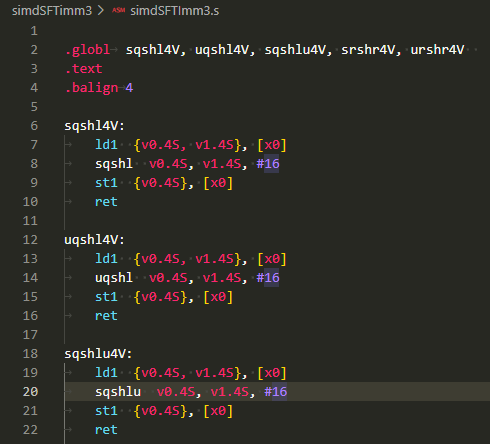
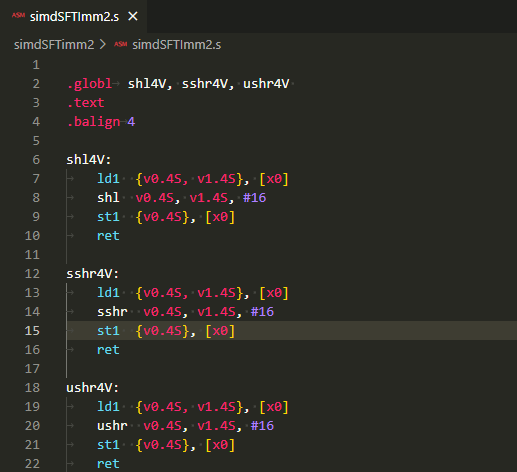
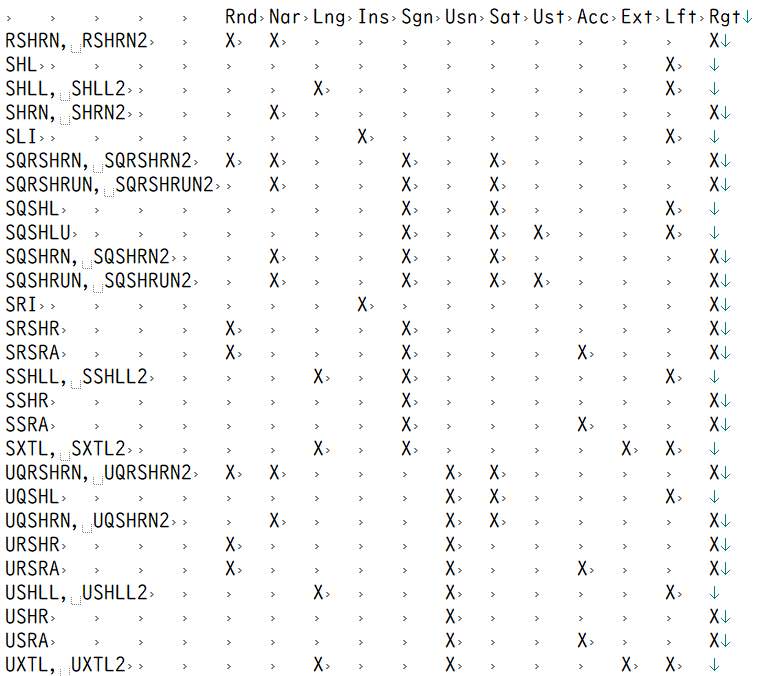
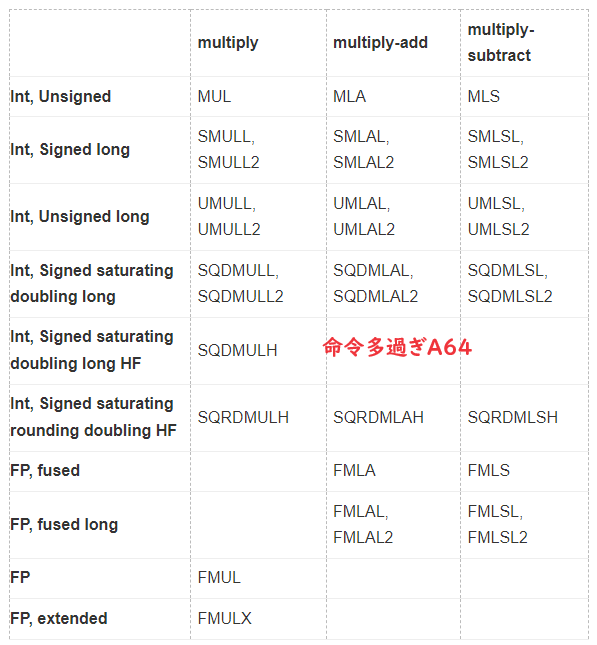
SIMDの即値シフト命令の練習4回目。今回は勝手命名「即値シフトのアキュムレート系」を練習。即値シフト後の値をデスティネーションレジスタの値に加えるものです。命令を並べてみるとこの一族は「直交的」です。A64にはめずらしい対称性?ただし、アキュムレート一族は右シフトのみ。根本的なところで対称性は破れている?違うか。
“ぐだぐだ低レベルプログラミング(168)ARM64(AArach64)SIMD即値シフト4” の続きを読む
ぐだぐだ低レベルプログラミング(168)ARM64(AArach64)SIMD即値シフト4