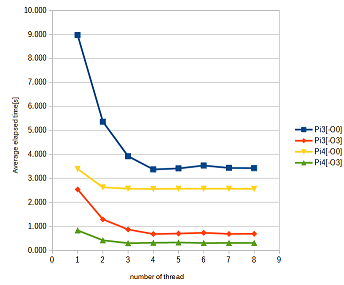
前回は、スレッド数に反比例して処理時間が短くなるサンプルプログラムに、コンパイラの最適化オプション効かせたら、マルチスレッドが効かなくなったのを目にしました。今回は、サンプルに「手を入れて」「スレッド化の効果あり」に無理やり変更の上、実行環境をラズパイ3からラズパイ4へ変えてみます。CPUの馬力が違うとまた違う。一筋縄ではいきまへん。
※ソフトな忘却力 投稿順 index はこちら
(実験に使用したソース全文は末尾に)
さて前回の結果のおさらいに同じグラフをまず掲げておきます。横軸がプログラム実行につかったスレッド数、縦軸は実行時間(経過時間)[s]です。
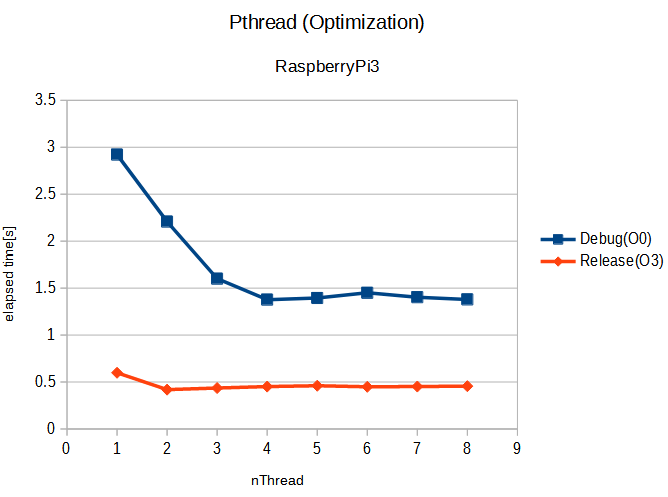 紺色は、最適化せず -O0 で、オレンジは、最適化あり -O3 です。コンパイラはgcc 8.3.0 を使用。最適化しないときは、スレッド数に反比例して実行時間が短くなり、スレッド数4から頭打ちとなるように見えました。ラズパイ3は4コア機であることと整合的。目論見通りであります。
紺色は、最適化せず -O0 で、オレンジは、最適化あり -O3 です。コンパイラはgcc 8.3.0 を使用。最適化しないときは、スレッド数に反比例して実行時間が短くなり、スレッド数4から頭打ちとなるように見えました。ラズパイ3は4コア機であることと整合的。目論見通りであります。
ところが、オレンジ色の最適化ありとすると、1スレッドより2スレッドは微妙に速くなるものの、以下スレッド数増やしても効きませぬ。これに対して考えられるのはハードウエア・リソースの制約、ぶっちゃけ、バスかメモリがもういっぱいいっぱいで、スレッド増やしてもそれを受け入れるだけの余力がない、という状態です。先週はそこで止まっていましたが、今週はここに手を入れてみました。
バス負荷そのまま、「計算負荷」を増やす
前回は、データを2つ読んで、掛け算して、データを一つ書いての繰り返しでした。同じデータは2度使わないのでデータにキャッシュは効きませぬ。バスアクセス3回に対して掛け算1回という割合だと、CPUの皆さんの間でバスの争奪戦が起きるばかりで、CPUの数の割に仕事が進まない、と。まあ、実際に必要な処理が軽い計算であれば致し方ない状況ですが、今回はあくまでテスト用のプログラムなので、計算負荷を増してCPUの皆さんが中々バスに手が伸びない状況を作ってみました。ゴージャスに浮動小数点割り算を2回も使って「時間を無駄に」使っています。
