前回は「何もしない」けれど「書けることが多い」commentノードでした。今回は、設定できることは少ない割に奥が深そうな(あまり沼にハマりたくない)smoothノードです。苦手の統計やらデジタル信号処理(もどきですが)も登場。まあ、使ってみている内に慣れる?慣れない?
※「ブロックを積みながら」投稿順 index はこちら
※2022年3月6日追記:ローパス、ハイパスフィルタの特性についての検討を別記事に掲載しました。
前半戦は統計、といっても簡単だけれど
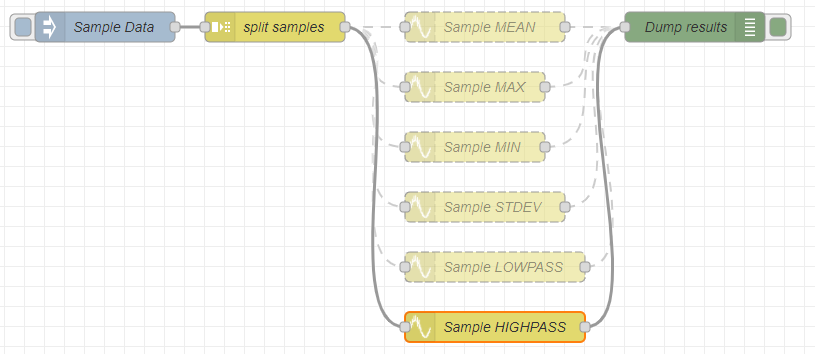
smoothノードには6機能ありました。そのうち4機能は「よくやる統計?」みたいなので前半戦としてまとめました。そのサンプルテストフローが以下に。
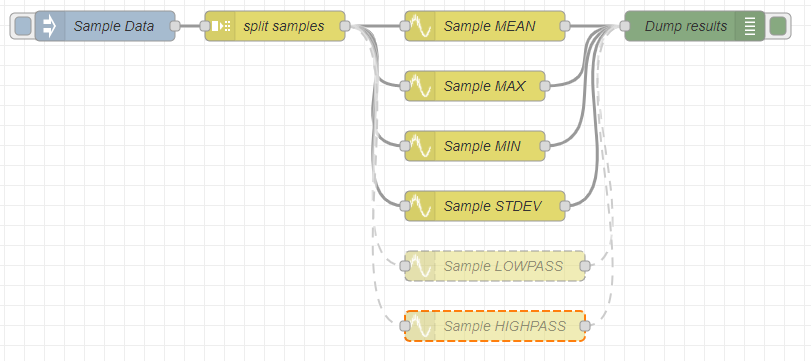
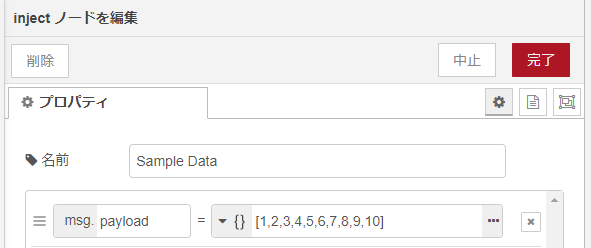
左端のinjectノードで、処理対象のサンプルデータを流しだします。ここでは、arrayを1個、中身は「とりあえず」の1から10までの等差数列?であります。
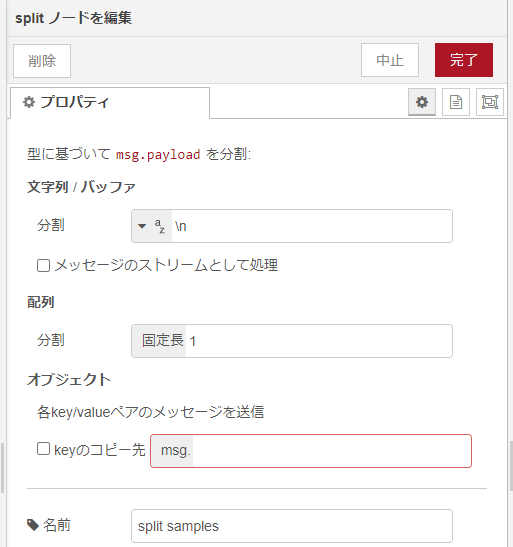
injectノードから流しだしたarrayをつづくsplitノードで分割します。分割方法はデフォルトのままです。配列(array)は、固定長、1要素毎に分割っと。設定したのは「名前」だけのsplitノードが以下に。
smoothノードの主要な設定は、Actionというプルダウンノードです。そこには6種類の選択肢があります。
-
- maximum (最大値)
- minimum(最小値)
- mean(平均値)
- standard deviation (標準偏差)
- low pass filter
- high pass filter
前半戦では1~4を、後半戦では5と6をやってみます。
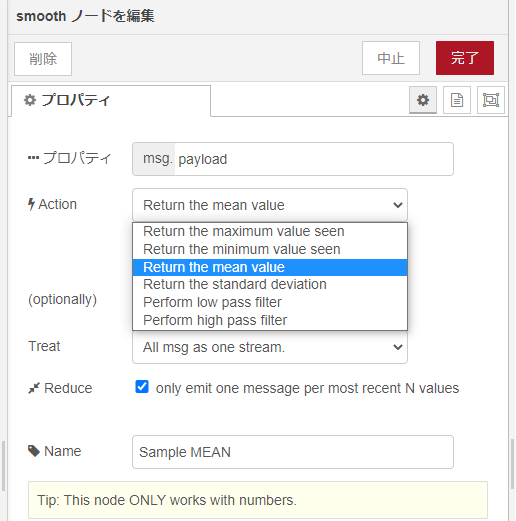
なお、青のチェックマークがついている「Reduce」という項目にチェックを入れるか入れないかで見た目の挙動が大きくかわります。Reduceにチェックを入れないと入力msgの個数だけの出力が出てきますが、チェックを入れるとN個(Nは何個のmsgに載ってきたデータの平均をとるかなど決める数)処理して1個のmsgを出力します。
前半戦では10個のデータを処理したところで、最大、最小、平均、標準偏差を求めることにしてチェックを入れてあります。
