前回はSIMD「整数変換系」と勝手に称して表をまとめるだけで疲れてしまい、実習なしでした。今回は実習編。整数から浮動小数への変換命令の練習です。ニーモニック的には前回の巨大な表の末尾の2個だけです。浮動小数からの変換命令がそれだけ多いということだけれども、整数からの変換にも多少は凸凹あり。それほど単純ではありませぬ。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
整数から浮動小数へのSIMD変換命令
整数から浮動小数へのSIMD変換命令は、元の整数要素が符号付なのか符号無なのか指定しないとできません。それでニーモニックは2つ。
-
- SCVTF
- UCVTF
整数要素を符号付と解釈するSCVTFと符号無と解釈するUCVTFです。
ここでSIMD要素のビット幅は変りません。A64の命令セット的には以下の3つが定義されています。
-
- 16ビット整数から半精度浮動小数
- 32ビット整数から単精度浮動小数
- 64ビット整数から倍精度浮動小数
しかし毎度のお約束です。1番の半精度浮動小数は ARMv8p2 以降での導入なので、実習に使っているRaspberry Pi 4のArm Cortex-A72ではサポート無です。
お気づきと思いますが、同じビット幅であれば、整数型のフォーマットの方が、浮動小数型のフォーマットよりも表現できる整数は多いです。浮動小数は符号ビットと指数部のお陰で「ダイナミック・レンジ」は広いですが、仮数部のビット幅が狭いので同じビット幅の整数でも表現しきれない整数がありえます。当然「丸め」をどうするか指定が必要。ただSCVTFとUCVTFについてはFPCRレジスタの中の丸め制御ビットに従うようになってます。この後登場する浮動小数から整数への変換のように、FPCRに関わらず特定の丸めモードを使う命令などは存在しません。非対称(お陰で命令少なくて済んでます。)
また「使いやすい」(けれども命令多くなる)理由の一つが、固定小数点数のサポートがあることです。整数表現の勝手な位置に小数点があるとみなす形式ですな。デジタル信号処理でお馴染みの奴。そのため、第三のオペランドとして定数 #4 などと期すと、整数のLSB側のビット(例では4ビット)が小数点以下部分とみなして変換してくれます。便利ね。第三オペランドがなければ普通の整数として変換です。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。メンドイので32ビット整数から単精度浮動小数への変換命令のみとしています。変換のコマケー所がFPCRのモードビットに頼っているので、結果が一意になるようにFPCRへのアクセス命令も追加してあります。
.globl readfpcr, readfpsr, writefpcr, scvtf4V, scvtfx4V, ucvtf4V, ucvtfx4V
.text
.balign 4
readfpcr:
mrs x0, fpcr
ret
readfpsr:
mrs x0, fpsr
ret
writefpcr:
msr fpcr, x0
ret
scvtf4V:
ld1 {v0.4S, v1.4S}, [x0]
scvtf v0.4S, v1.4S
st1 {v0.4S}, [x0]
ret
scvtfx4V:
ld1 {v0.4S, v1.4S}, [x0]
scvtf v0.4S, v1.4S, #4
st1 {v0.4S}, [x0]
ret
ucvtf4V:
ld1 {v0.4S, v1.4S}, [x0]
ucvtf v0.4S, v1.4S
st1 {v0.4S}, [x0]
ret
ucvtfx4V:
ld1 {v0.4S, v1.4S}, [x0]
ucvtf v0.4S, v1.4S, #4
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。例によっていろいろな形式でアクセスするために union でテスト配列を定義してます。また、固定小数点数もまざるので、人間が解釈しやすいようにちょっと補助も加えてあります。年寄は暗算できないのよ。。。
#include <stdio.h>
#include <stdint.h>
#include <float.h>
#define MAXMEM (8)
typedef union {
float f;
uint32_t u32;
int32_t s32;
} un32;
un32 TargetMEM[MAXMEM];
extern uint32_t readfpcr(void);
extern uint32_t readfpsr(void);
extern void writefpcr(uint32_t);
extern void scvtf4V(un32 *);
extern void scvtfx4V(un32 *);
extern void ucvtf4V(un32 *);
extern void ucvtfx4V(un32 *);
void initTGT() {
TargetMEM[0].f = 0.0f;
TargetMEM[1].f = 0.0f;
TargetMEM[2].f = 0.0f;
TargetMEM[3].f = 0.0f;
TargetMEM[4].u32 = 0x21;
TargetMEM[5].u32 = 0x201;
TargetMEM[6].u32 = 0xFFFFFF1F;
TargetMEM[7].u32 = 0xFFFFFF10;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i<4; i++) {
printf("%02d: 0x%08x(%d) -(%s)-> %f\n", i, TargetMEM[i+4].u32, TargetMEM[i+4].s32, arg, TargetMEM[i].f);
}
}
int main(void) {
uint32_t temp = readfpcr();
writefpcr(temp | 0xC00000); //toward zero
initTGT();
scvtf4V(TargetMEM);
dumpTGT("scvtf");
printf("\n 0x%08x >>4 %d; 0x%08x >>4 %d;\n", 0x21, 0x2, 0x201, 0x20);
printf(" 0x%08x >>4 %d; 0x%08x >>4 %d;\n", 0xFFFFFF1F, 0xFFFFFFF1, 0xFFFFFF10, 0xFFFFFFF1);
initTGT();
scvtfx4V(TargetMEM);
dumpTGT("scvtf fixed");
printf("\n 0x%08x = %u; 0x%08x = %u;\n", 0xFFFFFF1F, 0xFFFFFF1F, 0xFFFFFF10, 0xFFFFFF10);
initTGT();
ucvtf4V(TargetMEM);
dumpTGT("ucvtf");
printf("\n 0x%08x >>4 %d; 0x%08x >>4 %d;\n", 0x21, 0x2, 0x201, 0x20);
printf(" 0x%08x >>4 %u; 0x%08x >>4 %u;\n", 0xFFFFFF1F, 0xFFFFFF1, 0xFFFFFF10, 0xFFFFFF1);
initTGT();
ucvtfx4V(TargetMEM);
dumpTGT("ucvtf fixed");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 simdSCVTF.c simdSCVTF.s $ ./a.out
以下は標準出力に現れた結果です。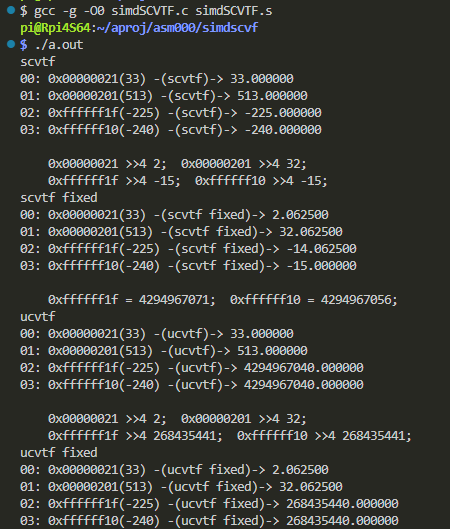
まあ、変換できているのは分かるが、たった2命令でこのメンドさ。残っている者どもを考えると、愚痴りたくなる「命令多過ぎA64」