ついにA64のSIMD即値シフト命令、8回を費やし今回にて完了であります。命令数トンデモなかったデス。今回は残るナロー化(ソース要素のビット幅の半分の結果を得る)右シフト一族のうち、サチュレーションやらラウンディングやら複数重なるような複雑な奴らです。でもね、順番にやっているうちに慣れました?どんとこいっと。ホントか?
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
今回練習するナロー化一族
今回練習する命令共は以下の通りです。
右シフト(Rgt)で、ナロー(Nar)で、サチュレーション(Sat、飽和)までは共通してます。また通例のとおり、末尾に2がつく命令は、ナロー化されてビット数が半減した結果をSIMDレジスタの上位に格納するもの。2がつかないものは下位です。
差異はといえば以下のごとし。
-
- ソースを符号付データとみて即値シフト後飽和させた後丸める SQRSHRNとSQRSHRN2
- ソースを符号無データとみて即値シフト後飽和させた後丸める UQRSHRNとUQRSHRN2
- ソースを符号付データとみて即値シフト後、符号無数の範囲で飽和させるSQSHRUNとSQSHRUN2
- ソースを符号付データとみて即値シフト後、符号無数の範囲で飽和させ、丸めも行うSQRSHRUNとSQRSHRUN2
3番と4番などは符号付なんだか符号無なんだかハッキリしろい、と言いたくなる命令です。8回も似たようなことを繰り返してきました。すっかり慣れました。でも忘却力の年寄は直ぐに忘れるケド。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。当然SIMD要素幅はいろいろとれるのですが、いつもの手抜きでソース要素のビット幅はワード(32bit)のみです。よってデスティネーション要素のビット幅はハーフワード(16bit)のみとなります。
.globl sqrshrn4V, sqrshrn24V, uqrshrn4V, uqrshrn24V, sqshrun4V, sqshrun24V, sqrshrun4V, sqrshrun24V
.text
.balign 4
sqrshrn4V:
ld1 {v0.4S, v1.4S}, [x0]
sqrshrn v0.4H, v1.4S, #8
st1 {v0.4S}, [x0]
ret
sqrshrn24V:
ld1 {v0.4S, v1.4S}, [x0]
sqrshrn2 v0.8H, v1.4S, #8
st1 {v0.4S}, [x0]
ret
uqrshrn4V:
ld1 {v0.4S, v1.4S}, [x0]
uqrshrn v0.4H, v1.4S, #8
st1 {v0.4S}, [x0]
ret
uqrshrn24V:
ld1 {v0.4S, v1.4S}, [x0]
uqrshrn2 v0.8H, v1.4S, #8
st1 {v0.4S}, [x0]
ret
sqshrun4V:
ld1 {v0.4S, v1.4S}, [x0]
sqshrun v0.4H, v1.4S, #8
st1 {v0.4S}, [x0]
ret
sqshrun24V:
ld1 {v0.4S, v1.4S}, [x0]
sqshrun2 v0.8H, v1.4S, #8
st1 {v0.4S}, [x0]
ret
sqrshrun4V:
ld1 {v0.4S, v1.4S}, [x0]
sqrshrun v0.4H, v1.4S, #8
st1 {v0.4S}, [x0]
ret
sqrshrun24V:
ld1 {v0.4S, v1.4S}, [x0]
sqrshrun2 v0.8H, v1.4S, #8
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。今回も、扱うデータが符号付でも符号無でもCのデータ型などは踏みつぶしてしまって全てuint32_t型にしてあります。符号付きか符号無かは各自HEX表記を見て理解する、ということで。それどころか結果は「ナロー」なので32ビット幅表示のMSB側、LSB側に各16ビットの結果が詰まっています。要素の分離も頭の中でね。
#include <stdio.h>
#include <stdint.h>
#include <math.h>
#define MAXMEM (8)
uint32_t TargetMEM[MAXMEM];
extern void sqrshrn4V(uint32_t *);
extern void sqrshrn24V(uint32_t *);
extern void uqrshrn4V(uint32_t *);
extern void uqrshrn24V(uint32_t *);
extern void sqshrun4V(uint32_t *);
extern void sqshrun24V(uint32_t *);
extern void sqrshrun4V(uint32_t *);
extern void sqrshrun24V(uint32_t *);
void initTGT() {
TargetMEM[0] = 0x11111111;
TargetMEM[1] = 0x11111111;
TargetMEM[2] = 0x11111111;
TargetMEM[3] = 0x11111111;
TargetMEM[4] = 0x00345678;
TargetMEM[5] = 0x00BCDEF0;
TargetMEM[6] = 0xFFCC008D;
TargetMEM[7] = 0xFFFF008E;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i<4; i++) {
printf("%02d: %08x\n", i, TargetMEM[i]);
}
}
int main(void) {
initTGT();
sqrshrn4V(TargetMEM);
dumpTGT("sqrshrn v0.4H, V1.4S, #8");
initTGT();
sqrshrn24V(TargetMEM);
dumpTGT("sqrshrn2 v0.8H, V1.4S, #8");
initTGT();
uqrshrn4V(TargetMEM);
dumpTGT("uqrshrn v0.4H, V1.4S, #8");
initTGT();
uqrshrn24V(TargetMEM);
dumpTGT("uqrshrn2 v0.8H, V1.4S, #8");
initTGT();
sqshrun4V(TargetMEM);
dumpTGT("sqshrun v0.4H, V1.4S, #8");
initTGT();
sqshrun24V(TargetMEM);
dumpTGT("sqshrun2 v0.8H, V1.4S, #8");
initTGT();
sqrshrun4V(TargetMEM);
dumpTGT("sqrshrun v0.4H, V1.4S, #8");
initTGT();
sqrshrun24V(TargetMEM);
dumpTGT("sqrshrun2 v0.8H, V1.4S, #8");
return 0;
}
実機実行結果の確認
以下のようにして ビルドして実行しています。
$ gcc -g -O0 simdSFTImm8.c simdSFTImm8.s $ ./a.out
標準出力に現れた結果を比較しやすいように上下2段x横4列にしてならべてみました。差がでる「ポイント」のうち飽和関係に青、丸め関係に赤をつけてあります。微妙なような、そうではないような。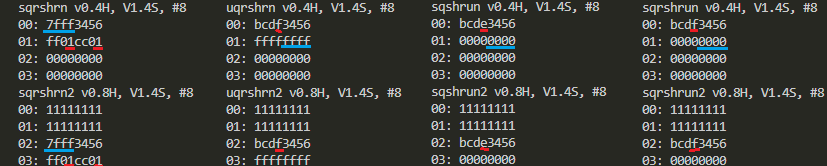
淡々と練習したら、淡々と完了してしまったな。