後半戦はフィルタなのでチェックを外して、データが来るたびにその時点の値を次々に出力するようにしてあります。
平均、最大、最小、標準偏差
mean(平均)を指定したときの出力 msg が以下です。payload: 5.5です。1から10までの数の平均値。5.5、あってますね。なお、splitノードでarrayを分割しているので、入力msgには、partsプロパティが付いており、partsの中を見るとindex: 9 と10個目のデータが入力されたことで、このmsg が出力されたことが分かります。
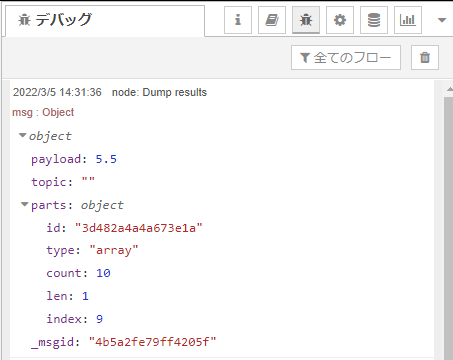
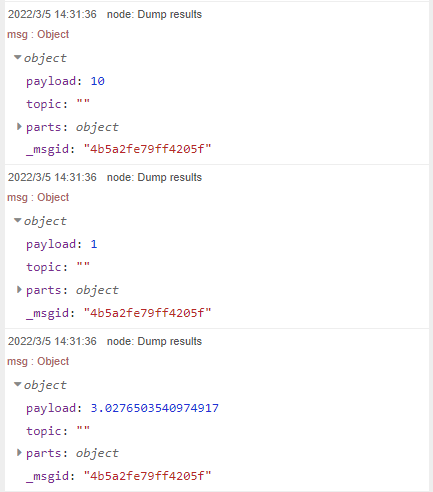
以下は順に、最大、最小、標準偏差です。なお、標準偏差は、N-1で割る方の標準偏差のようです。EXCELでSTDEV.S関数で求める方です。言葉が紛らわしいのでEXCELの関数名の方が混乱が無いかと。
後半戦はフィルタ
フィルタの方は、データ10個を流し込めば10個出てきます。フィルタの特性を左右するパラメータはNのみです。以下ではNは5に設定してみました。
同時にローパス、ハイパス動かすとデータを確認するのが面倒なので片方づつ味わっていきたいと思います。まずは「ローパス」から
Node-REDのsmoothノードのHELPドキュメントを参照したのですが、「ほんわか」した説明のみで、デジタルフィルタの差分方程式、ブロックダイアグラム、伝達関数などの特性がハッキリ決まる記述は見当たりませんでした。しかたが無いので茫漠と出力データを眺めていると、以下のような差分方程式ではないか、と推定できました。多分、以下でローパスになる筈。
-
- y[i] = α * x[i] + y[i-1]*(1-α)
- α=1/N
本稿ではなく、別記事で「デジタルフィルタ」としての特性がどんなものだか考えてみたいと思っています(ちゃんとやれよ、自分。)
本稿では結果が出てくるところまで。以下は最初の5個です。
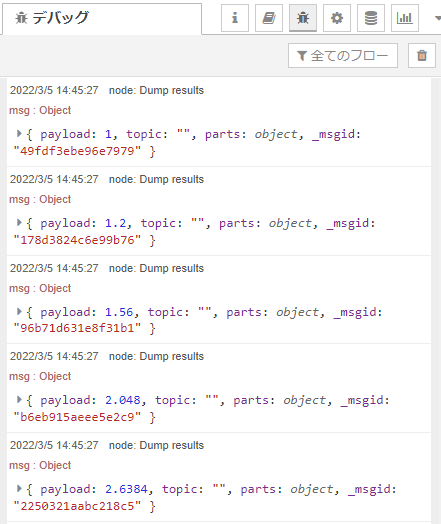
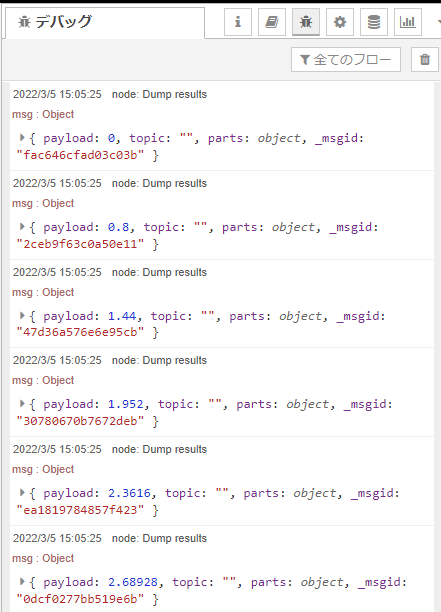
続いて「ハイパス」です。
やはり、データから推定した差分方程式とその特性については別記事で取り扱いたいと思います。
データの最初の5個はこんな感じ。
なんとなく smoothノードの動作は分かった感じ。でもフィルタのところ、後でちゃんと調べろよ、自分。
※2022年3月6日追記:ローパス、ハイパスフィルタの特性についての検討を別記事に掲載しました。