Thread化している部分のコードは以下に(全文は末尾に)
void* testThreadFunc(void* p) {
int* ptr = (int*)p;
int blkSIZE = (NSET / currentNT) * nData;
int startIDX = (*ptr) * blkSIZE;
int endIDX = ((*ptr) + 1) * blkSIZE;
float temp1, temp2, temp3;
*ptr = 0; //counter
for (int j=0; j < nLoop; j++) {
for (int idx=startIDX; idx < endIDX; idx++) {
temp1 = dataArray1[idx] - dataArray2[idx];
temp2 = dataArray1[idx] + dataArray2[idx];
if (temp2 > temp1) {
temp1 = temp1 / temp2;
} else {
temp1 = temp2 / temp1;
}
if (dataArray1[idx] > dataArray2[idx]) {
temp3 = dataArray1[idx] * temp1;
} else {
temp3 = dataArray2[idx] * temp2;
}
resultArray[idx] = temp3 / temp2;
*ptr += 1; //counter
}
}
}
ラズパイ3上で目論見通りの挙動になったか確認
早速、Raspberry Pi 3 Model B+ 上で、最適化オプションをつけてもスレッドが増えた効果が見られるようになったのか確かめてみました。
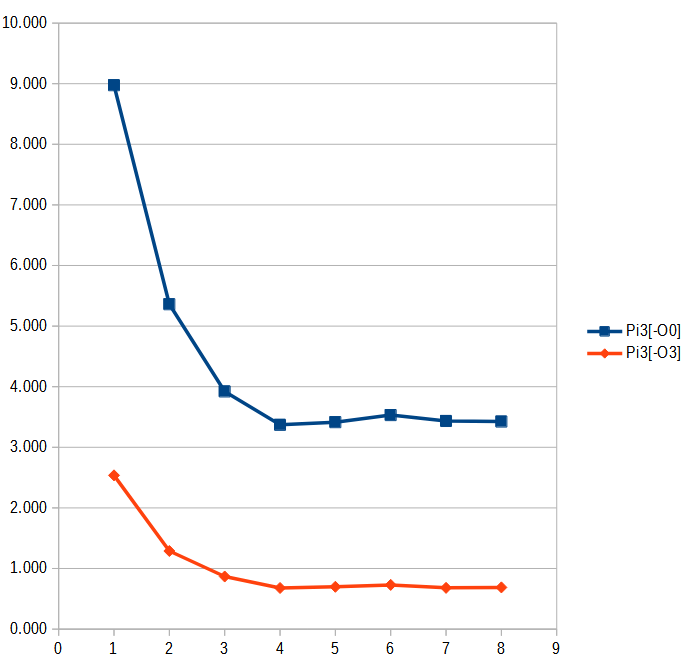
負荷が重くなったので、前回よりも3倍くらい時間がかかるようになりましたが、目論見通りです。CPUの皆さんが忙しく計算している分、バスの取り合いの頻度が減って、ちゃんとスレッド数が増えると、経過時間が短くなっています。
良い感じじゃね。余勢を駆って同じソースをラズパイ4へもっていき、ビルドして走らせてみました。ラズパイ4での効果は如何に?
