前回は、Pthreadを用いた実験プログラムを最適化したものとしないもの、RPi3とRPi4でスレッド数を変えて走らせて比べました。今回はそのときのプログラムを「無理やり」OpenMP化してみました。スレッド数が同じなら、PthreadでもOpenMPでも似たような結果でないかい、と思いましたが、結果は微妙。こだわる人はコダワル?
※ソフトな忘却力 投稿順 index はこちら
「プロ」の人は、OpenMPとか、MPIとかのことをよ~くご存じだと思いますので、こんな実験は不要。しかし、普段OpenMPとかに無縁な私には「とりあえずやってみる」のも良かろうと。OpenMPのご本家のウエブサイトのURLは以下に。
やはり日本語の入門資料はありがたい、ということで東京大学様の以下の資料も嬉しいです。
さて、前回Pthreadでプログラムを書いて走らせました。処理の内容は配列に詰まった数値の計算を繰り返すだけの単純なものです。Pthreadで書くよりはOpenMPとかの方が処理の実体にあっているじゃないか(でも本命はCUDA)、と思っていました。素人の勝手な考えだと、
-
- Pthreadは、異なる仕事もおまかせできる。同じ仕事を多数に分割してやるときにも使えるけれど、そのときは仕事の分割を自分で考えないとならないのでチト面倒。
- OpenMPは、同じような仕事を多数でやるときに向く。仕事の分割(ぶっちゃけForループの並列化)は、勝手によきに計らってくれるので楽。とても楽。
まあ、一長一短、向き不向きを考えて使うべきかと思います。
使用したCMakeLists.txt
例によってPC上のVSCodeから Raspberry Pi 4機にリモートログインして、コードを作成しています。ビルドツールは CMake 、ツールチェーンは gcc 8.3.0 です。例によって VSCode拡張の CMakeツールの自動生成機能を使い、CMakeLists.txtを自動作成してもらいました。多分、CMakeに慣れている人であれば、Cmakeのfind_packageでOpenMPを見つけさせて、自動でフラグを設定させるような技が使えるのだと思います。しかし、CMake素人の自分は、自分で設定しないと安心できないので、とりあえず以下のように手書きでフラグを追加してみました。
cmake_minimum_required(VERSION 3.0.0)
project(openmpTst
VERSION 0.1.0
LANGUAGES C)
set(CMAKE_C_FLAGS "-fopenmp")
set(CMAKE_C_FLAGS_DEBUG "-Wall -O0 -g")
set(CMAKE_C_FLAGS_RELEASE "-Wall -O3")
include(CTest)
enable_testing()
add_executable(openmpTst main.c)
set(CPACK_PROJECT_NAME ${PROJECT_NAME})
set(CPACK_PROJECT_VERSION ${PROJECT_VERSION})
include(CPack)
進歩が無いねえ、まったく。
使用したソース
元々Pthread用に書いたものですが、前回のコードを改めて眺めてみると、問題がソコかしこにあることに気づきました。今になってすみません。まあ、動いているからいいことにしよう。前に戻って直していると先に進まないので、踏みつぶして進めてしまいました。こんな感じ。
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <omp.h>
#include <time.h>
#define NSET (2*3*2*5*7*2*3*11*13*2)
#define NDATAMAX (2048)
float *dataArray1;
float *dataArray2;
float *resultArray;
int nData = 1;
int nLoop = 100;
int seed = 123;
int nMP = 0;
int getParam(char* oa) {
int temp;
errno = 0;
temp = strtol(oa, (char **)NULL, 10);
if (errno == 0) {
return temp;
} else {
perror("ERROR: params.");
exit(EXIT_FAILURE);
}
}
void setupArrays() {
int numberOfData = NSET * nData;
dataArray1= (float*)malloc(numberOfData * sizeof(float));
if (dataArray1 == NULL) {
perror("ERROR: Allocate dataArray1");
exit(EXIT_FAILURE);
}
dataArray2= (float*)malloc(numberOfData * sizeof(float));
if (dataArray1 == NULL) {
perror("ERROR: Allocate dataArray2");
exit(EXIT_FAILURE);
}
resultArray= (float*)malloc(numberOfData * sizeof(float));
if (dataArray1 == NULL) {
perror("ERROR: Allocate resultArray");
exit(EXIT_FAILURE);
}
srand(seed); // Same seed will give same sequence.
