前回のSIMD命令はソースオペランド1個をとって計算結果をデスティネーション1個に格納するパターン。このパターンの一番シンプルなものはMOVですな。勿論、SIMD(ベクトル)命令にもMOVというニーモニックは「有り」です。しかし、エイリアスが久しぶりの登場。「MOVはエイリアスなので実はMOV命令など無い」、なんと。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
MOV(ベクトル)命令
冒頭に書いたとおりで、MOVというニーモニックのオペランドにベクトル(SIMD)レジスタをおくことで、ベクトルレジスタ間の転送を表現することが可能です。しかしMOV命令の実体があるわけでなく、その実体は
ORR 転送先ベクトルレジスタ, 転送元ベクトルレジスタ, 転送元ベクトルレジスタ
という2ソース、1デスティネーションのOR命令です。ソースオペランドを同じにすればMOVしたように見えると。A64の「いつもの」エイリアスです。
ベクトルレジスタの指定のため、やはり何かしらのエレメント指定が必要です。でも「ぶっちゃけ、浮動小数だろうと整数だろうと」MOVはMOVなので。エレメントの指定は以下のバイトのみです。
-
- 8B
- 16B
8Bは、64ビット幅のベクトル処理用で、フル幅の128ビット幅の場合は16Bです。今回実験してみているフル幅の転送は以下のような感じです。データ的には例によって単精度浮動小数点数を詰めてあるのですが、MOVそのものは16Bでやってます。転送するだけなので右から左?

しかし、ベクトルレジスタ間の転送には異なるパターンもあります。ベクトルレジスタ全体ではなく、ベクトルレジスタの一つのエレメントのみを他のベクトルレジスタのエレメントに転送する以下のようなパターンです。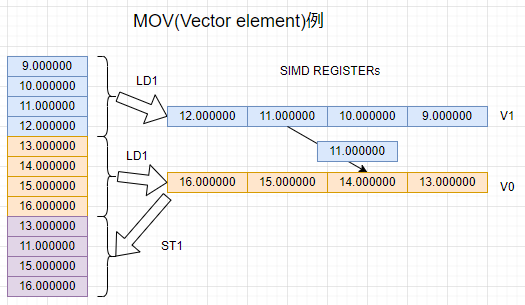
オペランドを指定するときに、v1.S[2]みたいなエレメント指定をすれば上記のようなエレメント転送も可能です。しかし、ここでもまた「MOV命令」の実体は実はINSという命令です。MOVはどこまで行ってもエイリアス。INS系?のエレメント操作についてはまた次回の予定っす。とりあえずMOVというエイリアス表記で、ベクトルレジスタのエレメント転送ができると。なおこちらの場合、エレメントのビット幅指定必須です。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの、関数プロローグ、エピローグ無の被テスト関数のソースが以下に。以下のソースではエイリアス表記でMOVと書いてますが、アセンブラはそれを飲み込んで裏で本来の命令を生成してくれとるようです。
.globl movv, movve
.text
.balign 4
movv:
ld1 {v1.16B}, [x0], #16
mov v0.16B, v1.16B
st1 {v0.16B}, [x0]
ret
movve:
ld1 {v1.4S}, [x0], #16
ld1 {v0.4S}, [x0], #16
mov v0.S[1], v1.S[2]
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。上の例に記したとおり、メモリにテキトーな値を詰め込んでおいて、ベクトルMOVして結果をストア、今度はエレメントMOVして結果をストア。そのビフォーアフターをメモリダンプして確かめるコードです。
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (20)
float TargetMEM[MAXMEM];
extern void movv(float *);
extern void movve(float *);
void initTGT(float c) {
for (int i=0; i < MAXMEM; i++) {
TargetMEM[i] = c * (i+1);
}
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < MAXMEM; i++) {
printf("%d: %f\n", i, TargetMEM[i]);
}
}
int main(void) {
initTGT(1.000f);
dumpTGT("Before mov");
movv(TargetMEM);
dumpTGT("After mov vector");
movve(&TargetMEM[8]);
dumpTGT("After mov vector element");
return 0;
}
実験結果
以下のようにしてビルドして実行しています。
$ gcc -g -O0 fmovv.c fmovv.s $ ./a.out
標準出力に「ダラダラ」現れる結果を折りたたんで、見やすいように関係個所を枠で囲って紐づけてみましたです。
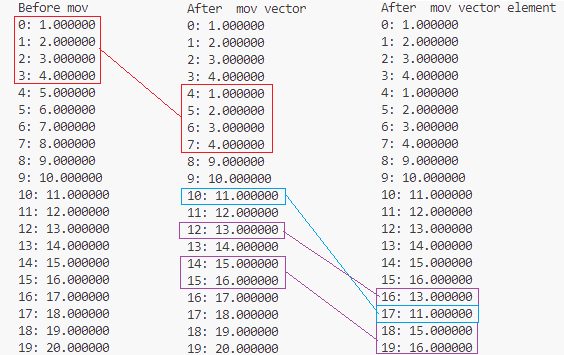 思ったとおりに転送(MOV)されているようです。でもね、SIMD演算するときは別パターンの転送も欲しいところ。また次回か。
思ったとおりに転送(MOV)されているようです。でもね、SIMD演算するときは別パターンの転送も欲しいところ。また次回か。