まだSIMDのMOV命令は残っているのですが、今回はさっさと先に進みます。言ってもしょうがないけどA64の命令多すぎ。特にSIMD命令多すぎ。今回実験してみるのはSIMDのbit操作関係の命令群です。ビット操作なので要素は記述の形式的で、実際はSIMDレジスタの全ビット幅の各ビットに対して作用するもの。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
※積み残したMOV命令は、SIMDレジスタ上のベクトル要素からSIMDレジスタ上のスカラーへの転送です。A64の場合、SIMDレジスタはスカラーの浮動小数点レジスタを兼ねているので、当然必要な操作なんだけれど地味。いいのか?
SIMD(ベクトル)レジスタのビット操作命令群
今回練習してみる命令群は以下です。ベクトル命令なので、オペランドにベクトルレジスタをとりますが、許される要素は8B(バイト。SIMDレジスタのビット幅は64ビット)か16B(バイト。SIMDレジスタのビット幅は128ビット)です。Bのアセンブラ記述は操作対象のSIMDレジスタのビット幅を決めるためのもので、実際の演算はビット単位となります。
どの命令もソース2つ、デスティネーション1つの3オペランド命令です。3オペランドの対応位置の各ビット間の演算を図にしてみました。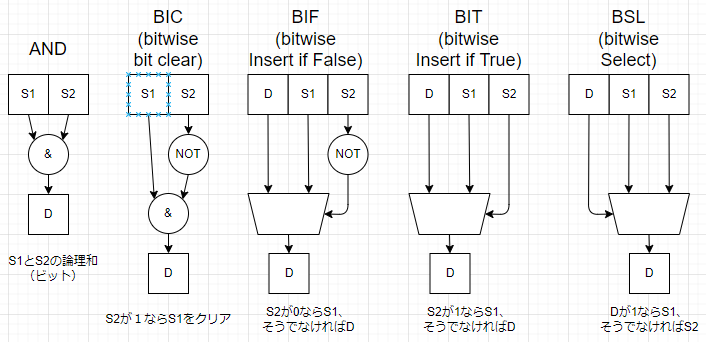
台形のハコはマルチプレクサです。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。全て128ビット幅としています。
.globl andv, bicv, bifv, bitv, bslv
.text
.balign 4
andv:
ld1 {v0.16B, v1.16B, v2.16B}, [x0], #48
and v0.16B, v1.16B, v2.16B
st1 {v0.16B}, [x0]
ret
bicv:
ld1 {v0.16B, v1.16B, v2.16B}, [x0], #48
bic v0.16B, v1.16B, v2.16B
st1 {v0.16B}, [x0]
ret
bifv:
ld1 {v0.16B, v1.16B, v2.16B}, [x0], #48
bif v0.16B, v1.16B, v2.16B
st1 {v0.16B}, [x0]
ret
bitv:
ld1 {v0.16B, v1.16B, v2.16B}, [x0], #48
bit v0.16B, v1.16B, v2.16B
st1 {v0.16B}, [x0]
ret
bslv:
ld1 {v0.16B, v1.16B, v2.16B}, [x0], #48
bsl v0.16B, v1.16B, v2.16B
st1 {v0.16B}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。ビット単位で結果の総当たりを1回の操作で求めるならば1バイトあれば足りるのですが、ベクトル命令なので幅広のままで処理してます。無意味に冗長だけどベクトルだということだけは身に染みる?
