今回練習するのは2命令、その一つのニーモニックはSQRDMULHです。マニュアルから命令の意味を引用すると「Signed saturating Rounding Doubling Multiply returning High half」です。これだけでメンドクセー奴だということだけは分かります。掛け算系の氷山の一角。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
今回練習のSIMDの掛け算
ただでさえ多いA64の命令の中、掛け算(乗算)と積和算こそはSIMD命令の主役といってよいでしょう。それだけに命令多数。しかし今回練習してみるのは2命令だけです。ソースとデスティネーションが等幅ビット数で、かつサチュレーションあり、そしてArm v8.0で練習できるもの、という条件の命令が2つだったということにすぎません。当初、以下の4命令を練習するつもりでおりました。
| 操作 | 符号付 | 符号無 |
|---|---|---|
| サチュレーション倍幅乗算ハイ | SQDMULH | — |
| サチュレーション倍幅積和丸めハイ | SQRDMLAH | — |
| サチュレーション倍幅積差丸めハイ | SQRDMLSH | — |
| サチュレーション倍幅乗算丸めハイ | SQRDMULH | — |
しかし、アセンブラが以下のように言いました。
Error: unknown mnemonic `sqdmulah’
しらべたら、サチュレーション倍幅でハイ側ハーフを取る「積和」と「積差」はARM v8.1からだったのね。練習台のARM v8.0では使えません。ラッキー、と喜びました。メンドクセー奴の数を減らせる。。。それで2個です。その特徴を列挙すれば、
-
- 整数乗算命令
- ソース、デスティネーションともハーフワード(H)もしくはワード(S)の2択
- 乗算した結果(ソースの倍幅のヒット数となる)の上位のハーフワードもしくはワードを返す
- 符合付のサチュレーション演算
さらに結果を丸めるか否かでSQDMULHとなるかSQRDMULHとなるかを選択。
実験に使ったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下です。思っていた数の半分に減ったのでルンルン。
.globl sqdmulh4V, sqrdmulh4V
.text
.balign 4
sqdmulh4V:
ld1 {v1.4H, v2.4H}, [x0], #16
sqdmulh v0.4H, v1.4H, v2.4H
st1 {v0.4H}, [x0]
ret
sqrdmulh4V:
ld1 {v1.4H, v2.4H}, [x0], #16
sqrdmulh v0.4H, v1.4H, v2.4H
st1 {v0.4H}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。今回はオペランドのビット幅もハーフワードかワードに限定です。お楽な選択で、SIMDレジスタは64ビット幅、エレメント幅は16ビット(ハーフワード)です。毎度のお断りです。Sが頭についているニーモニックは符合付なのですが、C言語レベルでは全てuint16_t引数に対して操作させてます(Cの型などアセンブラには、そんなの関係ね~。古いね。)
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (12)
uint16_t TargetMEM[MAXMEM];
extern void sqdmulh4V(uint16_t *);
extern void sqrdmulh4V(uint16_t *);
void initTGT16() {
TargetMEM[0] =0x7FFF;
TargetMEM[1] =0x7FFF;
TargetMEM[2] =0xFFFF;
TargetMEM[3] =0xFFFF;
TargetMEM[4] =0x0002;
TargetMEM[5] =0x8000;
TargetMEM[6] =0x0002;
TargetMEM[7] =0x8000;
}
void dumpTGT16(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 4; i++) {
printf("%02d: 0x%04x opr 0x%04x -> 0x%04x \n", i, TargetMEM[i], TargetMEM[i+4], TargetMEM[i+8]);
}
}
int main(void) {
initTGT16();
sqdmulh4V(TargetMEM);
dumpTGT16("sqdmulh");
sqrdmulh4V(TargetMEM);
dumpTGT16("sqrdmulh");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 sqdmulh.c sqdmulh.s $ ./a.out
結果が以下に。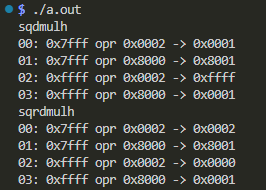
頭の中で掛け算して、サチューレーションさせ、上位ハーフワードを取り出すときに下のハーフワードの最上位をみて丸めてくだされや。多分、上の値になる筈。きっと。ホントか?