Raspberry Pi 3 Model B+ と Raspberry Pi 4 Model B
どちらも同じOS (Raspberry Pi OS <32bit>、Linuxバージョン5.10.63で同じ)、同じコンパイラ(gcc 8.3.0)で走っているので、主となる差はハードウエア(CPU)の差だと思われます。以下にその違いをまとめておきます。
| Pi 3 Model B+ | Pi 4 Model B | |
|---|---|---|
| SoC | BCM2837B0 | BCM2711 |
| CORE | Cortex-A53 | Cortex-A72 |
| nCORE | 4 | 4 |
| CLOCK | 1.4GHz | 1.5GHz |
ぱっと見、似たような感じなのですが、実際に走らせるとA53とA72はダンチです。
ラズパイ4とラズパイ3での実行結果
アイキャッチ画像に掲げたものと同じグラフですが、見やすい拡大版を以下に。
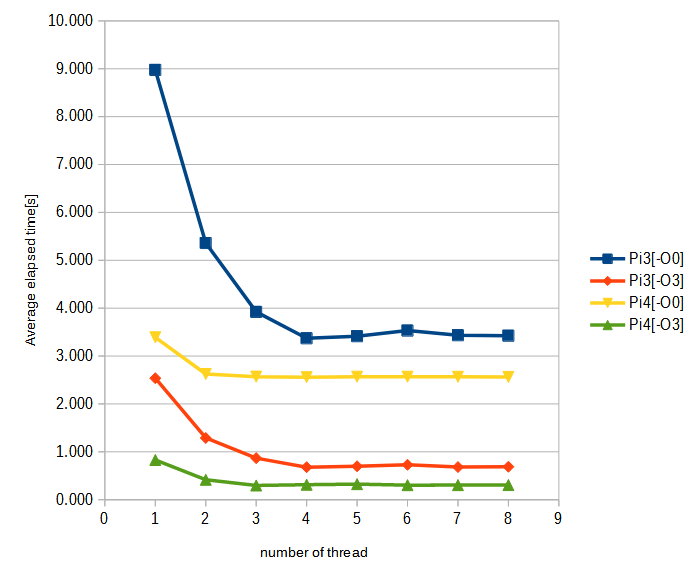
1スレッドのところを見ると、A72とA53の差がデカイことが分かります。ここで微妙なのは、ラズパイ4の場合、最適化済のコードはスレッド数が増えると3スレッドまでは速度向上する傾向があるのに、非最適化のコードは2スレッドでサチってしまうところです。同じコードを走らせているのに、ラズパイ3と4で挙動が違う部分かと思います。また、ラズパイ4の場合、スレッド化の効果を引き出すには、先ほどの計算負荷増でも足らず、もっと計算量を増やさないといけない感じがします。
とはいえ、スレッド化の効果よりは、最適化のON/OFFの方が「効きが良い」感じもします。当然のコンパイラ最適化した後に、さらに性能を絞りだすにはthread化という感じですかね。まあ、いずれにせよ、ただ最適化すればとか、スレッドを増やせば、というような感じでもない、と。当然すぎる結論ですが。
ソフトな忘却力(8) CMake、最適化オプションの置き場所。thread化の蹉跌? へ戻る
ソフトな忘却力(10) RPi4、Pthreadの実験をOpenMPで書き換えてみた へ進む
実験に使用したCソース全文
負荷部分以外は前回と同じ。
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <pthread.h>
#include <time.h>
#define MAX_THREAD (16)
#define NSET (2*3*2*5*7*2*3*11*13*2)
#define NDATAMAX (2048)
int idxStore[MAX_THREAD];
float *dataArray1;
float *dataArray2;
float *resultArray;
int nThread = 1;
int nData = 1;
int currentNT = 1;
int nLoop = 100;
int seed = 123;
void* testThreadFunc(void* p) {
int* ptr = (int*)p;
int blkSIZE = (NSET / currentNT) * nData;
int startIDX = (*ptr) * blkSIZE;
int endIDX = ((*ptr) + 1) * blkSIZE;
float temp1, temp2, temp3;
*ptr = 0; //counter
for (int j=0; j < nLoop; j++) {
for (int idx=startIDX; idx < endIDX; idx++) {
temp1 = dataArray1[idx] - dataArray2[idx];
temp2 = dataArray1[idx] + dataArray2[idx];
if (temp2 > temp1) {
temp1 = temp1 / temp2;
} else {
temp1 = temp2 / temp1;
}
if (dataArray1[idx] > dataArray2[idx]) {
temp3 = dataArray1[idx] * temp1;
} else {
temp3 = dataArray2[idx] * temp2;
}
resultArray[idx] = temp3 / temp2;
*ptr += 1; //counter
}
}
}
int getParam(char* oa) {
int temp;
errno = 0;
temp = strtol(oa, (char **)NULL, 10);
if (errno == 0) {
return temp;
} else {
perror("ERROR: nThread");
exit(EXIT_FAILURE);
}
}
void setupArrays() {
int numberOfData = nThread * NSET * nData;
dataArray1= (float*)malloc(numberOfData * sizeof(float));
if (dataArray1 == NULL) {
perror("ERROR: Allocate dataArray1");
exit(EXIT_FAILURE);
}
dataArray2= (float*)malloc(numberOfData * sizeof(float));
if (dataArray1 == NULL) {
perror("ERROR: Allocate dataArray2");
exit(EXIT_FAILURE);
}
resultArray= (float*)malloc(numberOfData * sizeof(float));
if (dataArray1 == NULL) {
perror("ERROR: Allocate resultArray");
exit(EXIT_FAILURE);
}
srand(seed); // Same seed will give same sequence.
