何度も書いてますが、A64の命令、特にSIMD命令多すぎ。SIMDで普通の足し算だのはメンドイのでほぼ省略、ユニークな奴らだけ練習してます。前回はニュートン・ラフソン法にてご利益があるらしい命令をやりました。今回は多項式っす。ここを掘っていくと群、環、体などという者どもが飛び出してくること必定。ヤバイ命令だよ。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
PMULとは何ぞや?
さて、今回練習してみるのはPMUL命令です。頭のPが分からんけどMULなので掛け算ということはバレバレです。御本家 Arm Developerサイトの以下のページへ飛べば命令の説明が見つかります。
普通は命令の解説ページを読めば、どんな命令なのか明らかになるもんです。前回に続き、今回も上記のページを読んでもサッパリです。その自覚は「中の人」もあるみたいでデータシートを読めとあります。結局、いつも眺めているデータシートを読むしかないのね。。。さて、データシートを読むと分かるのが、この命令
Polynomial arithmetic over {0, 1}
を計算するための命令です。ぶっちゃけ、電気電子系でよく出てくるのがCRCなどの計算に使う多項式デス。ネットで日本語のページを漁ってみたところでは、zuruyasumineko2002’s blog様の以下のページが分かりやすかったデス。
位数2の有限体 ( GF(2) ) での1変数多項式の計算 (その1)
有限体(GF(2))だと、やっぱり「体」でてくるのね。。。ちゃんと代数学勉強してないから、群環体とか言われるとビビルのよ。
例題の答えはMaxima様にお願い
しかし、実際に計算できないことには実験もままなりません。2を法とする多項式の掛け算など間違わずに遂行できる自信はこの老人にありません。そこで別シリーズ「忘却の微分方程式」にていつもお世話になっているMaxima様におすがりすることにいたしました。
-
- wxMaxima 22.04.0、GUIフロントエンドです。
- Maxima 5.46.0、定番の数式処理ソフトウエアです。これさえあれば数学出来なくても「工学部レベルの数学」ならなんとかなる?
なお、今回使用したのはMaximaの多項式関係の関数です。いつもお世話になっておりますMaxima日本語マニュアル様の以下のページに記述があります。
まずは、係数値をベクトルで与えて多項式として表現するために makePOLY(v)という関数を定義しておきました。手でべき乗記述すれば不要だけれどメンドイし。
そして多項式2つを乗じる(ただし、2を法とする)関数 mulPOLY()を定義。そして求まった多項式を係数ベクトルに直すためのpoly2Vec()も定義。

上記の関数を定義した後、サンプルデータを作ってみます。まずは入力となる2つの多項式P0とP1をmakePOLY()で生成。その後P0とP1を乗じてP2(2を法)を得る。最後はまた係数ベクトル化っと。
上記の結果をかいつまむと、
多項式P0(係数ベクトル表現で0x09)と多項式P1(係数ベクトル表現で0x0d)を乗じるとそのお答えは多項式P2(係数ベクトル表現で0x65)
ということになりました。SIMDなのに1例かい。手抜き。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。今回のPMULは整数だけなのですが、SIMDレジスタの半分しか使わないモードで使ってます。だって上記のようにテストパターンが手抜きだから。
.globl pmul8V
.text
.balign 4
pmul8V:
ld1 {v1.8B, v2.8B}, [x0], #16
pmul v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。これまたいつもの通りの手抜き。操作前後のメモリをダンプしているだけのもの。
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (24)
uint8_t TargetMEM[MAXMEM];
extern void pmul8V(uint8_t *);
void initTGT(uint8_t c1, uint8_t c2) {
for (int i=0; i < 8; i++) {
TargetMEM[i] = c1;
}
for (int i=8; i < 16; i++) {
TargetMEM[i] = c2;
}
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < MAXMEM; i++) {
printf("%02d: %02x\n", i, TargetMEM[i]);
}
}
int main(void) {
initTGT(0x09, 0x0d);
dumpTGT("Before pmul8V");
pmul8V(TargetMEM);
dumpTGT("After pmul8V");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 pmul.c pmul.s $ ./a.out
標準出力に「ダラダラ」現れる結果を折りたたんで、見やすいように結果を赤枠で囲ってみました。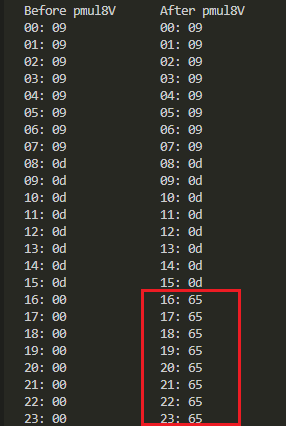
0x09と0x0dを掛けたら結果は0x65だな。Maxima様で求めた通りじゃよ。