for (int i=0; i < numberOfData; i++) {
dataArray1[i] = (float)rand() / 10000. + 0.5f;
dataArray2[i] = (float)rand() / 10000. + 0.7f;
}
}
void freeArrays() {
free(dataArray1);
free(dataArray2);
free(resultArray);
}
float getTimeFloat() {
struct timespec temp;
clock_gettime(CLOCK_MONOTONIC, &temp);
return ( (float)temp.tv_sec + (float)(temp.tv_nsec)/1e9 );
}
float testDriver() {
float startT, endT;
startT = getTimeFloat();
int blkSIZE = NSET * nData;
for (int j=0; j < nLoop; j++) {
#pragma omp parallel
{
if (j==0) {
nMP = omp_get_num_threads();
}
// OMP thread private
float temp1 = 0.0;
float temp2 = 0.0;
float temp3 = 0.0;
int counter;
int *ptr = &counter;
*ptr = 0;
#pragma omp for
for (int idx=0; idx < blkSIZE; idx++) {
temp1 = dataArray1[idx] - dataArray2[idx];
temp2 = dataArray1[idx] + dataArray2[idx];
if (temp2 > temp1) {
temp1 = temp1 / temp2;
} else {
temp1 = temp2 / temp1;
}
if (dataArray1[idx] > dataArray2[idx]) {
temp3 = dataArray1[idx] * temp1;
} else {
temp3 = dataArray2[idx] * temp2;
}
resultArray[idx] = temp3 / temp2;
*ptr += 1; //counter
}
}
#pragma omp barrier
}
endT = getTimeFloat();
return endT - startT;
}
int main(int argc, char *argv[]) {
int opt;
int nSleep = 2;
int flagA = 0;
int nTrial = 3;
float result;
while((opt = getopt(argc, argv, "aN:R:L:S:")) != -1) {
switch (opt) {
case 'a':
flagA = 1;
break;
case 'N':
nData = getParam(optarg);
if (nData > NDATAMAX) {
perror("ERROR: Data, over the limit.");
exit(EXIT_FAILURE);
}
break;
case 'R':
nTrial = getParam(optarg);
break;
case 'L':
nLoop = getParam(optarg);
break;
case 'S':
seed = getParam(optarg);
break;
default:
fprintf(stderr, "Usage: %s [-a][-N nData][-R nTrial][-L nLoop][-S seed]\n", argv[0]);
exit(EXIT_FAILURE);
}
}
printf("OpenMP test runner: nData=%d, nTrial=%d, nLoop=%d\n", nData, nTrial, nLoop);
setupArrays();
printf("Start TEST\n");
for (int idx=0; idx < nTrial; idx++) {
result = testDriver();
printf(",%12.6e",result);
}
printf("\n");
printf("# of threads, used: %d\n", nMP);
printf("End of TEST.\n");
sleep(nSleep);
if (flagA) {
for (int i=0; i< nData; i++) {
printf("%d: %f\n",i, resultArray[i]);
}
}
freeArrays();
printf("End of Execution.\n");
exit(EXIT_SUCCESS);
}
ホントにこんなんでいいのかな~と思いつつ、これまた動いているからいいか、という塩梅。いつもそれだな。
実験結果
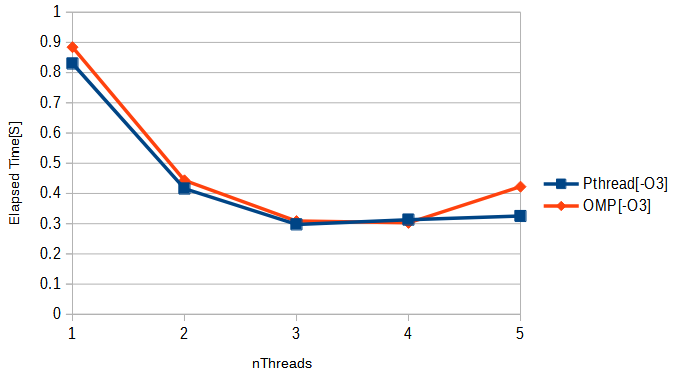
基本、スレッド数が同じなら同じような結果じゃね、という予想通りであります。ただ、スレッド数3とスレッド数4の「一番性能が良いあたり」で微妙な優劣あり。ただ、被テストのコードの性質にもよりけりだと思うので、この微妙な差でどうこう言えるようなものでもないだろうと(お茶を濁して済ませているな。)
そうして測定した結果と前回の結果を1枚のグラフにしたものを先頭のアイキャッチ画像に掲げました。
次、CUDAと比べてようやくレベチになるのか?