for (int i=0; i < numberOfData; i++) {
dataArray1[i] = (float)rand() / 10000. + 0.5f;
dataArray2[i] = (float)rand() / 10000. + 0.7f;
}
}
void freeArrays() {
free(dataArray1);
free(dataArray2);
free(resultArray);
}
float getTimeFloat() {
struct timespec temp;
clock_gettime(CLOCK_MONOTONIC, &temp);
return ( (float)temp.tv_sec + (float)(temp.tv_nsec)/1e9 );
}
float testDriver(int nT) {
pthread_t threadA[MAX_THREAD];
float startT, endT;
int skipNUM = nT;
currentNT = nT;
startT = getTimeFloat();
for (int numT=0; numT < nT; numT++) {
idxStore[numT] = numT;
if (pthread_create(&threadA[numT], NULL, testThreadFunc, (void*)&idxStore[numT])) {
perror("ERROR: pthread_create\n");
skipNUM = numT;
}
}
for (int numT=0; numT < skipNUM; numT++) {
if (pthread_join(threadA[numT], NULL)) {
perror("ERROR: pthread_join\n");
}
}
endT = getTimeFloat();
int totNUM = 0;
for (int numT=0; numT < nT; numT++) {
totNUM += idxStore[numT];
}
printf(",%d",totNUM);
return endT - startT;
}
int main(int argc, char *argv[]) {
int opt;
int nSleep = 2;
int flagA = 0;
int nTrial = 3;
float result;
while((opt = getopt(argc, argv, "aT:N:R:L:S:")) != -1) {
switch (opt) {
case 'a':
flagA = 1;
break;
case 'T':
nThread = getParam(optarg);
if (nThread > MAX_THREAD) {
perror("ERROR: Too much thread.");
exit(EXIT_FAILURE);
}
break;
case 'N':
nData = getParam(optarg);
if (nData > NDATAMAX) {
perror("ERROR: Data, over the limit.");
exit(EXIT_FAILURE);
}
break;
case 'R':
nTrial = getParam(optarg);
break;
case 'L':
nLoop = getParam(optarg);
break;
case 'S':
seed = getParam(optarg);
break;
default:
fprintf(stderr, "Usage: %s [-a][-T nThread][-N nData][-R nTrial][-L nLoop][-S seed]\n", argv[0]);
exit(EXIT_FAILURE);
}
}
printf("Cpthread test runner: nThread=%d nData=%d, nTrial=%d, nLoop=%d\n", nThread, nData, nTrial, nLoop);
setupArrays();
printf("Start TEST\n");
for (int nT=1; nT <= nThread; nT++) {
printf("%d", nT);
for (int idx=0; idx < nTrial; idx++) {
result = testDriver(nT);
printf(",%12.6e",result);
}
printf("\n");
}
printf("End of TEST.\n");
sleep(nSleep);
if (flagA) {
for (int i=0; i< nData; i++) {
printf("%d: %f\n",i, resultArray[i]);
}
}
freeArrays();
printf("Eno of Execution.\n");
exit(EXIT_SUCCESS);
}