まる公差3の等差数列を出力します。ゆっくり出力するように両コアとも待ちを入れてます。これは各コアのインターポレータ0のレーン0について最も基本の操作であるPOP操作(アキュムレータから読み出した値にベースを足してアキュムレータに書き戻す)を適用した結果です。
コードが以下に。
import time, machine, _thread
from micropython import const
SIO_BASE = const(0xd0000000)
SIO_NONSEC_BASE = const(0xd0020000)
INTERP0_ACCUM0 = const(0x080)
INTERP0_BASE0 = const(0x088)
INTERP0_POP_LANE0 = const(0x094)
INTERP0_CTRL_LANE0 = const(0x0ac)
def taskA():
global lock
cnt = 0
temp = machine.mem32[SIO_BASE + INTERP0_CTRL_LANE0]
machine.mem32[SIO_BASE + INTERP0_CTRL_LANE0] = temp | 0x00040000
machine.mem32[SIO_BASE + INTERP0_ACCUM0] = 100
machine.mem32[SIO_BASE + INTERP0_BASE0] = 2
while cnt < 4:
temp = machine.mem32[SIO_BASE + INTERP0_POP_LANE0]
lockP = lock.acquire(1, -1) #wait lock forever
if not lockP:
print("Task A can not get the lock.")
return
print("Task A POP: {0}".format(temp))
lock.release()
time.sleep(0.5)
cnt += 1
_thread.exit()
def taskB():
global lock
cnt = 0
temp = machine.mem32[SIO_BASE + INTERP0_CTRL_LANE0]
machine.mem32[SIO_BASE + INTERP0_CTRL_LANE0] = temp | 0x00040000
machine.mem32[SIO_BASE + INTERP0_ACCUM0] = 0
machine.mem32[SIO_BASE + INTERP0_BASE0] = 3
while cnt < 7:
temp = machine.mem32[SIO_BASE + INTERP0_POP_LANE0]
lockP = lock.acquire(1, -1) #wait lock forever
if not lockP:
print("Task B can not get the lock.")
return
print("Task B POP: {0}".format(temp))
lock.release()
time.sleep(0.5)
cnt += 1
def main():
global lock
lock = _thread.allocate_lock()
print("Interpolator POP test:")
_thread.start_new_thread(taskA, ())
taskB()
if __name__ == "__main__":
main()
実行結果
結果が以下に。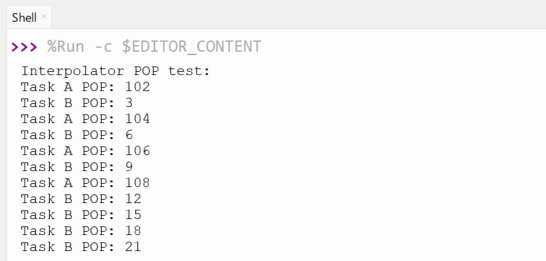
基本操作は出来たみたい。