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (16)
uint32_t TargetMEM[MAXMEM];
extern void andv(uint32_t *);
extern void bicv(uint32_t *);
extern void bifv(uint32_t *);
extern void bitv(uint32_t *);
extern void bslv(uint32_t *);
void initTGT(uint32_t* c) {
for (int i=0; i < 4; i++) {
TargetMEM[i*4+0] = c[i];
TargetMEM[i*4+1] = c[i];
TargetMEM[i*4+2] = c[i];
TargetMEM[i*4+3] = c[i];
}
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < MAXMEM; i++) {
printf("%2d: 0x%08x\n", i, TargetMEM[i]);
}
}
int main(void) {
uint32_t c[4];
c[0]=0x00000000;
c[1]=0x0F0F0F0F;
c[2]=0xA5A5A5A5;
c[3]=0xFFFFFFFF;
initTGT(c);
dumpTGT("Before and vector");
andv(TargetMEM);
dumpTGT("After and vector");
c[0]=0x00000000;
c[1]=0x0F0F0F0F;
c[2]=0xA5A5A5A5;
c[3]=0xFFFFFFFF;
initTGT(c);
dumpTGT("Before bic vector");
bicv(TargetMEM);
dumpTGT("After bic vector");
c[0]=0x0000FFFF;
c[1]=0x0F0F0F0F;
c[2]=0xA5A5A5A5;
c[3]=0xFFFFFFFF;
initTGT(c);
dumpTGT("Before bif vector");
bifv(TargetMEM);
dumpTGT("After bif vector");
c[0]=0x0000FFFF;
c[1]=0x0F0F0F0F;
c[2]=0xA5A5A5A5;
c[3]=0xFFFFFFFF;
initTGT(c);
dumpTGT("Before bit vector");
bitv(TargetMEM);
dumpTGT("After bit vector");
c[0]=0x0000FFFF;
c[1]=0x0F0F0F0F;
c[2]=0xA5A5A5A5;
c[3]=0xFFFFFFFF;
initTGT(c);
dumpTGT("Before bsl vector");
bslv(TargetMEM);
dumpTGT("After bsl vector");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 bit.c bit.s $ ./a.out
標準出力に「ダラダラ」現れる結果を折りたたんで、見やすいように関係個所を枠で囲ってみました。
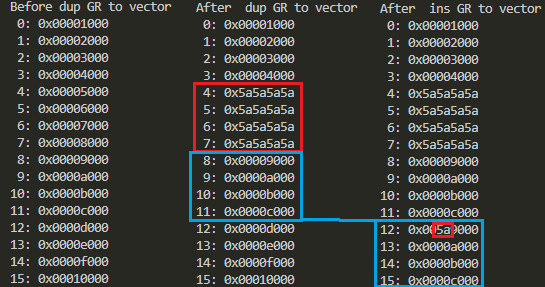{kind=link}
まずは、ANDとBIC(bitwise bit clear)。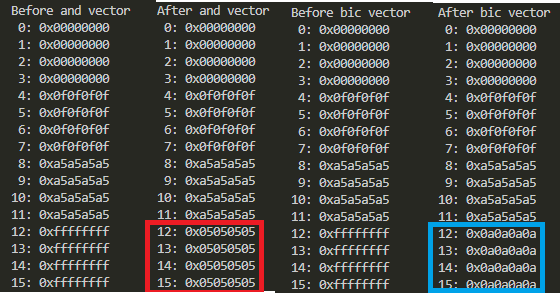
お次は、BIF(bitwise bit if false)とBIT(bitwise bit if true)。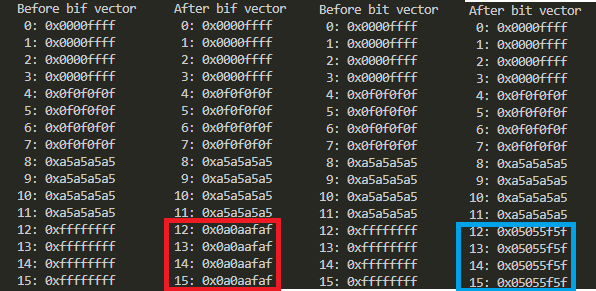
最後にBSL。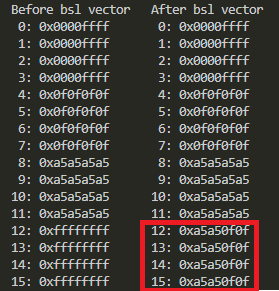
予定通りの処理が出来ているみたいだけれども。単純なビット演算だけれどSIMDレジスタの全幅になるだけで目が回る気がするよ、あたしゃ。