A64のロード命令をさらっています。元より組み合わせを網羅しようなどとは考えておらず「ありがちな」例を「通り一遍」なでるだけのつもりなのですが、Armは命令数が多いっす。ロードだけでもどんだけ?今回は、前回積み残しのアドレシングモードを使ってみます。POST/PRE-indexみたいな「複雑な」奴らも登場。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
今回実験するアドレシングモード
前回積み残しの以下のアドレシングモードを使用してみます。
-
- ベースレジスタ+インデックスレジスタ
- ポストインデックス
- プリインデックス
- リテラル
1のベース+インデックスで素のまま足し合わせたのでは、どちらがインデックスかイマイチなので、ことさらにインデックス側をシフトして足し合わせてみることにします。
2と3のポスト/プリ・インデックスは、メモリブロックのある範囲を「舐める」ときなどに有効です。しかし実際にレジスタに格納されたアドレスが変化していく様子はそのままでは見えないので、これまたことさらにポスト/プリ・インデックスした後のアドレスレジスタの値をわざわざ読み出して確認してます。
4のリテラルは、コード領域(.text)内にラベルを貼ってデータを置くものです。お作法としてアライメントしとります。
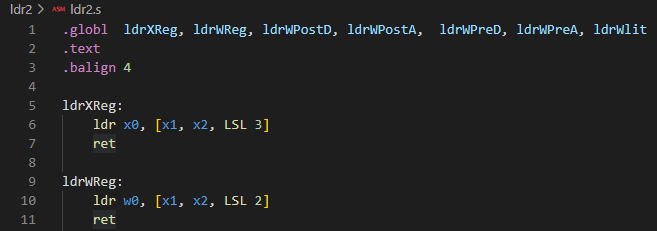
実験に使ったアセンブリ言語ソース
例によって手抜き(関数プロローグもエピローグもない)な、ほぼ1命令1関数スタイルです。ポスト/プリ・インデックスに関しては、データロード確認用とアドレスの変化確認用で2関数つかってます。
どれもデスティネーションはXレジスタ(64ビット)とWレジスタ(32ビット)のどちらもとれるのですが、組み合わせが多くなって疲れるという理由?で一部Wしかやってません。
.globl ldrXReg, ldrWReg, ldrWPostD, ldrWPostA, ldrWPreD, ldrWPreA, ldrWlit
.text
.balign 4
ldrXReg:
ldr x0, [x1, x2, LSL 3]
ret
ldrWReg:
ldr w0, [x1, x2, LSL 2]
ret
ldrWPostD:
ldr w0, [x1], #4
ret
ldrWPostA:
ldr w0, [X1], #4
mov x0, x1
ret
ldrWPreD:
ldr w0, [x1, #4]!
ret
ldrWPreA:
ldr w0, [x1, #4]!
mov x0, x1
ret
ldrWlit:
ldr w0, dat_target_1
ret
.balign 4
dat_target_1:
.long 0x12345678
実験に使用したC言語ソース
上記のアセンブリ言語関数を呼び出すテスト用のCソースが以下に。
#include <stdio.h>
#include <stdint.h>
uint32_t tgtW[4];
uint64_t tgtX[4];
extern uint64_t ldrXReg(uint64_t, uint64_t *, uint64_t);
extern uint32_t ldrWReg(uint64_t, uint32_t *, uint64_t);
extern uint32_t ldrWPostD(uint32_t, uint32_t *);
extern uint64_t ldrWPostA(uint64_t, uint32_t *);
extern uint32_t ldrWPreD(uint32_t, uint32_t *);
extern uint64_t ldrWPreA(uint64_t, uint32_t *);
extern uint32_t ldrWlit(uint32_t);
void initTGT() {
tgtW[0] = 0x00234567;
tgtW[1] = 0x11234567;
tgtW[2] = 0x22234567;
tgtW[3] = 0x33234567;
tgtX[0] = 0x44234567a5a5a5a5;
tgtX[1] = 0x55234567a5a5a5a5;
tgtX[2] = 0x66234567a5a5a5a5;
tgtX[3] = 0x77234567a5a5a5a5;
}
int main(void) {
uint32_t uresult;
uint64_t uresultX;
initTGT();
uresultX=ldrXReg(0, tgtX, 1);
printf ("ldrXReg : 0x%016lx\n", uresultX);
uresult =ldrWReg(0, tgtW, 1);
printf ("ldrWReg : 0x%08x\n", uresult);
uresult =ldrWPostD(0, tgtW);
printf ("ldrWPostD: 0x%08x\n", uresult);
uresultX =ldrWPostA(0, tgtW);
printf ("tgtW : 0x%016lx\n", (uint64_t)tgtW);
printf ("ldrWPostA: 0x%016lx\n", uresultX);
uresult =ldrWPreD(0, tgtW);
printf ("ldrWPreD : 0x%08x\n", uresult);
uresultX =ldrWPreA(0, tgtW);
printf ("ldrWPreA : 0x%016lx\n", uresultX);
uresult =ldrWlit(0);
printf ("ldrWlit : 0x%08x\n", uresult);
return 0;
}
ビルドして実行
以下はビルドして実行したところの画面キャプチャです。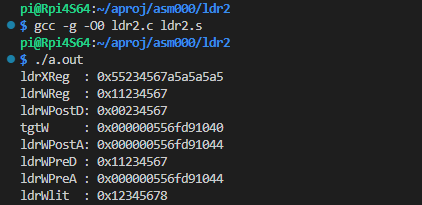
上の2つはベース+インデックス・アドレシングで、いずれもインデックスレジスタには「1」が入っているけれども、アドレスは左シフトの効用でx8とx4されてます。結果としてそれぞれの配列の「1」番目(0はじまり)の要素がロードされております。
ldrWPostDでは、tgtW配列の最初の要素をロードしています。ロード後、アドレスレジスタの内容は ldrWPostAにあるように tgtW配列の先頭番地から+4されていることがわかります(副作用ぞなもし。)ポストインデックス。
同様にldrWPreDでは、tgtW配列の先頭番地のアドレスを与えたにもかかわらず「1」の要素をロードしています。ロード前にアドレスを+4してからロードしておりますな。ldrWPreAにあるようにアドレスが変化してます(副作用。)プリインデックス。
最後のldrWlitは .text セグメント内の定数?(今回実験のラズパイ4では.textはFlashではなくDRAMに置かれているので書き換えも可能だけれども)がロードされております。
予定通りに動いているみたい。