前回は演算後のHavingで桁あふれに備える系統の命令を実験しました。今回はサチュレーション演算によって桁あふれしない範囲内に結果をとどめるための系統の命令を使ってみます。SQADD、UQSUBなどと命令ニーモニックの中にQを含む命令共です。しかし命令充実(A64の命令数大すぎ。)とても1回じゃ練習しきれませぬ。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
SIMDのサチュレーション演算
演算結果が既定のビット表現を「上回る」ときに上限値、「下回る」ときに下限値に抑え込んでしまうサチュレーション演算は、デジタル信号処理などでお馴染みの計算デス。大きくなり過ぎたらいくらでも一緒だと。知らんけど。
さて、A64のSIMD演算命令の中でもサチュレーション演算は幅を利かせている一族です。ニーモニックを拾ってみたところで以下のようです。
| 操作 | 符号付 | 符号無 |
|---|---|---|
| サチュレーション加算 | SQADD | UQADD |
| サチュレーション減算 | SQSUB | UQSUB |
| サチュレーション左シフト | SQSHL | UQSHL |
| サチュレーション左シフト丸め | SQRSHL | UQRSHL |
| サチュレーション倍幅乗算ハイ | SQDMULH | — |
| サチュレーション倍幅積和丸めハイ | SQRDMLAH | — |
| サチュレーション倍幅積差丸めハイ | SQRDMLSH | — |
| サチュレーション倍幅乗算丸めハイ | SQRDMULH | — |
上記だけでも数は多いし、メンドクセーのでありますが、上記に含まれていないのがサチュレーション「じゃない」方の演算です。こいつも含めて比べてみないと腑に落ちない(最近じゃ腹落ちとか言うの?老人は知らんよ。)
3種のADD、3種のSUB
さてサチュレーションの練習の初回は、加減算からであります。肝心のサチュレーションの有無、加算と減算、符号付と符号なしで実験対象の命令ニーモニックは以下の6種となります。
| 操作 | 符号付 | 符号無 |
|---|---|---|
| サチュレーション加算 | SQADD | UQADD |
| サチュレーション減算 | SQSUB | UQSUB |
| 加算 | ADD | ADD |
| 減算 | SUB | SUB |
サチュレーションが無ければシンプルなADD、SUBだけで良かったのに。。。
サチュレーション演算は整数エレメントを引数に取りますが、A64の場合、ビット幅はバイト、ハーフワード、ワード、ダブルワードの4つ存在します。その上、SIMDレジスタ幅全幅128ビットと半幅64ビットの使い分けも可能なのでオペランドは例によっていろいろです。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。例によってメンドクセーので、バイト幅エレメントの半幅レジスタのみで実習をしてみます。
.globl sqadd8V, uqadd8V, sqsub8V, uqsub8V, add8V, sub8V
.text
.balign 4
sqadd8V:
ld1 {v1.8B, v2.8B}, [x0], #16
sqadd v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
uqadd8V:
ld1 {v1.8B, v2.8B}, [x0], #16
uqadd v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
sqsub8V:
ld1 {v1.8B, v2.8B}, [x0], #16
sqsub v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
uqsub8V:
ld1 {v1.8B, v2.8B}, [x0], #16
uqsub v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
add8V:
ld1 {v1.8B, v2.8B}, [x0], #16
add v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
sub8V:
ld1 {v1.8B, v2.8B}, [x0], #16
sub v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。これまたいつもの通りの手抜きですが、各エレメントの計算が分かり易いように要素毎に出力を1行にまとめてみました。また本来 sが頭についているニーモニックは符合付なのですが、C言語レベルでは全てuint8_t引数に対して操作させてます(どうせアセンブラにはCのレベルでどう見えているかなんざ関係ねえっす。恐れ入り谷の鬼子母神。)
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (24)
uint8_t TargetMEM[MAXMEM];
extern void sqadd8V(uint8_t *);
extern void sqsub8V(uint8_t *);
extern void uqadd8V(uint8_t *);
extern void uqsub8V(uint8_t *);
extern void add8V(uint8_t *);
extern void sub8V(uint8_t *);
void initTGT() {
TargetMEM[0] =0x7E;
TargetMEM[1] =0x7F;
TargetMEM[2] =0x81;
TargetMEM[3] =0x80;
TargetMEM[4] =0x00;
TargetMEM[5] =0x01;
TargetMEM[6] =0xFE;
TargetMEM[7] =0xFF;
TargetMEM[8] =0x01;
TargetMEM[9] =0x01;
TargetMEM[10]=0x01;
TargetMEM[11]=0x01;
TargetMEM[12]=0x01;
TargetMEM[13]=0x01;
TargetMEM[14]=0x01;
TargetMEM[15]=0x01;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 8; i++) {
printf("%02d: 0x%02x opr 0x%02x -> 0x%02x \n", i, TargetMEM[i], TargetMEM[i+8], TargetMEM[i+16]);
}
}
int main(void) {
initTGT();
sqadd8V(TargetMEM);
dumpTGT("sqadd");
uqadd8V(TargetMEM);
dumpTGT("uqadd");
sqsub8V(TargetMEM);
dumpTGT("sqsub");
uqsub8V(TargetMEM);
dumpTGT("uqsub");
add8V(TargetMEM);
dumpTGT("add");
sub8V(TargetMEM);
dumpTGT("sub");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 sqadd.c sqadd.s $ ./a.out
標準出力に「ダラダラ」現れた結果そのままでは比べ難いので、addはadd、subはsubでまとめてみました。まずはadd系3種の結果が以下に。微妙に結果が違うのがお分かりかと。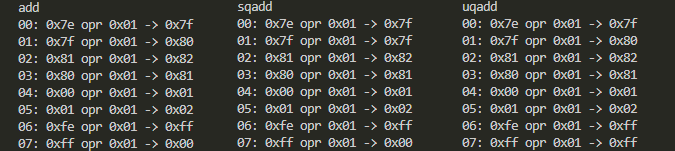
つづいてsub系3種です。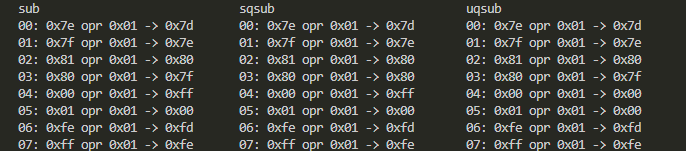
これまた微妙な違いよな。